|
ГЛАВНАЯ
> Вернуться к содержанию
Вопросы безопасности
Правильная ссылка на статью:
Плешакова Е.С., Гатауллин С.Т., Осипов А.В., Романова Е.В., Самбуров Н.С.
Эффективная классификация текстов на естественном языке и определение тональности речи с использованием выбранных методов машинного обучения
// Вопросы безопасности.
2022. № 4.
С. 1-14.
DOI: 10.25136/2409-7543.2022.4.38658 EDN: UPWMCV URL: https://nbpublish.com/library_read_article.php?id=38658
Эффективная классификация текстов на естественном языке и определение тональности речи с использованием выбранных методов машинного обучения
Плешакова Екатерина Сергеевна
ORCID: 0000-0002-8806-1478
кандидат технических наук
доцент, кафедра Информационной безопасности, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, пр-д 4-Й вешняковский, 12к2, корпус 2
Pleshakova Ekaterina Sergeevna
PhD in Technical Science
Associate Professor, Department of Information Security, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th Veshnyakovsky Ave., 12k2, building 2

|
espleshakova@fa.ru
|
|
 |
Другие публикации этого автора
|
|
Гатауллин Сергей Тимурович
кандидат экономических наук
декан факультета «Цифровая экономика и массовые коммуникации» Московского технического университета связи и информатики; ведущий научный сотрудник Департамента информационной безопасности Финансового университета при Правительстве РФ
111024, Россия, г. Москва, ул. Авиамоторная, 8А
Gataullin Sergei Timurovich
PhD in Economics
Dean of "Digital Economy and Mass Communications" Department of the Moscow Technical University of Communications and Informatics; Leading Researcher of the Department of Information Security of the Financial University under the Government of the Russian Federation
8A Aviamotornaya str., Moscow, 111024, Russia
|
|
stgataullin@fa.ru
|
|
|
Другие публикации этого автора
|
|
Осипов Алексей Викторович
кандидат физико-математических наук
доцент, Департамент анализа данных и машинного обучения, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, ул. 4-Й вешняковский, 4, корпус 2
Osipov Aleksei Viktorovich
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th veshnyakovsky str., 4, building 2
|
|
avosipov@fa.ru
|
|
|
Другие публикации этого автора
|
|
Романова Екатерина Владимировна
кандидат физико-математических наук
доцент, кафедра Департамент анализа данных и машинного обучения, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, пр-кт Ленинградский, 49/2
Romanova Ekaterina Vladimirovna
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 49/2 Leningradsky Ave.
|
|
EkVRomanova@fa.ru
|
|
|
Другие публикации этого автора
|
|
|
Самбуров Николай Сергеевич
студент, кафедра Департамент анализа данных и машинного обучения, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, пр-кт Ленинградский, 49/2
Samburov Nikolai Sergeevich
Student, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 49/2 Leningradsky Ave.
|
|
ncsamburov@mail.ru
|
|
|
|
DOI: 10.25136/2409-7543.2022.4.38658
EDN: UPWMCV
Дата направления статьи в редакцию:
23-08-2022
Дата публикации:
30-12-2022
Аннотация:
В настоящее время генерируется огромное количество текстов, и существует острая необходимость организовать их в определенной структуре, для выполнения классификации и правильного определения категорий. Авторы подробно рассматривают такие аспекты темы как классификация текстов на естественном языке и определение тональности текста в социальной сети Twitter. Использование социальных сетей помимо многочисленных плюсов, несет и негативный характер, а именно пользователи сталкиваются с многочисленными киберугрозами, такими как утечка персональных данных, кибербуллинг, спам, фейковые новости. Основной задачей анализа тональности текста является определение эмоциональной наполненности и окраски, что позволит выявить негативно окрашенную тональность речи. Эмоциональная окраска или настроение являются сугубо индивидуальными чертами и, таким образом, несут потенциал в качестве инструментов идентификации. Основная цель классификации текста на естественном языке состоит в том, чтобы извлекать информацию из текста и использовать такие процессы, как поиск, классификация с применением методов машинного обучения. Авторы отдельно выбрали и сравнили следующие модели: логистическая регрессия, многослойный перцептрон, случайный лес, наивный байесовский метод, метод K-ближайших соседей, дерево решений и стохастический градиентный спуск. Затем мы протестировали и проанализировали эти методы друг с другом. Экспериментальный вывод показывает, что применение скоринга TF-IDF для векторизации текста улучшает качество модели не всегда, либо делает это для отдельных метрик, вследствие чего уменьшается показатель остальных метрик для той или иной модели. Наилучшим методом для выполнения цели работы является Стохастический градиентный спуск.
Ключевые слова:
искусственный интеллект, машинное обучение, нейронные сети, персональные данные, киберпреступления, социальные сети, киберугрозы, классификация текстов, тональность текста, спам
Abstract: Currently, a huge number of texts are being generated, and there is an urgent need to organize them in a certain structure in order to perform classification and correctly define categories. The authors consider in detail such aspects of the topic as the classification of texts in natural language and the definition of the tonality of the text in the social network Twitter. The use of social networks, in addition to numerous advantages, also carries a negative character, namely, users face numerous cyber threats, such as personal data leakage, cyberbullying, spam, fake news. The main task of the analysis of the tonality of the text is to determine the emotional fullness and coloring, which will reveal the negatively colored tonality of speech. Emotional coloring or mood are purely individual traits and thus carry potential as identification tools. The main purpose of natural language text classification is to extract information from the text and use processes such as search, classification using machine learning methods. The authors separately selected and compared the following models: logistic regression, multilayer perceptron, random forest, naive Bayesian method, K-nearest neighbor method, decision tree and stochastic gradient descent. Then we tested and analyzed these methods with each other. The experimental conclusion shows that the use of TF-IDF scoring for text vectorization does not always improve the quality of the model, or it does it for individual metrics, as a result of which the indicator of the remaining metrics for a particular model decreases. The best method to accomplish the purpose of the work is Stochastic gradient descent.
Keywords: artificial intelligence, machine learning, neural networks, personal data, cybercrimes, social network, cyber threats, classification of texts, the tonality of the text, spam
Статья подготовлена в рамках государственного задания Правительства Российской Федерации Финансовому университету на 2022 год по теме «Модели и методы распознавания текстов в системах противодействия телефонному мошенничеству» (ВТК-ГЗ-ПИ-30-2022).
Введение
Классификация текста в последние годы приобрела огромную популярность, и нашла применение этой технологии в различных приложениях, таких как классификация эмоций из текста, классификация спама и многие другие. С появлением социальных сетей люди стали чаще выражать свои эмоции посредством своей деятельности в социальных сетях. Люди передают свои эмоции через сообщения в социальных сетях, такие как комментарии к своим или чужим сообщениям, обзоры, блоги. Машина может обрабатывать данные разных типов [1-3]. Например, с фото и видео работают такие сервисы как YouTube и TikTok. Алгоритмы анализируют ваши действия: в расчет берется как тема и направленность видео, язык, и то насколько полно вы смотрите видео. Машина анализирует эти данные, и на их основе рекомендует новые видео, которые вам скорее всего понравятся. Также, при помощи других признаков машину можно обучить распознавать личность на видео или фото. Такие технологии широко используются по всему миру для обеспечения безопасности: предотвращения или расследования преступлений.
По схожему принципу работают все современные музыкальные стриминговые сервисы, например Spotify и Яндекс.Музыка, которые содержат раздел «Рекомендации». Машина анализирует настроение песни, её жанр, язык и популярность.
Многими производителями товаров и услуг также используется машинное обучение для сбора и анализа обратной связи от их клиентов, чтобы в дальнейшем усовершенствовать свой продукт и выгодно выделяться на фоне конкурентов. В таких случаях обрабатывается текст отзывов, а также другие факторы, например был ли оформлен возврат. Одним из других применений машинного обучения в задачах классификации текстов является машинный перевод естественных языков [4-5].
В данной работе обучение моделей осуществлялось на текстовых данных публикаций в социальной сети Twitter на тему “COVID-19”. В данной работе авторы рассматривают проблему определения тональности текста. Основной задачей анализа тональности текста является определение эмоциональной наполненности и окраски.
Для выполнения задач классификации текстов существует наиболее подходящих методы: логистическая регрессия, многослойный перцептрон, случайный лес, наивный байесовский метод, метод К-ближайших соседей, дерево решений, стохастический градиентный спуск.
Оценка моделей происходит при помощи различных показателей - достоверность предсказаний, точность, полнота и F-оценка. Также, одной из задач является применение технологий по улучшению качества моделей.
Классификация текста
Задача определения тональности текста идентична другим задачам классификации текстов. Машина анализирует текст, выделяя ключевые слова, их смысловую нагрузку и значимость для определения настроения, на основании чего делает свой вывод. Тональность текстов можно разделить на три основные группы - негативная, позитивная и нейтральная, где последняя означает отсутствие эмоциональной окраски у текста. Для решения поставленной задачи был выбран набор данных «Coronavirus tweets NLP» [6-7].
Так как при классификации текстов машина распознает ключевые слова, целесообразным будет составить «облако слов» для текстов всех публикаций датасета.
Для корректного обучения модели и получения чистых результатов необходимо выполнить очистку текста от лишних символов и бессмысленных слов. Первым этапом является удаление знаков препинания, цифр, символов «@» и «#», а также текста протокола HTTP. Существенную часть бессмысленных слов составляют так называемые «стоп-слова».
После очистки обрабатываемого текста составляем словарь для дальнейших исследований
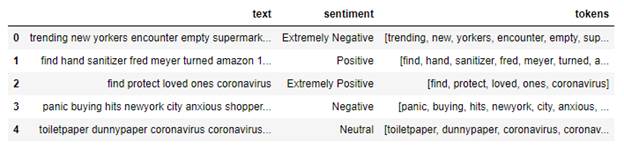
Рис. 1. Токенизация текста
Составляем «облако слов» для очищенных данных:

Рис. 2. «Облако слов» для очищенных данных
Для упрощения дальнейшей классификации классы из столбца «Настроение» заменяются на числовые значения от 1 до 5, где 1- «Крайне негативно», а 5- «Крайне позитивно»:
Обучение моделей. Разделение выборки и векторизация текста.
Следующая задача состоит в том, чтобы закодировать слова в предложениях числовыми представлениями. Для этого можно составить словарь из всех уникальных слов, которые встречаются в датасете и ассоциировать каждое из слов в предложении с этим словарем. В таком случае каждое предложение нужно представить в виде списка, длина которого будет равна размеру словаря уникальных слов (53553 слов в нашем случае), и в каждом индексе такого списка будет храниться, сколько раз то или иное слово встречается в этом предложении. Такой метод называется «Мешок слов» [8]. Модель мешка слов (модель BoW) представляет собой сокращенное и упрощенное представление текстового документа из выбранных частей текста на основе определенных критериев, таких как частотность слов. Размер обучающей выборки составил 32925 элементов, тестовой – 8232.
Логистическая регрессия
Одним из самых простых и распространенных инструментов в классификации текстов является логистическая регрессия. Логистическая регрессия подпадает под алгоритм контролируемой классификации [9]. Этот алгоритм приобрел важное значение в последнее время, и его использование значительно возросло.
Время обучения модели составило 16.6 секунд. Показатели метрики являются плохими, 57% точности предсказаний говорит о том, что модель ошиблась почти в половине случаев.
По полученным результатам мы видим, что наихудшие показатели при предсказывании положительных и отрицательных публикаций.
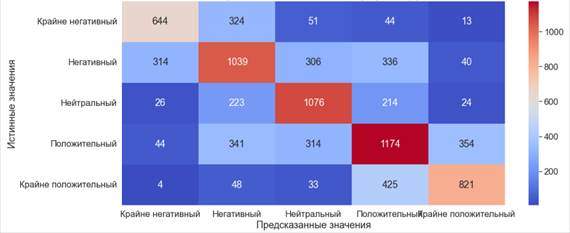
Рис. 3. Матрица ошибок. Логистическая регрессия (5)
Полученный результат возник из-за того, что логистической регрессии сложно работать в случаях, когда целевая содержит больше, чем 2 значения. Попробуем уменьшить количество классов и сравнить результаты. Для этого объединим «Крайне положительные» и «Положительные» публикации под одну метку. Такую же операцию проделаем с негативными публикациями и зададим градацию от 0 до 2, где 0 – негативные отзывы, а 2 – позитивные.
После изменения меток распределение классов выглядит следующим образом:
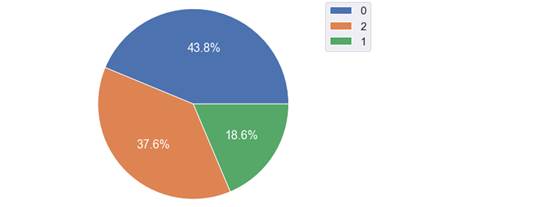
Рис. 4. Распределение классов после объединения меток
После объединения проведем повторное обучение. Результаты значительно улучшились (хорошим показателем считается точность ≈80%). Время обучения составило 9.7 секунд. Подробный отчет показал, что модель лучше всего предсказывает положительные публикации.
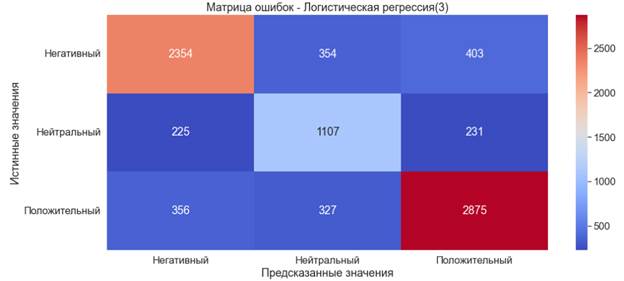
Рис. 5. Матрица ошибок. Логистическая регрессия (3)
Так как в работе рассматривается классификация текстов, некоторые слова могут иметь большее значение для распределения текста в ту или иную категорию. Эту проблему решает метод TF-IDF (Term Frequency – Inverse Document Frequency) для векторизации текста. Техника TF-IDF обычно используется для извлечения признаков и для определения терминов, которые неоднократно встречаются в тексте. TF-IDF не появляются повторно в целом для каждой коллекции документов. Выбор связанных ключевых слов и определение метода используются для кодирования этих ключевых слов в контролируемом машинном обучении. Эти ключевые слова могут иметь огромное влияние на возможности методов классификации для извлечения наилучшего шаблона. Данный метод определяет то, насколько часто слово встречается в различных документах и на основе этого присуждает словам значимость для классификации [10]. Для этого применим TfidfVectorizer поверх уже существующего «Мешка слов»:
Теперь, для примера, построим новую логистическую регрессию и сравним результаты. Результат показывает что, показатели выросли незначительно, примерно на 1%. При обучении дальнейших моделей будет использоваться как обычный «Мешок слов», так и с применением TF-IDF.
Многослойный перцептрон
Наиболее традиционным типом архитектуры нейронной сети является сеть многослойного персептрона (MLP). Это класс искусственных нейронных сетей с прямой связью, состоящий как минимум из трех слоев узлов: входного слоя, скрытого слоя и выходного слоя. Персептрон — это блок, который получает один или несколько входных данных (значения независимых переменных в модели), подвергает каждый вход уникальному линейному математическому преобразованию, включающему умножение на весовой параметр, суммирование взвешенных входных данных, добавление параметра смещения и обработку. результирующее значение функции активации, которая затем служит выходом блока персептрона [11]. Для обучения модели многослойного перцептрона используется классификатор MLPClassifier:
Время обучения модели – 3 минуты 30 секунд.
· Accuracy ≈79% - хороший показатель
· Precision ≈79% - хороший показатель
· Recall ≈79% - хороший показатель
· F-оценка ≈79% - хороший показатель
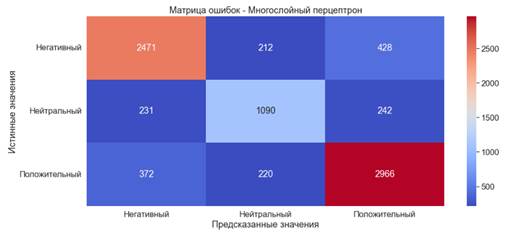
Рис. 6. Матрица ошибок. Многослойный перцептрон с «Мешком слов»
C применением TF-IDF
Модель обучилась за 3 минуты 53 секунды.
· Accuracy ≈78% - хороший показатель
· Precision ≈78% - хороший показатель
· Recall ≈78% - хороший показатель
· F-оценка ≈78% - хороший показатель
Показатели упали примерно на 1% по сравнению с результатами многослойного перцептрона с «Мешком слов»
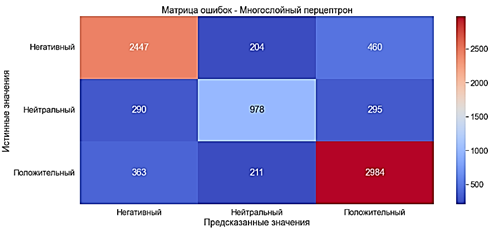
Рис. 7. Матрица ошибок. Многослойный перцептрон с TF-IDF
Случайный лес
Случайный лес работает с деревьями решений, которые используются для классификации нового объекта из входного вектора. В этом алгоритме строится большое количество деревьев решений, поскольку они работают вместе. Деревья решений выступают в качестве столпов в этом алгоритме. Случайный лес определяется как группа деревьев решений, узлы которых определяются на этапе предварительной обработки [12]. После построения нескольких деревьев лучший признак выбирается из случайного подмножества признаков. Для обучения модели Случайного леса используют классификатор RandomForestClassifier. Модель обучилась за 51 секунду
· Accuracy ≈75% - хороший показатель
· Precision ≈75% - хороший показатель
· Recall ≈75% - хороший показатель
· F-оценка ≈75% - хороший показатель
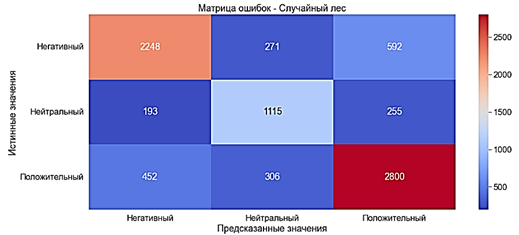
Рис. 8. Матрица ошибок. Случайный лес с «Мешком слов»
C TF-IDF
Модель обучилась за 46 секунд.
· Accuracy ≈20% - очень плохой показатель
· Precision ≈80% - хороший показатель
· Recall ≈20% - очень плохой показатель
· F-оценка ≈8% - очень плохой показатель
Использование TF-IDF ухудшило качество модели настолько, что её нельзя применять для выполнения задач классификации.
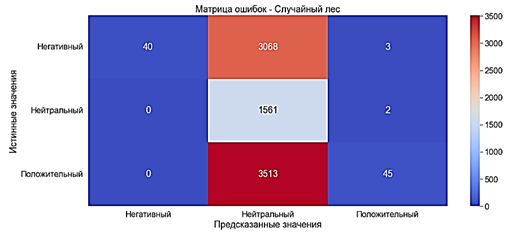
Рис. 9. Матрица ошибок. Случайный лес с TF-IDF
Модель практически все документы определила как «Нейтральные».
Наивный байесовский метод
Алгоритм наивного Байеса используется для распознавания образов и классификации, которые подпадают под различные варианты классификаторов образов для базовой вероятности и правдоподобия [13]. Для обучения модели Наивного байесовского используется классификатор MultinominalNB. Модель обучилась за 0,009 секунды.
· Accuracy ≈67% - средний показатель
· Precision ≈69% - средний показатель
· Recall ≈67% - средний показатель
· F-оценка ≈65% - средний показатель
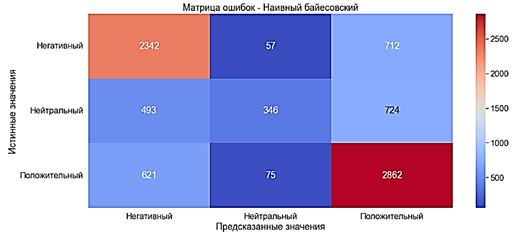
Рис. 10. Матрица ошибок. Наивный байесовский метод с «Мешком слов»
С TF-IDF
Модель обучилась за 0,01 секунды.
· Accuracy ≈63% - средний показатель
· Precision ≈70% - средний показатель
· Recall ≈63% - средний показатель
· F-оценка ≈56% - плохой показатель
Показатели ухудшились примерно 4% по сравнению с моделью Наивного байесовского с «Мешком слов». Наибольшие потери в метрике F-оценка – 9%
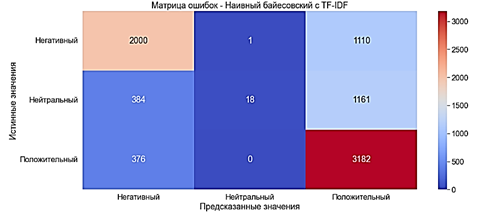
Рис. 11. Матрица ошибок. Наивный байесовский с TF-IDF
Метод К-ближайших соседей
Этот алгоритм фокусируется на сохранении похожих вещей ближе друг к другу. Эта модель работает с метками классов и векторами признаков в наборе данных [14]. KNN хранит все случаи и помогает классифицировать новые случаи с помощью меры подобия. В K-ближайших соседях текст представляется с помощью пространственного вектора, который обозначается S = S ( T1 , W1 ; T2 , W2 ; … Tn , Wn ). Для любого текста с помощью обучающего текста находится и вычисляется сходство, и выбираются тексты с наибольшим сходством. Наконец, классы определяются на основе K соседей. Для обучения модели методом К-ближайших соседей используется классификатор KNeighborsClassifier:
Модель обучилась за 0,003 секунды.
· Accuracy ≈31% - очень плохой показатель
· Precision ≈65% - средний показатель
· Recall ≈31% - очень плохой показатель
· F-оценка ≈29% - очень плохой показатель
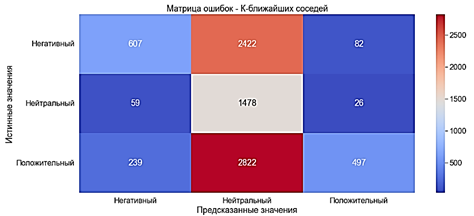
Рис. 12. Матрица ошибок. Метод К-ближайших соседей с «Мешком слов»
CTF-IDF
Ввиду некоторых особенностей классификатора в данном случае мы не можем построить модель методом К-ближайших соседей с применением TF-IDF.
Дерево решений
Дерево решений генерирует набор правил, которые можно использовать для категоризации данных с учетом набора атрибутов и их классов. Для обучения модели методом Дерева решений используется классификатор DecisionTreeClassifier. Модель обучилась за 8 секунд.
· Accuracy ≈70% - средний показатель
· Precision ≈70% - средний показатель
· Recall ≈70% - средний показатель
· F-оценка ≈70% - средний показатель
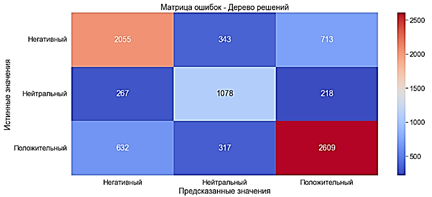
Рис. 13. Матрица ошибок. Дерево решений с «Мешком слов»
С TF-IDF
Модель обучилась за 9 секунд.
· Accuracy ≈61% - средний показатель
· Precision ≈62% - средний показатель
· Recall ≈62% - средний показатель
· F-оценка ≈62% - средний показатель
Показатели ухудшились примерно 8% по сравнению с моделью Дерева решений с «Мешком слов».
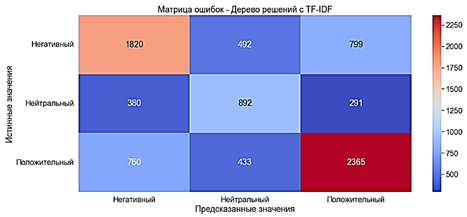
Рис. 14. Матрица ошибок. Дерево решений с TF-IDF
Стохастический градиентный спуск
Алгоритм очень похож на традиционный градиентный спуск . Однако он вычисляет только производную потери одной случайной точки данных, а не всех точек данных (отсюда и название, стохастический). Это делает алгоритм намного быстрее, чем градиентный спуск. Для обучения модели методом стохастического градиентного спуска применяется классификатор SGDClassifier. Модель обучилась за 0,226 секунды.
· Accuracy ≈82% - очень хороший показатель
· Precision ≈82% - очень хороший показатель
· Recall ≈82% - очень хороший показатель
· F-оценка ≈82% - очень хороший показатель
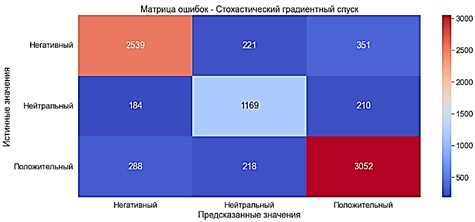
Рис. 15. Матрица ошибок. Стохастический градиентный спуск с «Мешком слов»
С TF-IDF
Обучение модели составило 0,127 секунды.
· Accuracy ≈77% - хороший показатель
· Precision ≈77% - хороший показатель
· Recall ≈77% - хороший показатель
· F-оценка ≈76% - хороший показатель
Показатели ухудшились примерно на 5% в сравнении с моделью стохастического градиентного спуска с «Мешком слов».
Заключение
В этой статье представлен обширный и систематический обзор различных методов машинного обучения для определения тональности речи с точки зрения обработки естественного языка. Реализованы такие действия, как: анализ набора данных, создание описательных графиков и статистической информации, предобработка набора данных, выделение признаков и векторизация текста, построение моделей, улучшение качества построенных моделей. Ниже представлена таблица, которая содержит сводную информацию о результатах обучения моделей при помощи методов, рассмотренных в работе:

Рис. 16. Сравнительная таблица моделей
Цветовые обозначения в таблице:
1. Зеленый цвет – улучшение показателя модели или отдельной метрики.
2. Красный цвет - ухудшение показателя модели или отдельной метрики.
3. Синий цвет – модель с наилучшими показателями.
Библиография
1. Perera R., Nand P. Recent advances in natural language generation: A survey and classification of the empirical literature //Computing and Informatics. – 2017. – Т. 36. – №. 1. – С. 1-32.
2. Dien T. T., Loc B. H., Thai-Nghe N. Article classification using natural language processing and machine learning //2019 International Conference on Advanced Computing and Applications (ACOMP). – IEEE, 2019. – С. 78-84.
3. Sun F. et al. Pre-processing online financial text for sentiment classification: A natural language processing approach //2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr). – IEEE, 2014. – С. 122-129.
4. Carstens L., Toni F. Using argumentation to improve classification in natural language problems //ACM Transactions on Internet Technology (TOIT). – 2017. – Т. 17. – №. 3. – С. 1-23.
5. Mahesh K., Nirenburg S. Semantic classification for practical natural language processing //Proc. Sixth ASIS SIG/CR Classification Research Workshop: An Interdisciplinary Meeting. – 1995. – С. 116-139.
6. Romanov A., Lomotin K., Kozlova E. Application of natural language processing algorithms to the task of automatic classification of Russian scientific texts //Data Science Journal. – 2019. – Т. 18. – №. 1.
7. Young I. J. B., Luz S., Lone N. A systematic review of natural language processing for classification tasks in the field of incident reporting and adverse event analysis //International journal of medical informatics. – 2019. – Т. 132. – С. 103971.
8. Dien T. T., Loc B. H., Thai-Nghe N. Article classification using natural language processing and machine learning //2019 International Conference on Advanced Computing and Applications (ACOMP). – IEEE, 2019. – С. 78-84.
9. Pranckevičius T., Marcinkevičius V. Comparison of naive bayes, random forest, decision tree, support vector machines, and logistic regression classifiers for text reviews classification //Baltic Journal of Modern Computing. – 2017. – Т. 5. – №. 2. – С. 221.
10. Chen P. H. Zafar, H., Galperin-Aizenberg, M., & Cook, T. . Integrating natural language processing and machine learning algorithms to categorize oncologic response in radiology reports //Journal of digital imaging. – 2018. – Т. 31. – №. 2. – С. 178-184.
11. Heo, T. S., Kim, Y. S., Choi, J. M., Jeong, Y. S., Seo, S. Y., Lee, J. H., Kim, C. (2020). Prediction of stroke outcome using natural language processing-based machine learning of radiology report of brain MRI. Journal of personalized medicine, 10(4), 286.
12. Shah, K., Patel, H., Sanghvi, D., & Shah, M. (2020). A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augmented Human Research, 5(1), 1-16.
13. Kim, S. B., Han, K. S., Rim, H. C., & Myaeng, S. H. (2006). Some effective techniques for naive bayes text classification. IEEE transactions on knowledge and data engineering, 18(11), 1457-1466.
14. Dien, T. T., Loc, B. H., & Thai-Nghe, N. (2019, November). Article classification using natural language processing and machine learning. In 2019 International Conference on Advanced Computing and Applications (ACOMP) (pp. 78-84). IEEE.
References
1. Perera R., Nand P. Recent advances in natural language generation: A survey and classification of the empirical literature //Computing and Informatics. – 2017. – Т. 36. – №. 1. – С. 1-32.
2. Dien T. T., Loc B. H., Thai-Nghe N. Article classification using natural language processing and machine learning //2019 International Conference on Advanced Computing and Applications (ACOMP). – IEEE, 2019. – С. 78-84.
3. Sun F. et al. Pre-processing online financial text for sentiment classification: A natural language processing approach //2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr). – IEEE, 2014. – С. 122-129.
4. Carstens L., Toni F. Using argumentation to improve classification in natural language problems //ACM Transactions on Internet Technology (TOIT). – 2017. – Т. 17. – №. 3. – С. 1-23.
5. Mahesh K., Nirenburg S. Semantic classification for practical natural language processing //Proc. Sixth ASIS SIG/CR Classification Research Workshop: An Interdisciplinary Meeting. – 1995. – С. 116-139.
6. Romanov A., Lomotin K., Kozlova E. Application of natural language processing algorithms to the task of automatic classification of Russian scientific texts //Data Science Journal. – 2019. – Т. 18. – №. 1.
7. Young I. J. B., Luz S., Lone N. A systematic review of natural language processing for classification tasks in the field of incident reporting and adverse event analysis //International journal of medical informatics. – 2019. – Т. 132. – С. 103971.
8. Dien T. T., Loc B. H., Thai-Nghe N. Article classification using natural language processing and machine learning //2019 International Conference on Advanced Computing and Applications (ACOMP). – IEEE, 2019. – С. 78-84.
9. Pranckevičius T., Marcinkevičius V. Comparison of naive bayes, random forest, decision tree, support vector machines, and logistic regression classifiers for text reviews classification //Baltic Journal of Modern Computing. – 2017. – Т. 5. – №. 2. – С. 221.
10. Chen P. H. Zafar, H., Galperin-Aizenberg, M., & Cook, T. . Integrating natural language processing and machine learning algorithms to categorize oncologic response in radiology reports //Journal of digital imaging. – 2018. – Т. 31. – №. 2. – С. 178-184.
11. Heo, T. S., Kim, Y. S., Choi, J. M., Jeong, Y. S., Seo, S. Y., Lee, J. H., Kim, C. (2020). Prediction of stroke outcome using natural language processing-based machine learning of radiology report of brain MRI. Journal of personalized medicine, 10(4), 286.
12. Shah, K., Patel, H., Sanghvi, D., & Shah, M. (2020). A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augmented Human Research, 5(1), 1-16.
13. Kim, S. B., Han, K. S., Rim, H. C., & Myaeng, S. H. (2006). Some effective techniques for naive bayes text classification. IEEE transactions on knowledge and data engineering, 18(11), 1457-1466.
14. Dien, T. T., Loc, B. H., & Thai-Nghe, N. (2019, November). Article classification using natural language processing and machine learning. In 2019 International Conference on Advanced Computing and Applications (ACOMP) (pp. 78-84). IEEE.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Рецензируемая статья посвящена применению методов машинного обучения для решения задачи классификации текстов на естественном языке и определению тональности речи.
Методология исследования базируется на изучении литературных источников по теме работы, применении методов логистической регрессия, многослойного перцептрона, случайного леса, наивного байесовского метода, метода K-ближайших соседей, деревьев решений, стохастического градиентного спуска.
Актуальность исследования авторы статьи справедливо связывают с возможностью и необходимостью применения методов машинного обучения для классификации текстов, распознавания угроз, обеспечения безопасности, предотвращения или расследования преступлений.
Научная новизна представленного исследования, по мнению рецензента, заключается в применении методов машинного обучения для определения тональности текста, эмоциональной наполненности и окраски речи в целях обеспечения безопасности.
В статье авторами выделены следующие структурные разделы: Введение, Классификация текста, Разделение выборки и векторизация текста, Логистическая регрессия, Многослойный перцептрон, Случайный лес, Наивный байесовский метод, Метод К-ближайших соседей, Дерево решений, Стохастический градиентный спуск, Заключение, Библиография.
Авторы на основе применения методов машинного обучения анализируют текст, выделяя ключевые слова, их смысловую нагрузку и значимость для определения настроения, на основании чего делают вывод об отнесении тональности текста к одной из трех группы - негативной, позитивной и нейтральной (с отсутствием эмоциональной окраски у текста). В качестве обучающей выборки задачи был использован набор данных «Coronavirus tweets NLP», который для корректного обучения модели был очищен от лишних символов (знаков препинания, цифр, и различных символов), «стоп-слов» и бессмысленных слов.
Библиографический список включает 14 наименований источников на английском языке, на которые в тексте приведены адресные ссылки, свидетельствующие о наличии в публикации апелляции к оппонентам.
К достоинствам рецензируемой статьи следует отнести применение авторами графического способа подачи материалов, удачно иллюстрированных многочисленными рисунками.
Рецензируемая статья не лишена недоработок. Во-первых, в наименовании работы использование слова «выбранных» представляется ненужным, поскольку не несет никакой дополнительной для читателя информации. Во-вторых, в Заключении представлена сравнительная таблица моделей машинного обучения, но не сделаны обобщения о целесообразности их использования для определения тональности текста, ничего не сказано об апробации модели машинного обучения на материалах других датасетов и практическом значении полученных результатов исследования для укрепления безопасности. В-третьих, рисунки 5-15 представляют собой скорее таблицами, чем рисунками, о чем свидетельствует и их наименование: «Матрица ошибок». В-четвертых, список литературы уместно расширить за счет публикаций на русском языке, учитывая возросшее количество научных статей по вопросам машинного обучения в отечественных изданиях, которые также следует отразить в процессе изложения степени изученности проблемы.
Тема статьи актуальна, материал соответствует тематике журнала «Вопросы безопасности», может вызвать интерес у читателей и рекомендуется к опубликованию после устранения замечаний.
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|





