|
ГЛАВНАЯ
> Вернуться к содержанию
Программные системы и вычислительные методы
Правильная ссылка на статью:
Тюгин Д.Ю.
Разработка параллельных алгоритмов в прикладной гидрофизической задаче с использованием современных средств профилирования кода
// Программные системы и вычислительные методы.
2019. № 1.
С. 70-80.
DOI: 10.7256/2454-0714.2019.1.29554 URL: https://nbpublish.com/library_read_article.php?id=29554
Разработка параллельных алгоритмов в прикладной гидрофизической задаче с использованием современных средств профилирования кода
Тюгин Дмитрий Юрьевич
кандидат физико-математических наук
научный сотрудник, лаборатория моделирования природных и техногенных катастроф, Нижегородский Государственный Технический Университет им. Р. Е. Алексеева
603155, Россия, Нижегородская область, г. Нижний Новгород, ул. Минина, 24, ауд. 1117
Tyugin Dmitry
PhD in Physics and Mathematics
Researcher at Laboratory for Modelling Natural and Technogenic Catastrophes at the Alekseeva Nizhny Novgorod State Technical University
603155, Russia, Nizhegorodskaya oblast', g. Nizhnii Novgorod, ul. Minina, 24, aud. 1117

|
dtyugin@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2019.1.29554
Дата направления статьи в редакцию:
17-04-2019
Дата публикации:
06-06-2019
Аннотация:
В данной статье автор рассматривает разработку параллельного алгоритма для ускорения вычислений в прикладной научной задаче. Особое внимание уделяется программным инструментам для профилирования кода. Применение таких инструментов позволяет быстро выделить участки кода для распараллеливания. Рассматриваются библиотеки и технологии реализации параллельного кода для многопроцессорных систем с общей памятью. Обсуждаются подходы к написанию программ на основе потоков и на основе задач. Рассматриваются этапы разработки параллельного кода путем изменения последовательного кода. Приводится анализ времени выполнения функций приложения при помощи инструмента VTune. Предлагается способ распараллеливания по задачам на основе библиотеки TBB. Показана реализация кода позволяющая выполнять параллельные расчеты. В результате данной работы был разработан новый параллельный алгоритм для решения задачи нахождения характеристик внутренних волн в океане в рамках слабонелинейной теории. Полученный алгоритм проанализирован, получены метрики эффективности. Достигнуто ускорение позволяющее производить расчеты карт двумерных распределений в 39 раз быстрее последовательного алгоритма на 56 ядерном вычислительном сервере. Полученные результаты будут применены в дальнейшем при изучении внутренних волн в океане, а также позволят увеличить эффективность исследований при расчете карт параметров большего масштаба.
Ключевые слова:
параллельные алгоритмы, анализ производительности, параллельные технологии, профилировщик кода, многопроцессорные системы, внутренние волны, численное моделирование, уравнение Гарднера, численная модель, гидрологические данные
Представленные результаты получены за счет средств гранта Российского научного фонда (проект №17-71-10101)
Abstract: In this article the author considers the development of a parallel algorithm to speed up calculations in an applied scientific problem. Particular attention is paid to software code profiling tools. The use of such tools allows you to quickly select portions of code for parallelization. The libraries and technologies of parallel code implementation for multiprocessor systems with shared memory are considered. Discusses approaches to writing programs based on threads and task-based. The stages of developing a parallel code by changing the sequential code are considered. An analysis of the execution time of application functions using the VTune tool is given. A method for parallelization of tasks based on the TBB library is proposed. Shows the implementation of the code allows you to perform parallel calculations. As a result of this work, a new parallel algorithm was developed to solve the problem of finding the characteristics of internal waves in the ocean within the framework of the weakly nonlinear theory. The obtained algorithm was analyzed, metrics of efficiency were obtained. Acceleration has been achieved, which allows making calculations of maps of two-dimensional distributions 39 times faster than a sequential algorithm on a 56 nuclear computing server. The results obtained will be applied further in the study of internal waves in the ocean, as well as will increase the effectiveness of research in the calculation of maps of parameters of a larger scale.
Keywords: parallel algorithms, performance analysis, parallel technologies, code profiler, multicore systems, internal waves, numeric simulation, Gardner equation, numeric model, hydrological data
Введение
При разработке прикладных программ для решения задач в области математического моделирования целесообразно применение параллельных алгоритмов. Такой подход позволяет ускорить вычисления путем деления расчетного алгоритма на подзадачи, выполняемые параллельно, что позволяет задействовать все аппаратные ресурсы в многоядерных процессорах и сократить время расчета. При проведении длительных численных экспериментов время расчета является важным фактором. Чем меньше время расчета, тем большее количество экспериментов можно провести на тех же аппаратных ресурсах.
В настоящее время для разработки параллельных алгоритмов существует множество программных продуктов, так называемых профилировщиков приложений. Они помогают ускорить процесс анализа «узких» мест в коде и выделить наиболее ресурсоемкие участки, а также провести анализ производительности распараллеленных программ. Такой подход позволяет в короткие сроки разработать параллельный алгоритм и проанализировать взаимодействие параллельных потоков.
Среди профилировщиков кода для многоядерных систем с общей памятью можно выделить следующие программные продукты: Valgrind [1], OpenSpeedShop [2], ompP [3], TAU [4], VTune [5], MAQAO [6] и др. Некоторые из них требуют предварительной подготовки кода для анализа приложений, путем вставки специальных директив или вызовов функций внешней библиотеки. Кроме того, не все из них имеют пользовательский интерфейс, а выполняют только профилировку, визуализация и анализ результатов может выполняться в другом приложении, поддерживающем формат вывода. После анализа доступных профилировщиков выбор был сделан в пользу программного продукта VTune. Он содержит набор приложений для профилировки, имеет пользовательский интерфейс и не требует вставки директив в исходный код для анализа времени выполнения участков кода.
После анализа кода распараллеливание может быть выполнено с применением различных библиотек и технологий: OpenMP [7,8], TBB [9], QtConcurrent [10]. Стандарт OpenMP базируется на включении директив препроцессора в исходный код, и поддерживается большинством компиляторов. Следует также отметить наличие выстроенных средств параллелизма в новых стандартах языков программирования. Например, в C++ версии 11 появилась поддержка потоков в библиотеке STL (std::threads), которую также поддерживает большинство современных компиляторов.
Распараллеливание на основе потоков приводит к тому, что логические потоки отображаются на физические потоки вычислительного оборудования. Наибольшая эффективность вычислений достигается, когда на один физический поток приходится один логический поток. Если на один физический поток приходится более одного логического, то происходит переключение контекста операционной системой, что приводит к накладным расходам. Затраты времени на переключение контекста связаны с тем, что поток имеет свою собственную копию ресурсов, таких как состояние регистра и стек. Создание и удаление потока также приводит к значительным накладным расходам. Другой подход к распараллеливанию заключается в разделении алгоритма на множество логических подзадач, которые выполняются в потоках, но количество потоков и количество задач регулируется планировщиком. В программировании на основе задач планировщик выполняет балансировку нагрузки. Помимо использования нужного количества потоков, важно равномерно распределять работу между этими потоками. При программировании на основе потоков часто возникает проблема балансировки нагрузки.
Для решения задачи распараллеливания была выбрана библиотека TBB. Выбор связан с тем, что в библиотеке реализована эффективная поддержка планировщика и распараллеливание на основе задач.
Постановка задачи
Рассмотрим задачу численного моделирования внутренних гравитационных волн в океане в рамках слабонелинейной теории. Данный тип волн возникает в океане вследствие вертикальной неоднородности воды по температуре и солёности. Это приводит к образованию в толще жидкости слоев различной плотности, на границах которых и образуются данные волны. Рассмотрим классическое уравнение для описания распространения внутренних волн – уравнение Гарднера [11]
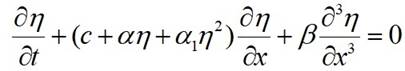
Где n является смещением изопикнической поверхности в максимуме вертикальной моды; c – фазовая скорость внутренних волн; a – коэффициент квадратичной нелинейности; a1 – коэффициент кубической нелинейности; b – коэффициент дисперсии. Параметры c, a, a1 и b зависят от стратификации плотности и глубины океана.
В частности, такие данные могут быть получены путем натурных измерений температуры и солёности в океане с помощью контактных датчиков подводного зондирования, опускаемых с корабля, либо могут быть рассчитаны на основе математических моделей. Эти данные распространяются на свободной основе организациями, которые занимаются исследованием климата планеты. Для расчета будем использовать набор данных RCO полученный на базе модели глобальной циркуляции [12].
На основе карт двумерных распределений параметров уравнения Гарднера можно проводить моделирование распространения волн. Таким образом расчет карт данных параметров является необходимым этапом численного эксперимента. Подробное изложение математической теории расчета данных параметров представлено в работах [11, 13]. В статье ограничимся рассмотрением программной реализации алгоритмов расчета.
Основной алгоритм расчета карт параметров:
1. Для каждой географической точки карты
1.1.Загрузить данные солености, температуры, глубины
1.2.Рассчитать параметры плотности
1.3.Рассчитать коэффициенты
1.3.1. Методом пристрелки найти решение краевой задачи Штурма-Лиувилля
1.4.Сохранить коэффициенты в контейнер данных
Анализ кода и разработка параллельного алгоритма
Рассмотрим пример анализа кода с помощью профилировщика VTune. Для этого необходимо собрать исследуемое приложение в конфигурации Release с включением символов отладки (параметры компилятора /Zi /DEBUG для компилятора MSVC). Затем необходимо выполнить HotSpot анализ путем запуска приложения через профилировщик. Данный тип анализа собирает информацию о времени выполнения кода предоставляя распределение в процентах по функциям и строкам кода, рис. 1.
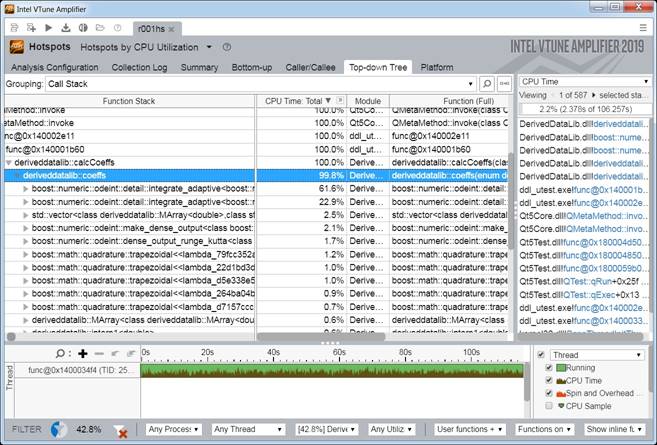
Рис. 1 Анализ последовательного алгоритма профилировщиком VTune
Интересуемый участок расчётного кода представлен в листинге 1.
Листинг 1.
void calcCoeffs(igwdatamodel::IDataProfileIterator::Ptr tempProfileIt,
igwdatamodel::IDataProfileIterator::Ptr salProfileIt,
igwdatamodel::IDataWriter::Ptr dst)
{
while(!tempProfileIt->atEnd() && !salProfileIt->atEnd())
{
igwdatamodel::IDataProfile::Ptr tempProfile = tempProfileIt->get();
igwdatamodel::IDataProfile::Ptr salProfile = salProfileIt->get();
Coeffs result = coeffs(getZ(tempProfile),
getBvf(tempProfile, salProfile),
getDepth(tempProfileIt));
dst->write(result);
tempProfileIt->next();
salProfileIt->next();
}
}
Как видно из анализа большая часть времени выполнения (99.8%) принадлежит функции deriveddatalib::coeffs. Анализ стека этой функции показывает, что основное время состоит из вызовов методов интегрирования системы дифференциальных уравнений, реализованной в библиотеке boost - integrate_adaptive (61.6%) и (22.9%). Данные методы не могут быть распараллелены так как шаги интегрирования имеют зависимость между предыдущим и следующим. Поэтому распараллеливание целесообразно провести по данным на основе независимости расчетов коэффициентов в каждой отдельно взятой географической точке. Таким образом логично поместить множественные вызовы функции deriveddatalib::coeffs в отдельные задачи.
Для этого введем класс доступа к исходным данным и записи результатов расчета
DataHolder, листинг 2.
Листинг 2.
class DataHolder{
igwdatamodel::IDataWriter::Ptr dst;
igwdatamodel::IDataProfileIterator::Ptr tempProfileIt,salProfileIt;
tbb::mutex readMutex;
tbb::mutex writeMutex;
public:
Profile getNextProfile(){
tbb::mutex::scoped_lock lock(readMutex);
Profile profile;
while(!tempProfileIt->atEnd() && !salProfileIt->atEnd())
{
profile = getProfile(tempProfileIt->get(),salProfileIt->get())
tempProfileIt->next();
salProfileIt->next();
return profile;
}
return Profile();
}
void setResult(const Coeffs& result){
tbb::mutex::scoped_lock lock(writeMutex);
dst.write(result);
}
};
Данный класс содержит в себе указатели на контейнеры входных данных температуры и солености (tempProfileIt, salProfileIt), и контейнер для записи данных (dst). Так как контейнеры не имеют атомарных средств доступа то необходимо синхронизировать вызов этих функций так чтобы две задачи не могли одновременно выполнить их вызов. В функциях чтения (getNextProfile) и записи (setResult) реализован вызов синхронизационных примитивов типа мьютекс ( tbb::mutex::scoped_lock lock(writeMutex)). Библиотека TBB содержит специальный класс обертку для реализации блокировки мьютекса (tbb::mutex::scoped_lock), позволяющий заблокировать мьютекс при создании объекта обертки и освободить при разрушении.
Выполнение расчета характеристик в точке перенесено в класс CalcTask, наследуемый от tbb::task. Данный класс реализует разделение работ по задачам, листинг 3.
Листинг 3.
class CalcTask: public tbb::task{
DataHolder* m_holder;
public:
CalcTask(DataHolder* dataHolder):
m_holder(dataHolder){}
tbb::task* execute() {
Profile data = m_holder-> getNextProfile();
if(data.valid){
Coeffs result = coeffs(data.z, data.bvf, data.depth);
m_holder->setResult(result);
tbb::task::recycle_as_continuation();
return this;
}
return nullptr;
}
};
Класс CalcTask принимает на вход указатель на объект доступа к данным и переопределяет виртуальную функцию родительского класса execute, тело которой определяет код, выполняемый параллельно.
Вызов функции tbb::task::recycle_as_continuation() помечает задачу как задачу для повторного выполнения. Таким образом, задача будет перезапущена планировщиком повторно. Данный подход позволяет использовать пул задач и переиспользовать без удаления старых и создания новых задач, тем самым минимизируя накладные расходы, связанные с созданием и удалением объектов. Реализация параллельного запуска задач представлена в листинге 4.
Листинг 4.
void calcCoeffsParallel(igwdatamodel::IDataProfileIterator::Ptr temperature,
igwdatamodel::IDataProfileIterator::Ptr salinity,
igwdatamodel::IDataWriter::Ptr dst)
{
tbb::task_scheduler_init init;
DataHolder holder(temperature,
salinity,
dst);
tbb::task_list list;
for(int i=0;i<init.default_num_threads();++i){
CalcTask& t = *new(tbb::task::allocate_root()) CalcTask(&holder);
list.push_back(t);
}
tbb::task::spawn_root_and_wait(list);
}
Запуск параллельных задач осуществляется в новой функции calcCoeffsParallel. В ней создается объект DataHolder, инициализируется данными. Далее создается объект tbb::task_scheduler_init, который позволяет получить доступное на системе число потоков, как правило равное числу физических потоков поддерживаемое аппаратным обеспечением. Список заполняется количеством задач равным числу потоков. Число задач может быть и больше количества потоков, так как планировщик будет выполнять балансировку нагрузки автоматически. Но в данном случае задачи при старте и окончании расчета выполняют доступ к данным и время доступа мало. Поэтому увеличение задач не приведет к более эффективному распараллеливанию. В том случае если доступ к данным может занимать значительное время, то целесообразно создать отдельную параллельную задачу для наполнения данных. В таком сценарии создание количества задач большее, чем число физических потоков целесообразно, так как заполненные данными для расчета задачи будут ожидать в очереди выполнения и начинать расчет сразу в то время пока данные из выполненных задач будут сохраняться.
Анализ достигнутой производительности
Расчеты проводились на сервере со следующей конфигурацией: 2 процессора Intel Xeon CPU E5-2650 v4 2.20Ггц, 64 Гб оперативной памяти, 512 Гб SSD диск Samsung Evo 850. Каждый процессор имеет 14 ядер и может выполнять до 28 потоков одновременно с помощью технологии Hyper Threading. Суммарно сервер может выполнять до 56 потоков одновременно.
Результаты профилировки распараллеленного приложения в профилировщике VTune представлено на рис. 2.
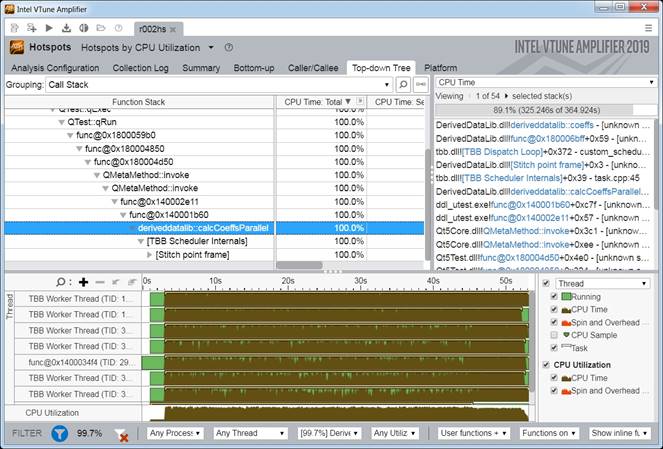
Рис.2 Результат профилировки параллельного алгоритма в профилировщике VTune
Анализ стека вызовов и времени выполнение показывает, что основное время работы приложения находится в расчетных задачах.
Задача расчета характеристик в каждой точке может быть неоднородна и неравномерна по вычислительной длительности между точками, вследствие физических характеристик и выбранных итеративных алгоритмов расчета. Как видно из скриншота загруженности потоков, балансировка нагрузки выполнена эффективно, все потоки загружены максимально однородно, что говорит о правильном делении алгоритма на подзадачи и эффективной работе планировщика задач. Полученное ускорение приведено на рис. 3.
Рис.3 График ускорения параллельного алгоритма
На рис. 3 приведен анализ ускорения параллельного алгоритма при расчете на 2348 точках исходного набора данных. Пунктирной линией помечено идеальное ускорение, которое равно количеству запускаемых расчетных задач. В реальности (синяя кривая) практическое ускорение почти никогда не совпадает с идеальным, так как расчеты зачастую связаны с сохранением и загрузкой данных, а также синхронизацией, которые вносят накладные расходы процессорного времени. С увеличением количества потоков возрастает интенсивность вызова синхронизационных примитивов. Кроме того, дополнительные потоки в режиме Hyper Threading имеют более низкую производительность чем потоки запущенные в режиме равном количеству физических ядер процессора.
На рис. 4 представлена карта фазовой скорости, рассчитанная параллельным алгоритмом. Время расчета сократилось в 39 раз и составило около 165 секунд против 6437 секунд последовательного алгоритма. Данный расчетный блок входит в состав программного комплекса для исследования волн в океане [14] и позволит проводить вычисления значительно быстрее для новых наборов данных, охватывающих большие территории.
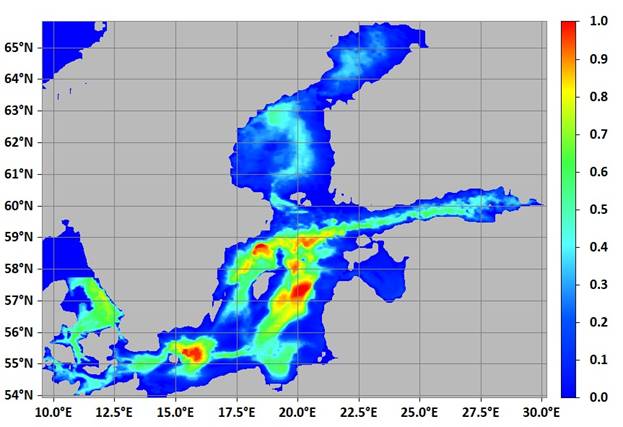
Рис. 4 Карта распределения параметра фазовой скорости
Заключение
В статье были рассмотрены современные средства профилировки, анализа и распараллеливания кода. Прикладная гидрофизическая задача расчета характеристик внутренних волн в стратифицированной жидкости сформулирована в математической постановке и реализована в программном коде. Выполнен анализ последовательного кода с помощью программного продукта VTune. Получены метрики времени выполнения участков кода. Предложен способ распараллеливания по данным, на основе независимости при расчете в разных географических локациях. Выполнена реализация параллельного алгоритма, с использованием библиотек TBB, на основе разделения алгоритма на задачи. Проведен анализ достигнутой производительности с помощью профилировщика VTune. В статье показано применение современных средств профилировки для быстрого и эффективного ускорения расчетов численных экспериментов в прикладной гидрофизической задаче.
Библиография
1. Nethercote N., Seward J. Valgrind: A Framework for Heavyweight Dynamic Binary Instrumentation // Proceedings of ACM SIGPLAN 2007 Conference on Programming Language Design and Implementation. 2007. 205 P.
2. OpenSpeedShop. URL: https://openspeedshop.org
3. Zhao J., Tao J., Fürlinger K. A Framework for Comparative Performance Study on Virtualized Machines // International Journal of Ad Hoc and Ubiquitous Computing. 2014. V. 17. P. 82-99.
4. Shende S., Malony D. The TAU parallel performance system. // International Journal of High-Performance Computing Applications. 2006. P. 287-311.
5. VTune. URL: https://software.intel.com/en-us/vtune
6. Bendifallah Z., Jalby W., Noudohouenou J., Oseret E., Palomares V. Performance Assessment Using MAQAO Toolset and Differential Analysis // Proceedings of the 7th International Workshop on Parallel Tools for High Performance Computing. 2013. P. 107-127.
7. Klemm M., Supinski B. OpenMP Application Programming Interface Specification Version 5.0// Independently published. 2019. 668 P.
8. OpenMP. URL: https://www.openmp.org
9. TBB. URL: https://www.threadingbuildingblocks.org
10. QtConcurrent. URL: https://doc.qt.io/qt-5/qtconcurrent-index.html
11. Pelinovsky E., Polukhina O., Slunyaev A. & Talipova T. Internal solitary waves // Chapter 4 in the book “Solitary Waves in Fluids” (Editor R. Grimshaw). WIT Press. Southampton, Boston, 2007. P.85 – 110.
12. Meier H.E.M., Döscher R., Coward A.C., Nycander J., Döös K. RCO-Rossby Centre regional Ocean climate model: Model description (version 1.0) and first results from the hindcast period 1992/93 // Rep. Oceanogr. 26, Swed. Meteorol. Hydrol. Inst., Norrköping, Sweden, 1999. 102 p.
13. Kurkina O., Kurkin A., Rybin A., Tyugin D., Soomere T. Pycnocline variations in the Baltic sea affect background conditions for internal waves // Measuring and Modeling of Multi-Scale Interactions in the Marine Environment-IEEE/OES Baltic International Symposium. 2014. P. 207-218.
14. Тюгин Д. Ю. Разработка программных инструментов сопровождения численного эксперимента по моделированию внутренних волн в стратифицированной жидкости // Кибернетика и программирование. Т. 2. С. 66 – 74. doi: 10.25136/2306-4196.2018.2.25990
References
1. Nethercote N., Seward J. Valgrind: A Framework for Heavyweight Dynamic Binary Instrumentation // Proceedings of ACM SIGPLAN 2007 Conference on Programming Language Design and Implementation. 2007. 205 P.
2. OpenSpeedShop. URL: https://openspeedshop.org
3. Zhao J., Tao J., Fürlinger K. A Framework for Comparative Performance Study on Virtualized Machines // International Journal of Ad Hoc and Ubiquitous Computing. 2014. V. 17. P. 82-99.
4. Shende S., Malony D. The TAU parallel performance system. // International Journal of High-Performance Computing Applications. 2006. P. 287-311.
5. VTune. URL: https://software.intel.com/en-us/vtune
6. Bendifallah Z., Jalby W., Noudohouenou J., Oseret E., Palomares V. Performance Assessment Using MAQAO Toolset and Differential Analysis // Proceedings of the 7th International Workshop on Parallel Tools for High Performance Computing. 2013. P. 107-127.
7. Klemm M., Supinski B. OpenMP Application Programming Interface Specification Version 5.0// Independently published. 2019. 668 P.
8. OpenMP. URL: https://www.openmp.org
9. TBB. URL: https://www.threadingbuildingblocks.org
10. QtConcurrent. URL: https://doc.qt.io/qt-5/qtconcurrent-index.html
11. Pelinovsky E., Polukhina O., Slunyaev A. & Talipova T. Internal solitary waves // Chapter 4 in the book “Solitary Waves in Fluids” (Editor R. Grimshaw). WIT Press. Southampton, Boston, 2007. P.85 – 110.
12. Meier H.E.M., Döscher R., Coward A.C., Nycander J., Döös K. RCO-Rossby Centre regional Ocean climate model: Model description (version 1.0) and first results from the hindcast period 1992/93 // Rep. Oceanogr. 26, Swed. Meteorol. Hydrol. Inst., Norrköping, Sweden, 1999. 102 p.
13. Kurkina O., Kurkin A., Rybin A., Tyugin D., Soomere T. Pycnocline variations in the Baltic sea affect background conditions for internal waves // Measuring and Modeling of Multi-Scale Interactions in the Marine Environment-IEEE/OES Baltic International Symposium. 2014. P. 207-218.
14. Tyugin D. Yu. Razrabotka programmnykh instrumentov soprovozhdeniya chislennogo eksperimenta po modelirovaniyu vnutrennikh voln v stratifitsirovannoi zhidkosti // Kibernetika i programmirovanie. T. 2. S. 66 – 74. doi: 10.25136/2306-4196.2018.2.25990
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования – разработка параллельных алгоритмов для численного моделирования внутренних гравитационных волн в океане в рамках слабонелинейной теории (уравнение Гарднера, решение краевой задачи Штурма-Лиувилля) с использованием современных средств профилирования кода (профилировщик приложений для многоядерных систем с общей памятью VTune).
Методология исследования основана на сочетании теоретического и модельного подходов с применением методов анализа, алгоритмизации, моделирования, программирования, сравнения, обобщения, синтеза.
Актуальность исследования обусловлена широким применением компьютерных технологий (в том числе параллельных вычислений) в проведении современных научных исследований и, соответственно, необходимостью изучения и реализации алгоритмов численного моделирования (включая прикладные геофизические задачи) с использованием современных средств профилирования кода.
Научная новизна связана с математическим обоснованием и программной реализацией автором параллельного алгоритма расчёта на основе разделения на задачи характеристик внутренних волн в стратифицированной жидкости с использованием библиотек TBB и VTune, который может применяться для эффективного ускорения численных экспериментов в прикладных гидрофизических задачах. Получены метрики времени выполнения участков кода. Предложен способ распараллеливания по данным на основе независимости при расчете в разных географических локациях. Проведен анализ достигнутой производительности, свидетельствующий о существенном сокращении времени расчёта по сравнению с последовательным алгоритмом.
Стиль изложения научный, официально-деловой. Статья написана русским литературным языком.
Структура рукописи включает следующие разделы: Введение (разработка прикладных программ для решения задач в области математического моделирования, применение параллельных алгоритмов, профилировщики приложений для многоядерных систем с общей памятью – Valgrind, OpenSpeedShop, ompP, TAU, VTune, MAQAO и др., распараллеливание на основе потоков с применением различных библиотек и технологий OpenMP, TBB, QtConcurrent, стандарт OpenMP, программирование на основе задач, библиотека TBB), Постановка задачи (задача численного моделирования внутренних гравитационных волн в океане в рамках слабонелинейной теории, уравнение Гарднера, измерения температуры и солёности в океане с помощью контактных датчиков подводного зондирования, набор данных RCO, основной алгоритм расчёта карт параметров), Анализ кода и разработка параллельного алгоритма (пример анализа кода с помощью профилировщика VTune, анализ последовательного алгоритма, класс доступа к исходным данным и записи результатов расчёта, расчёт характеристик в точке, класс CalcTask, запуск параллельных задач), Анализ достигнутой производительности (результаты профилировки распараллеленного приложения в профилировщике VTune, анализ стека вызовов и времени выполнение, загруженность потоков, балансировка нагрузки, ускорение параллельного алгоритма при расчёте на 2348 точках исходного набора данных, карта фазовой скорости), Заключение (выводы), Библиография.
Текст включает четыре рисунка. Оформление рисунков соответствует установленным требованиям. В пояснениях к рисунку 4 желательно указать, для какого объекта приведены расчётные данные.
Содержание в целом соответствует названию. В то же время в формулировке заголовка желательно уточнить, о какой именно прикладной геофизической задаче идёт речь (численное моделирование внутренних гравитационных волн в океане в рамках слабонелинейной теории). Также не ясно, для какого / каких именно океанов проведено моделирование – приведённый пример (рисунок 4) связан, очевидно, с Балтийским морем, а не с океаном.
Библиография включает 14 источников отечественных и зарубежных авторов – монографии, научные статьи, материалы научных мероприятий, Интернет-ресурсы. Библиографические описания некоторых источников нуждаются в корректировке в соответствии с ГОСТ и требованиями редакции, например:
1. Nethercote N., Seward J. Valgrind: A Framework for Heavyweight Dynamic Binary Instrumentation // Proceedings of ACM SIGPLAN 2007 Conference on Programming Language Design and Implementation. Место издания ??? : Наименование издательства ???, 2007. P. ??? –???.
2. OpenSpeedShop. URL: https://openspeedshop.org.
4. Shende S., Malony D. The TAU parallel performance system. // International Journal of High-Performance Computing Applications. 2006. V. ???. № ???. P. 287–311.
5. VTune. URL: https://software.intel.com/en-us/vtune.
6. Bendifallah Z., Jalby W., Noudohouenou J., Oseret E., Palomares V. Performance Assessment Using MAQAO Toolset and Differential Analysis // Proceedings of the 7th International Workshop on Parallel Tools for High Performance Computing. Место издания ??? : Наименование издательства ???, 2013. P. 107-127.
7. Klemm M., Supinski B. OpenMP Application Programming Interface Specification Version 5.0. Место издания ??? : Independently published, 2019. 668 P.
11. Pelinovsky E., Polukhina O., Slunyaev A., Talipova T. Internal solitary waves // Solitary Waves in Fluids / ed. R. Grimshaw. Southampton, Boston : WIT Press. 2007. P. 85–110.
Библиографические описания завершаются точкой. Ссылки на программные продукты Valgrind [1], OpenSpeedShop [2], ompP [3], TAU [4], MAQAO [6], которые далее не рассматриваются, представляются излишними, достаточно упоминания указанных продуктов в основном тексте.
Апелляция к оппонентам (Nethercote N., Seward J., Zhao J., Tao J., Fürlinger K., Shende S., Malony D., Bendifallah Z., Jalby W., Noudohouenou J., Oseret E., Palomares V., Klemm M., Supinski B., Pelinovsky E., Polukhina O., Slunyaev A., Talipova T., Meier H. E. M., Döscher R., Coward A. C., Nycander J., Döös K., Kurkina O., Kurkin A., Rybin A., Tyugin D., Soomere T. и др.) имеет место.
Текст нуждается в редактировании, например:
- Рассмотрим классическое уравнение для описания распространения внутренних волн – уравнение Гарднера [11]: (ДВОЕТОЧИЕ);
- Г(СТРОЧНАЯ БУКВА)де n является смещением изопикнической поверхности в максимуме вертикальной моды;
- В частности, такие данные (ПОВТОР) могут быть (ПОВТОР) получены путем натурных измерений температуры и солёности в океане с помощью контактных датчиков подводного зондирования, опускаемых с корабля, либо могут быть (ПОВТОР) рассчитаны на основе математических моделей. Эти данные (ПОВТОР) распространяются на свободной основе организациями, которые занимаются исследованием климата планеты. Для расчета будем использовать набор данных (ПОВТОР) RCO, (ЗАПЯТАЯ) полученный на базе модели глобальной циркуляции [12].
- Таким образом, (ЗАПЯТАЯ) расчет карт данных параметров является необходимым этапом численного эксперимента. Подробное изложение математической теории расчета данных параметров представлено в работах [11, 13]. В статье ограничимся рассмотрением программной реализации алгоритмов расчета.
Основной алгоритм расчета карт параметров:
1. Для каждой географической точки карты (ТОЧКА С ЗАПЯТОЙ; ЗДЕСЬ И НИЖЕ);
- Данный тип анализа собирает информацию о времени выполнения кода, (ЗАПЯТАЯ) предоставляя распределение в процентах по функциям и строкам кода (РИСУНОК 1).
В качестве разделителя в десятичной записи числе следует использовать запятую. Аббревиатуру RCO желательно расшифровать.
В целом рукопись соответствует основным требования, предъявляемым к научным статьям. Материал представляет интерес для читательской аудитории и после доработки может быть опубликовании в журнале «Программные системы и вычислительные методы» (рубрики «Параллельные алгоритмы решения задач вычислительной математики», «Математическое моделирование и вычислительный эксперимент»).
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|



