|
ГЛАВНАЯ
> Вернуться к содержанию
Кибернетика и программирование
Правильная ссылка на статью:
Лобанов А.А., Фильгус Д.И.
Метод поиска кратчайшего гамильтонового пути в произвольном графе на основе рангового подхода, обеспечивающего высокую оперативность и малую погрешность решения задачи организации процесса управления множеством транзакций и запросов при их реализации в сетевых базах данных
// Кибернетика и программирование.
2018. № 5.
С. 63-75.
DOI: 10.25136/2644-5522.2018.5.26513 URL: https://nbpublish.com/library_read_article.php?id=26513
Метод поиска кратчайшего гамильтонового пути в произвольном графе на основе рангового подхода, обеспечивающего высокую оперативность и малую погрешность решения задачи организации процесса управления множеством транзакций и запросов при их реализации в сетевых базах данных
Лобанов Александр Анатольевич
кандидат технических наук
доцент, кафедра инструментального и прикладного программного обеспечения, МИРЭА – Российский технологический университет
119454, Россия, г. Москва, пр. Вернадского, 78, каб. Г-225
Lobanov Aleksandr Anatolevich
PhD in Technical Science
Associate Professor, Department of Instrumental and Applied Software, MIREA Russian Technological University
119454, Russia, g. Moscow, pr. Vernadskogo, 78, kab. G-225

|
aa.lobanoff@ya.ru
|
|
 |
Другие публикации этого автора
|
|
|
Фильгус Дмитрий Игревич
аспирант, кафедра Инструментального и прикладного программного обеспечения, РТУ МИРЭА
119454, Россия, г. Москва, Проспект Вернадского, 78
Filgus Dmitrii Igrevich
Postgraduate Student, Department of Tool and Application Software, Russian University of Technology
119454, Russia, g. Moscow, Prospekt Vernadskogo, 78
|
|
dmif42@ya.ru
|
|
 |
|
DOI: 10.25136/2644-5522.2018.5.26513
Дата направления статьи в редакцию:
05-06-2018
Дата публикации:
25-11-2018
Аннотация:
Объектом исследований является подсистема управления реализацией рабочей нагрузки в сетевой базе данных. Предмет исследований - управление процессом формирования графика реализации запросов абонентов и транзакций в сетевой базе данных. Во многих случаях существующие решения не обеспечивают необходимых результатов по времени доступа и точности найденного решения. Возникает необходимость в разработке метода формирования графика реализации запросов пользователей и транзакций. Особое внимание уделяется алгоритмам выборки запросов в сетевых базах данных, а также концептуальной модели процесса управления транзакциями и запросами. В работе используются методы теории графов. Оценка эффективности решения задачи выполнена с использованием системного подхода, системного анализа и теории исследования операций. Обработка экспериментальных данных, полученных в ходе работы, проводилась в соответствии с положениями математической статистики. Разработан метод поиска кратчайшего гамильтонового пути в произвольном графе на основе рангового подхода, который обеспечивает высокую оперативность и малую погрешность решения задачи организации процесса управления множеством транзакций и запросов при их реализации в сетевых базах данных. Использование разработанного метода позволяет минимизировать время простоя вычислительных устройств, сократить объемы и время передачи данных от одних исполнительных устройств другим, повысить общую масштабируемость, минимизировать время доступа к данным и пр. Важным достоинством предлагаемого метода является уменьшения числа элементарных операций и числа обрабатываемых векторов в процедуре формирования очереди выполнения операций запроса, что приводит к существенному уменьшению времени на реализацию процедур формирования очереди выполнения операций в запросах.
Ключевые слова:
граф, гамильтонов путь, запрос, ранговый подход, сетевая база данных, стянутое дерево путей, транзакция, ранг, оптимизация, отклонение в измерениях
Abstract: The object of research is the workload implementation management subsystem in a network database. The subject of research is the management of the formation of the schedule for the implementation of subscriber requests and transactions in a network database. In many cases, existing solutions do not provide the necessary results in terms of access time and accuracy of the found solution. There is a need to develop a method for scheduling the implementation of user and transaction requests. Particular attention is paid to the algorithms of sampling queries in network databases, as well as the conceptual model of the process of managing transactions and queries. We use methods of graph theory. The evaluation of the effectiveness of the task solution was performed using a systems approach, system analysis and the theory of operations research. Processing of experimental data obtained during the work was carried out in accordance with the provisions of mathematical statistics. A method has been developed for finding the shortest Hamiltonian path in an arbitrary graph based on a rank approach, which provides high efficiency and small error in solving the problem of organizing the process of managing multiple transactions and queries when they are implemented in network databases. Using the developed method allows minimizing idle time of computing devices, reducing the volume and time of data transfer from one device to another, increases overall scalability, minimizes data access time, etc. An important advantage of the proposed method is to reduce the number of elementary operations and the number of vectors being processed the queue of the operations of the request, which leads to a significant reduction in time to implement the procedures for the formation of echer di operations in the requests.
Keywords: graph, Hamiltonian path, query, rank approach, network database, stub tree, transaction, rank, optimization, deviation in measurements
Краткий анализ проблем управления множеством транзакций в сетевых базах данных
Решению задач организации процесса управления множеством транзакций и запросов при их реализации в сетевых базах данных уделялось относительно немного внимания. Это связано со следующими основными факторами [1,2]:
- отсутствует единая методология проектирования и реорганизации множества запросов и транзакций;
- существующие приближенные алгоритмы, реализующие методы управления, не обладают приемлемой точностью найденного решения.
- данные задачи по своей природе являются NP-полными, и эффективных точных алгоритмов решения для них пока не существует;
- реализация данных алгоритмов требует значительных системных ресурсов, а их стоимость при условии набора необходимого объема вычислительной памяти значительно превосходила стоимость затрат на разработку методов решения первой задачи.
Учитывая перечисленные основные проблемы, актуальность получения решения приемлемой точности и сложности остается высокой, что в первую очередь связано с ростом объемов информации и увеличением числа пользователей сетевых баз данных.
Различные общие вопросы и прикладные аспекты применения распределенных вычислительных сред (РВС) исследованы в работах Загороднего А. Г., Згуровского М. З., Мартыненко Е. С., Фостера Я. (Foster I.), Кесельмана К. (Kesselman C.) и других ученых. Вопросам разработки методов и моделей планирования, оптимизации и повышения производительности функционирования РВС, обеспечения качества обслуживания в вычислительных средах с использованием современных технологий распределенных и параллельных вычислений в фундаментальных и прикладных исследованиях посвящены работы Воеводина В. В., Воеводина Вл. В., Гергеля В. П., Цветкова В.Я. [3,4], Горбенко А. В., Дорошенко А. Е., Корнеева В. В., Куссуль Н. Н., Листрового С. В., Мамойленко С. Н., Павлова А. А., Петренко А. И., Погорелого С. Д., Пономаренко В. С., Ролика А. И., Симоненко В. П., Стиренко С. Г., Топоркова В. В., Хорошевского В. Г., Шелестова А. Ю., Шматкова С. И., Буйи Р. (Buyya R.), Ксхафы Ф. (Xhafa F.) и других ученых. Наиболее известными исследованиями в области алгоритмического, математического и программного обеспечения распределения задач по вычислительным узлам гетерогенной вычислительной среды можно считать работы Бершадского А.М., Голубева И.А., Кальпеевой Ж.Б., Селиверстова Е.Ю., Покусина Н.В., Хачкинаева Г.М., Телеснина Б.А., Бычкова И.В., Agrawal D., Zhao H., Sakellariou R., Amar A., Bolze R., Boix E., Amedro B., Bodnartchouk V. и Baduel L. Выбор способа распределения задач (данных) по вычислительным узлам определяет общую эффективность вычислительной среды.
В [5-8] показано, что выбор способа распределения задач (данных) по вычислительным узлам определяет общую эффективность вычислительной среды. Корректный выбор может минимизировать время простоя вычислительных устройств, сократить объемы и время передачи данных от одних исполнительных устройств другим, повысить общую масштабируемость, минимизировать время доступа к данным и пр. Настоящая работа посвящена разработке метода поиска кратчайшего гамильтонового пути в произвольном графе на основе рангового подхода, обеспечивающего высокую оперативность и малую погрешность решения задачи организации процесса управления множеством транзакций и запросов при их реализации в сетевых базах данных.
Организация процесса управления множеством транзакций и запросов в сетевой базе данных
Анализируя некоторые работы [9-13], можно прийти к выводу, что управление нагрузкой состоит из ряда взаимосвязанных процессов, реализуемых в сетевой базе данных (СБД). Также можно прийти к заключению, что наиболее существенное влияние на качество и оперативность управления транзакциями и запросами в СБД оказывает влияние процесс формирования графика реализации множества транзакций и запросов пользователей. В свою очередь изучение данного процесса позволило выделить две основные задачи, требующие своего решения и являющихся составляющими процесса формирования графика реализации множества транзакций и запросов пользователей [14-16]:
- задача подготовки исходных данных;
- задача составления плана реализации запросов пользователей и транзакций.
Пусть имеется множество запросов и транзакций:
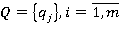
к сетевой базе данных, содержащей множество:
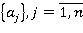
атрибутов, отображающих предметную область этой информационной структуры. Каждый запрос qj для поиска релевантных объектов требует обработки части данных информационной структуры, отображаемой подмножеством:
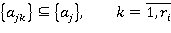
причем каждый атрибут ajk проверяется на множестве условий:
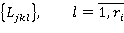
которые могут входить в различные логические выражения семантических фрагментов запроса. При этом семантика запроса и логическая структура организации данных предъявляют множество требований – к организации процесса обработки данных.
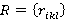
Каждое требование rikl представляет собой ограничение на порядок проверки условий, заключающееся в обязательности предварительной проверки определенного подмножества условий, входящих в множества:
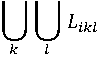
Перед проверкой условия Likl. Структуры запроса и транзакций поступающие на обслуживание представим в виде графа G(V,E), где множеству вершин соответствуют элементарные операторы транзакций и запросов. Введенные вершины соединены рёбрами, если, по логическим условиям, операторы оказывают влияние на выполнение следующих операторов транзакций и запросов. Ребрам графа сопоставим весовые характеристики представляющие собой сумму времени доступа к требуемому атрибуту aj и время проверки логических условий Likl для реализации оператора запроса (транзакции) qj в базе данных:
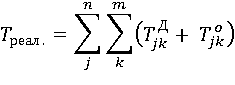
(1).
Поскольку время доступа к требуемому атрибуту TjkДзависит от характеристик используемой система управления базами данных, организации структуры хранения сетевой базы данных и используемых методов доступа то его можно определить до начала выполнения процесса реализации транзакций и запросов. Методика определения данной временной характеристики приведена в [6]. Вторая же часть весовой характеристики Tjk0 зависит от логических условий предъявляемых пользователями в семантической части запросов и транзакций, а поскольку заранее нет возможности определить порядок появления тех или иных логических условий проверки атрибута aj, то указанная временная характеристика является изменяемой и требующей динамической оценки в процессе решения задачи непосредственно.Поэтому возникает потребность в решении задачи подготовки исходных данных для определения весовых характеристик ребер графа G(V,E). Физически эта задача реализуется посредством создания в оперативной памяти матриц электронно-вычислительной машины, отражающих взвешенный граф набора транзакций и запросов, предварительный анализ которых проведен посредством применения теории реляционной алгебры.
Вторым этапом построенияграфика реализации множества транзакций и запросов, является, непосредственно, формирование плана выполнения операторов языка манипулирования данными (ЯМД) с учетом требований, предъявляемых пользователями.
Поскольку, время реализации поступающих на обслуживание запросов и транзакций существенно зависит от порядка их выполнения, возникает необходимость указания порядка их обработки, минимизирующего суммарное время реализации рабочей нагрузки.
Исходными данными для решения указанной задачи выступает множество пар 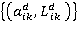 полученных в результате решения первой задачи, и являющимися вершинами графа плана реализации операторов запросов и транзакций, а также весовые характеристики ребер соединяющих вершины данного графа и физически отражающие время проверки логического условия, накладываемого пользователем для реализации семантического фрагмента запроса qi. Тогда решение задачи достигается минимизацией целевой функции, представляющей время обслуживания множества запросов Q и имеющей вид: полученных в результате решения первой задачи, и являющимися вершинами графа плана реализации операторов запросов и транзакций, а также весовые характеристики ребер соединяющих вершины данного графа и физически отражающие время проверки логического условия, накладываемого пользователем для реализации семантического фрагмента запроса qi. Тогда решение задачи достигается минимизацией целевой функции, представляющей время обслуживания множества запросов Q и имеющей вид:
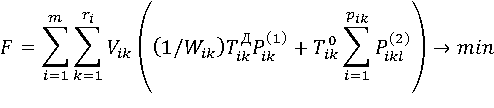
(2),
где Vik- количество экземпляров атрибута aik ; Pik(1)и Pilk(2) – коэффициенты использования aik,характеризующие вероятности использования экземпляров атрибута aik в процессах доступа и обработки, соответственно; TjkД, – среднее время доступа к одному экземпляру атрибута aik ; Tik0– среднее время обработки aik (проверки наложенного на aik условия или обработки –aik в качестве аргумента функции); Wik – общее (по всем запросам) количество условий, одновременно проверяемых на aik. TjkД, – среднее время доступа к одному экземпляру атрибута aik ; Tik0– среднее время обработки aik (проверки наложенного на aik условия или обработки –aik в качестве аргумента функции); Wik – общее (по всем запросам) количество условий, одновременно проверяемых на aik.
Коэффициенты Pik(1) и Pilk(2) определяются по формулам:
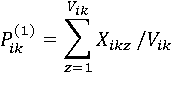
(3),
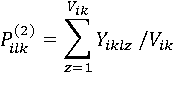
(4).
Где Xikz–булева переменная, принимающая значение 0 только тогда, когда обработка aikz по всем Pik условиям при текущих значениях данных утеряла свой смысл (например, если запись при обслуживании предыдущего запроса была удалена); Yiklz–булева переменная, принимающая значение 0 только тогда, когда обработка aikz по l-му условию при текущих значениях данных утеряла свой смысл.
В выражении (1) Vik определяется структурой информационной системы, ее временными характеристиками и используемым программным аппаратом обработки информации, и может быть определена до обработки запроса. Оптимизация достигается составлением такого упорядоченного множества пар при котором выражение (3) принимает наименьше значение. Построение такого упорядоченного множества определяется двумя факторами: последовательностью обхода aik в информационной структуре и выбором множества условий, одновременно проверяемых для каждого aik. в информационной структуре и выбором множества условий, одновременно проверяемых для каждого aik.
Назовём u-тым планом реализации множества запросов в информационной структуре упорядоченное множество пap
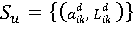 , где , где 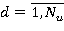
где Nu — номер шага выполнения плана Su (на котором обрабатывается единственный атрибут);
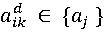
– атрибут, который на d-ом шаге подвергается проверке одновременно на множестве таких условий Likld, что
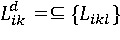 и и 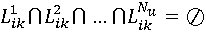
Опишем множество S допустимых планов просмотра Su∈ S, если ∀dи ∀Likl ∈ Likdсправедливо:
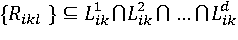
т. е. для каждого проверяемого в соответствии с Su условия выполняется необходимое требование из R. Целевая функция (1) является временной оценкой исполнения плана Suна этапе диспетчеризации. Таким образом, задача сводится к нахождению оптимального плана S*такого, что
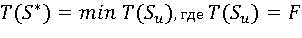
(5).
Таким образом вторая задача может рассматриваться как задача определения кратчайшего гамильтонового пути (КГП) в графе G. Поскольку данная задача относится к классу NP – полных задач, а её решение должно осуществляться в реальном масштабе времени, возникает необходимость в разработке метода, позволяющего находить решение при заданных ограничениях на временные ресурсы. Кроме того, не менее важным требованием, выдвигаемым к алгоритмам реализующих метод поиска кратчайшего гамильтонового пути, является точность, поскольку число сбоев и коллизий в системе зависит от точности сформированного графика и способности выявления тупиковых ситуаций реализации множества транзакций и запросов. Общие методы решения данной задачи для динамических информационных систем являются трудноприменимыми в силу высоких требований к точности нахождения оптимального решения и скорости её решения из-за значительной размерности.
Разработка метода поиска кратчайшего гамильтонового пути в произвольном графе на основе рангового подхода
Пусть все возможные состояния некоторой системы определяются графом М(F,N) с n вершинами, где вершины соответствуют возможным состояниям системы. Такое пространство состояний можно представить в виде стянутого дерева путей D (рис. 1). Дерево всех путей D содержит (n-1) горизонтальную линейку и (n-1) ярус. Для прочтения путей на каждой горизонтальной линейке можно бывать только один раз. Исходя из стянутого дерева путей, для произвольной вершины j множество путей, ведущих в эту вершину из некоторой вершины s, можно представить в следующем виде:
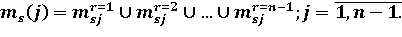
где 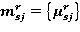 подмножества путей из произвольной вершины s в некоторую вершину j графа М(F,N) ранга r подмножества путей из произвольной вершины s в некоторую вершину j графа М(F,N) ранга r

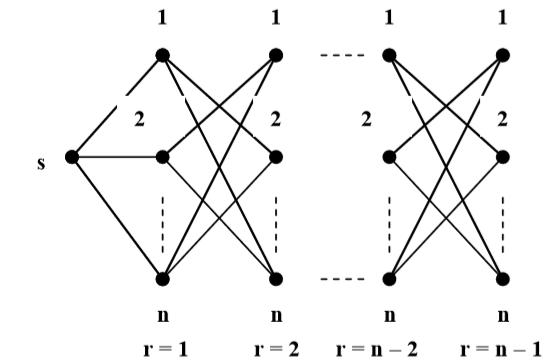
Рисунок 1 - Стянутое дерево всех путей D графа M(F,N)
Используя граф D и введя правила формирования путей следующего ранга мы можем из произвольной вершины s поэтапно строить пути произвольного ранга вплоть до ранга r=n-1. Таким образом, для решения задачи определения кратчайшего гамильтонового пути в графе D нужно построить кратчайшие пути ранга г=n-1от вершины 1, 2, ...,n ко всем остальным вершинам графа и потом среди них выбирать кратчайший.
Рассмотрим процедуруА для определения кратчайшего гамильтонового пути в произвольном графе. Из вершины s строятся все возможные пути ранга r = 1 ко всем вершинам графа D, далее, используя пути ранга r = 1, строятся все возможные пути ранга r = 2 и на их основе формируются пути следующего ранга, с использованием рекуррентного соотношения
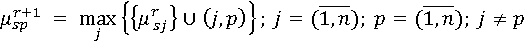 (6), (6),
где (j, p) – ребро графа D; n – число различных вершин в графе D, и т. д. до построения путей ранга r = n – 1.
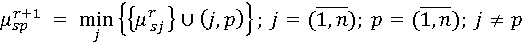 (7). (7).
Следует отметить, что если в процессе применения рекуррентного соотношения (6) возникают несколько кратчайших путей одинаковой длины, то необходимо их все строить на следующем ранге.
Можно выделить следующие особенности работы процедуры А. В процессе ее работы может возникать две ситуации. Первая, когда процедура А на каждом шаге построила пути в множества mrsj т.е. принцип оптимальности работы процедуры не нарушался и вторая, когда к одной из вершин ни одного пути построить нельзя. Последнее обстоятельство возможно в двух случаях:
а) если анализируемый граф неполный и к вершине р не существует пути некоторого ранга r = k;
б) когда некоторая вершина р войдет во все пути предыдущего ранга.
Можно показать, что в первой ситуации процедура А не теряет оптимальное решение, а во второй ситуации (случай б) оптимальное решение может быть потеряно, поскольку принцип оптимальности работы процедуры нарушается. Это означает, что на основе процедуры А может быть построен только приближенный алгоритм решения задачи. Однако после нарушения принципа оптимальности последующее продление путей с использованием рекуррентного соотношения (7) позволит минимально отклоняться от оптимального решения.
Алгоритм А1 решения задачи определения кратчайших гамильтоновых путей в произвольных графах
Шаг 1. Присваиваем значение S: = 1 переменной S и в графе D используя процедуру А определяем кратчайшие пути ранга r = n – 1 от вершины S ко всем остальным вершинам графа и увеличиваем значение S: = S + 1.
Шаг 2. Проверяем S = n, если нет, то переходим к выполнению шага 1, иначе выполняем следующий шаг.
Шаг 3. Среди всех построенных кратчайших путей ранга r = n – 1 на шагах 1 и 2 выбираем самый короткий, и алгоритм заканчивает работу.
Для решения задачи за один проход определим точку входа, начиная с которой начнет работу алгоритм. Для этого введем понятие минимально удаленной вершиныi в произвольном графе G(V, E)
Пусть задан граф G(V, E) c n вершинами и множеством ребер E каждому из которых присвоен вес в виде произвольного положительного числа βj. Поставим каждой вершине s графа G(V, E)в соответствие вектор Хs
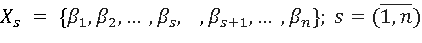
(8),
в котором на s-й позиции стоит символ  , означающий, что элемент βs в Хs отсутствует. Множество {βj} представляет собой множество положительных чисел, к которым будем относить и 0. Будем говорить, что некоторая вершина i минимально удалена от вершины s, определяемой вектором Хs, если расстояние d(s,i) между вершинами s и I определяется соотношением , означающий, что элемент βs в Хs отсутствует. Множество {βj} представляет собой множество положительных чисел, к которым будем относить и 0. Будем говорить, что некоторая вершина i минимально удалена от вершины s, определяемой вектором Хs, если расстояние d(s,i) между вершинами s и I определяется соотношением
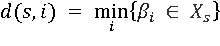 (9). (9).
Если существует Q вершин i, удовлетворяющих соотношению (9), то это означает, что существует Q минимально равно удаленных вершин от вершины s, определяемой вектором Хs. Определив вершину i входа для графа можно решать задачу определения кратчайшего гамильтонового пути за один проход процедуры А1, при этом погрешность по сравнению с n-проходной процедурой, как будет показано ниже, увеличивается не более чем на один процент, а сложность алгоритма понижается в n – 1 раз.
Результаты экспериментального исследования разработанных алгоритмов
Для получения аналитических результатов экспериментального исследования алгоритмов решения задачи поиска кратчайшего гамильтонового пути разработана программная модель реализованная в прикладной тестирующей программе с условным названием Analizator.
Прикладная тестирующая программа Analizator предназначена для проведения тестов разработанных алгоритмов и обработки результатов тестирования. Исходя из основного назначения прикладной программы предложено выделить три основных части программы, выполняющих функциональную нагрузку:
· область формирования исходных данных и настройки тестов;
· область анализа полученных результатов и их отображения на графиках;
· область отображения поранговых результатов тестирования и формирования записей в базе данных.
Использование указанных областей позволяет контролировать промежуточные значения реализации алгоритмов, получать конечные результаты в виде графиков и таблиц базы данных. При этом дополнительно обеспечиваются следующие возможности:
· автоматический ввод расчетных данных;
· ручной ввод расчетных данных;
· отображение статистики;
· запись результатов в базу данных;
· простой и интуитивно доступный интерфейс.
При экспериментальном сравнении разработанных алгоритмов с известными весами ребер графа генерировались по равномерному закону распределения в диапазоне (0–50). Для получения среднего значения каждой точки графиков всех анализируемых характеристик решалось по 200 тестовых задач, все результаты статистического анализа получены с доверительной вероятностью 0,95. На всех рисунках разработанные алгоритмы А1 и А2 обозначены как метод –1 и метод–2. Как видно из графиков, приведенных на рис. 2 при n≥27, алгоритмы Литтла и локального поиска имеют существенно более высокую временную сложность по сравнению с разработанными.

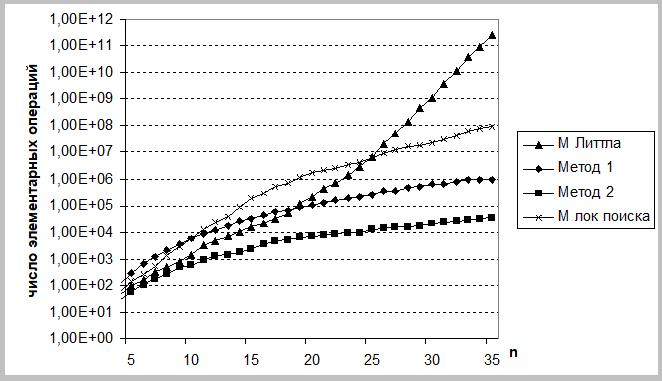
Рисунок 2 – Зависимости числа элементарных операций от размерности решаемой задачи
Анализ производительности алгоритмов показывает, что алгоритмы локального поиска имеют погрешность, лежащую в диапазоне от 7% до 29% и возрастающую с увеличением размерности решаемых задач. В разработанных алгоритмах, на основе идей рангового подхода, погрешность с увеличением размерности задачи стабилизируется и не превышает 2% (см. рис. 3).
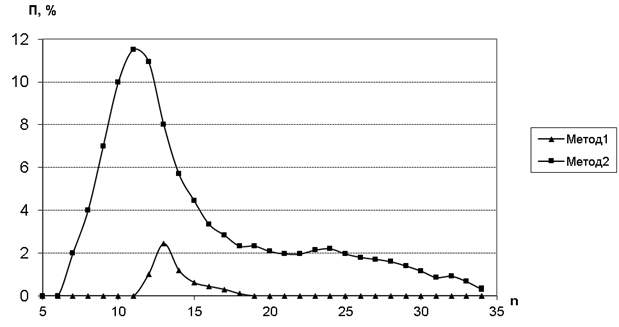
Рисунок 3 – Зависимость относительной погрешности от размерности решаемой задачи
Из графиков приведенных на рис. 4, видно, что процент неточных решений для алгоритма А1 при n≥27 очень низок. Экспериментальное исследование показало, что при n≥27 на 2000 тестовых задач в среднем только 3 давали приближенное решение и при этом погрешность не превышала 1–2%.

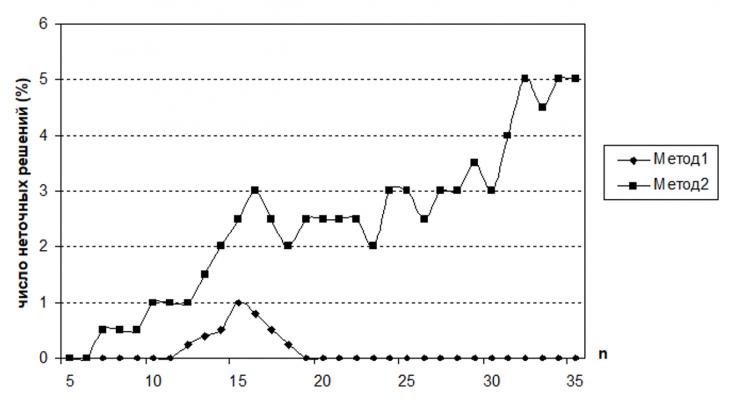
Рисунок 4 - Зависимость числа неточных решений в % от размерности решаемой задачи
Использование эвристического правила в алгоритме А2 позволило с одной стороны существенно уменьшить временную сложность этого алгоритма по сравнению с А1, но при этом возрастает погрешность и число неточных решений в нем с увеличением размерности решаемой задачи растет.
Основные выводы и результаты работы
Таким образом, предлагаемый способ решения задачи параллельной обработки запросов может быть использован в сетевых базах данных для составления оптимальных расписаний выполнения запросов к базам данных, как на этапах реорганизации, так и на этапах сопровождения функционирования систем управления включающих базы данных. При этом предполагается существенное уменьшение времени на реализацию процедуры формирования очереди выполнения операций в запросах за счет уменьшения числа элементарных операций и числа обрабатываемых векторов в процедуре формирования очереди выполнения операций запроса.
Из экспериментального исследования разработанных алгоритмов решения рассмотренных в работе задач следует, что в случае формализации задач булевого программирования в графовой постановке в большинстве случаев удается уменьшить временную сложность алгоритмов.
Библиография
1. Буй Д.Б., Скобелев В.Г. Модели, методы и алгоритмы оптимизации запросов в базах данных / Д.Б. Буй, В.Г. Скобелев // Компьютерные системы и информационные технологии 2014, № 2 (66) C. 43-58
2. Listrovoy S.V., Tretiak V.F., Listrovaya E.S.. Parallel algorithms of calculation process optimization for the boolean programming problems Engineering Simulation.– 1999. – Vol. 16.– РР. 569-579.
3. Цветков, В.Я. Модели в информационном поле: монография / В.Я. Цветков – Saarbrücken: Palmarium Academic Publishing, 2018.– 129 с.
4. Буравцев, А.В., Цветков, В.Я. Аутопойезис сложной организационно-технической системы / А.В. Буравцев, В.Я. Цветков // Дистанционное и виртуальное обучение. – 2018. – № 2 (122). С. 5–11.
5. Харари Ф. Теория графов / Ф. Харари; ред. Г. П. Гаврилов; авт. предисл. В. П.Козырев.-5-е изд., доп.-М.: Ленанд, 2018.-304 с.
6. Хусаинов, А.А. Дискретная математика: учеб. пособие / А.А. Хусаинов, Н.Н. Михайлова. – Комсомольск-на-Амуре: ФГБОУ ВПО «КнАГТУ», 2013. – 78 с
7. Мальцев, И.А. Дискретная математика / И.А. Мальцев. – М.: Лань, 2011. – 304 с.
8. Емеличев В. А. Лекции по теории графов [Текст]: учебное пособие / В. А. Емеличев [и др.].-3-е изд.-Москва: URSS, 2013.-383 с.
9. Федорин А.Н. Многокритериальные задачи ранцевого типа: разработка и сравнительный анализ алгоритмов: Дис. ... канд. техн. наук: 05.13.18 / Нижегородский государственный университет им. Н.И. Лобачевского. – Нижний Новгород, 2010.-132 с.
10. Фраленко В. П., Агроник А. Ю. Средства, методы и алгоритмы эффективного распараллеливания вычислительной нагрузки в гетерогенных средах // Программные системы: теория и приложения №3(26), 2015, с. 73-92
11. Фильгус Д. И. Развитие методов параллельных вычислений для фрагментации данных сетевой базы данных на основе рангового подхода / Д. И. Фильгус, Е. Г. Андрианова, В. К. Раев // Электронный журнал Cloud of Science. — 2018. — Т. 3, № 5.
12. Информационное обеспечение систем организационного управления (теоретические основы) [Текст] : в 3-х ч. / под ред. Е. А. Микрина, В. В. Кульбы.-М. : Физматлит, 2011-. Ч. 2 : Методы анализа и проектирования информационных систем / Е. А. Микрин [и др.].-2011.-493 с
13. Матчин, В.Т., Цветков, В.Я. Обновление пространственной базы данных / В.Т. Матчин, В.Я. Цветков // Дистанционное и виртуальное обучение. – 2018. – № 3 (123). С. 78–85.
14. Кудж С.А., Цветков В.Я. Закономерности информационного поля: монография / С.А. Кудж, В.Я. Цветков – М.: МАКС Пресс, 2017.– 80 с.
15. Цветков, В.Я. Закономерности информационного поля / В.Я. Цветков // Дистанционное и виртуальное обучение. – 2017. – № 6 (120). – С. 5–13.
16. Фильгус Д. И. Методы и алгоритмы распределения рабочей нагрузки в сетевых базах данных / Д. И. Фильгус // Международный журнал прикладных и фундаментальных исследований. — 2018. — Т. 4.
References
1. Bui D.B., Skobelev V.G. Modeli, metody i algoritmy optimizatsii zaprosov v bazakh dannykh / D.B. Bui, V.G. Skobelev // Komp'yuternye sistemy i informatsionnye tekhnologii 2014, № 2 (66) C. 43-58
2. Listrovoy S.V., Tretiak V.F., Listrovaya E.S.. Parallel algorithms of calculation process optimization for the boolean programming problems Engineering Simulation.– 1999. – Vol. 16.– RR. 569-579.
3. Tsvetkov, V.Ya. Modeli v informatsionnom pole: monografiya / V.Ya. Tsvetkov – Saarbrücken: Palmarium Academic Publishing, 2018.– 129 s.
4. Buravtsev, A.V., Tsvetkov, V.Ya. Autopoiezis slozhnoi organizatsionno-tekhnicheskoi sistemy / A.V. Buravtsev, V.Ya. Tsvetkov // Distantsionnoe i virtual'noe obuchenie. – 2018. – № 2 (122). S. 5–11.
5. Kharari F. Teoriya grafov / F. Kharari; red. G. P. Gavrilov; avt. predisl. V. P.Kozyrev.-5-e izd., dop.-M.: Lenand, 2018.-304 s.
6. Khusainov, A.A. Diskretnaya matematika: ucheb. posobie / A.A. Khusainov, N.N. Mikhailova. – Komsomol'sk-na-Amure: FGBOU VPO «KnAGTU», 2013. – 78 s
7. Mal'tsev, I.A. Diskretnaya matematika / I.A. Mal'tsev. – M.: Lan', 2011. – 304 s.
8. Emelichev V. A. Lektsii po teorii grafov [Tekst]: uchebnoe posobie / V. A. Emelichev [i dr.].-3-e izd.-Moskva: URSS, 2013.-383 s.
9. Fedorin A.N. Mnogokriterial'nye zadachi rantsevogo tipa: razrabotka i sravnitel'nyi analiz algoritmov: Dis. ... kand. tekhn. nauk: 05.13.18 / Nizhegorodskii gosudarstvennyi universitet im. N.I. Lobachevskogo. – Nizhnii Novgorod, 2010.-132 s.
10. Fralenko V. P., Agronik A. Yu. Sredstva, metody i algoritmy effektivnogo rasparallelivaniya vychislitel'noi nagruzki v geterogennykh sredakh // Programmnye sistemy: teoriya i prilozheniya №3(26), 2015, s. 73-92
11. Fil'gus D. I. Razvitie metodov parallel'nykh vychislenii dlya fragmentatsii dannykh setevoi bazy dannykh na osnove rangovogo podkhoda / D. I. Fil'gus, E. G. Andrianova, V. K. Raev // Elektronnyi zhurnal Cloud of Science. — 2018. — T. 3, № 5.
12. Informatsionnoe obespechenie sistem organizatsionnogo upravleniya (teoreticheskie osnovy) [Tekst] : v 3-kh ch. / pod red. E. A. Mikrina, V. V. Kul'by.-M. : Fizmatlit, 2011-. Ch. 2 : Metody analiza i proektirovaniya informatsionnykh sistem / E. A. Mikrin [i dr.].-2011.-493 s
13. Matchin, V.T., Tsvetkov, V.Ya. Obnovlenie prostranstvennoi bazy dannykh / V.T. Matchin, V.Ya. Tsvetkov // Distantsionnoe i virtual'noe obuchenie. – 2018. – № 3 (123). S. 78–85.
14. Kudzh S.A., Tsvetkov V.Ya. Zakonomernosti informatsionnogo polya: monografiya / S.A. Kudzh, V.Ya. Tsvetkov – M.: MAKS Press, 2017.– 80 s.
15. Tsvetkov, V.Ya. Zakonomernosti informatsionnogo polya / V.Ya. Tsvetkov // Distantsionnoe i virtual'noe obuchenie. – 2017. – № 6 (120). – S. 5–13.
16. Fil'gus D. I. Metody i algoritmy raspredeleniya rabochei nagruzki v setevykh bazakh dannykh / D. I. Fil'gus // Mezhdunarodnyi zhurnal prikladnykh i fundamental'nykh issledovanii. — 2018. — T. 4.
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|





