|
ГЛАВНАЯ
> Вернуться к содержанию
Кибернетика и программирование
Правильная ссылка на статью:
Степанов П.П.
Применение алгоритмов группового управления и машинного обучения на примере игры "Battlecode"
// Кибернетика и программирование.
2019. № 1.
С. 75-82.
DOI: 10.25136/2644-5522.2019.1.23527 URL: https://nbpublish.com/library_read_article.php?id=23527
Применение алгоритмов группового управления и машинного обучения на примере игры "Battlecode"
Степанов Петр Петрович
магистр, Дальневосточный федеральный университет
690922, Россия, Приморский край, г. Владивосток, ул. Аякс, 10
Stepanov Petr Petrovich
Master, Far Eastern Federal University
690922, Russia, Primorskii krai, g. Vladivostok, ul. Ayaks, 10, 6011

|
fromuralwithlove@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.25136/2644-5522.2019.1.23527
Дата направления статьи в редакцию:
06-07-2017
Дата публикации:
04-03-2019
Аннотация:
Предметом исследования являются задача группового управления автономными агентами в динамичной мультиагентной системе и самообучение модели управления. Автор подробно рассматривает такие аспекты проблемы как групповое взаимодействие, на примере наиболее эффективных алгоритмов групповго управления, таких как SWARM, муравьиный алгоритм, пчелиный алгоритм, алгоритм светлячков и алгоритм движения косяка рыб, и обучение искусственной нейронной сети, посредством применения обучения с подкреплением. Проведено сравнение различных алгоритмов поиска оптимального пути. Сравнение было проведено на основе игровой среды "Battlecode", динамично формирующей новую карту для нового раунда, что обеспечило качество сравнения рассмотренных алгоритмов. Автор использует статистические методы анализа данных, выделение и анализ качественных признаков, методы прогнозирования, метод моделирования, метод классификации. Автор показывет, что Q-обучение увеличивает свою эффективность, при замене табличного представления Q-функции на нейронную сеть. Проведенная работа доказывает эффективность пчелиного алгоритма в решении задачи исследования и патрулирования местности. При этом алгоритм поиска пути А* оказывается значительно более гибким и эффективным, чем алгоритм Дейкстры.
Ключевые слова:
групповое управление, нейронная сеть, обучение с подкреплением, игровой искусственный интеллект, пчелиный алгоритм, муравьиный алгоритм, мультиагентная система, Battlecode, моделирование, агент
Abstract: The subject of the research is the task of group management of autonomous agents in a dynamic multi-agent system and self-study of the management model. The author examines such aspects of the problem as a group interaction, using the example of the most effective group control algorithms, such as SWARM, ant algorithm, bee algorithm, firefly algorithm and fish school movement algorithm, and training of an artificial neural network through the use of reinforcement training. A comparison of various algorithms for finding the optimal path. The comparison was made on the basis of the gaming environment "Battlecode", which dynamically forms a new map for the new round, which ensured the quality of the comparison of the considered algorithms. The author uses statistical methods of data analysis, the selection and analysis of qualitative signs, forecasting methods, modeling method, classification method. The author shows that Q-learning increases its effectiveness by replacing the tabular representation of the Q-function with a neural network. This work proves the effectiveness of the bee algorithm in solving the problem of researching and patrolling the area. At the same time, the path search algorithm A* is much more flexible and efficient than the Dijkstra algorithm.
Keywords: group management, neural network, reinforcement learning, game artificial intellegence, bee algorithm, ant algorithm, multiagent system, Battlecode, modeling, agent
Введение
Задача группового управления автономными агентами с развитием беспилотных технологий (автомобилей, летательных дронов, роботов-курьеров и т.д.) становится актуальной. Создание модели управления таким роботом процесс науко- и ресурсоемкий, поэтому для избежания ошибок, связанных с их созданием «вручную», в последнее время внимание исследователей привлекает процесс автоматизации создания модели управления. Этот вопрос рассматривается в данной работе на примере проектирования автономного модуля-агента для игры «Battlecode». Проведен анализ существующих алгоритмов группового управления и предложен метод автоматического построения управляющей модели для автономного агента среды «Battlecode» с применением методов машинного обучения.
Постановка задачи
В данной работе поставлена задача разработки метода, решающего задачу адаптивного управления и группового взаимодействия агентов в динамично изменяющейся среде. Данная задача была рассмотрена на примере разработки системы управления агентом в игре «Battlecode».
«BattleCode» это стратегия в реальном времени. Участникам необходимо написать программу на языке программирования Java, которая будет отдавать управляющие команды для автономного агента. Игра состоит из раундов. В каждом раунде новая, уникальная локация, на которой размещены как разрушаемые, так и не разрушаемые препятствия, ресурсы и оружие. Группе роботов каждой из команд необходимо изучить карту, и собрать имеющиеся ресурсы и оружие. Роботы (агенты) в игре используют радиостанции для общения и совместной работы в команде. У каждого робота есть два типа оружия с одинаковым радиусом применениям: автомат и гранаты. Количество гранат, в отличие от боеприпасов для автомата, ограничено. Идея состоит в том, чтобы занять максимальную территорию, уничтожив роботов из команды противника. В конце концов, тот, кто контролирует максимальную территорию, побеждает. В случае равной территориальной оккупации выигрывает команда с большим количеством выживших роботов (агентов).
«Battlecode» необходимо рассматривать как мультиагентную систему, поскольку все агенты (роботы) автономны, ограничены в представлении о системе, в которой находятся и децентрализованы, т.е. отсутствует агент, управляющий всей системой. Также необходимо отметить, что система является динамической, поскольку её конфигурация и архитектура изменяются в процессе функционирования, поэтому поведение системы, носящее вероятностный характер, наиболее полно описывается с помощью поведенческих алгоритмов. Такие алгоритмы группового управления принято разделять на два типа: «коллектив» и «рой».
В «коллективе» каждый агент знает обо всех других агентах системы. Главными недостатками такого алгоритма являются поддержание актуальной базы «известных» агентов в памяти каждого агента и необходимость «познакомить» новичка со всеми членами коллектива. Учитывая специфику задачи, наиболее предпочтительными являются алгоритмы типа «рой», в которых каждый агент знает только агентов, принадлежащих тому же «рою». Главное достоинство такого типа алгоритмов – динамичность. Однако как поведение отдельных агентов в «рою», так и поведение всего «роя» носят вероятностный характер. Поэтому «рой» позволяет решать задачи с недостаточными или противоречивыми исходными данными о системе. Примером такой задачи служит игра «Battlecode», в которой агентам изначально неизвестна система, радиус видимости объектов системы ограничен и игровая среда полностью изменяется при начале нового раунда. Ключевые достоинства «роя» заключаются в устойчивости к выходу из строя одного или нескольких агентов и масштабируемости, поскольку никто не ведет учет состава «роя». Задачи, обычно решаемые с помощью данного типа алгоритмов, являются наиболее важными в «Battlecode»: поиск в условиях малоизвестной местности, изучение неизвестной местности и патрулирование местности.
Существует пять основных моделей организации «роя»: SWARM, муравьиный алгоритм, пчелиный алгоритм, алгоритм движения косяка рыб и алгоритм светлячков.
SWARM предполагает соблюдение каждым агентом трех правил:
- агенты должны соблюдать равную дистанцию друг от друга, стремясь к центру масс (средней позиции) «роя»;
- каждый агент должен двигаться в том же направлении, что и находящиеся по близости агенты;
- каждый агент должен стремиться избежать столкновения с другим агентом.
Данный алгоритм достаточно прост и позволяет программировать взаимозаменяемых и равнозначных агентов, однако сложность вычисления центра масс при увеличении «роя» затрудняется, а отсутствие лидера затрудняет управление.
Муравьиный алгоритм подразумевает, что после обнаружения цели, агент возвращается «домой», помечая обратный маршрут «феромонами». Если другие агенты найдут их, они, вероятнее всего, пойдут этим маршрутом. Если цель будет обнаружена по прежнему маршруту, агенты снова отметят маршрут «феромонами». «Феромоны» испаряются со временем, и чем больше времени расходуется на преодоление маршрута от «дома» до «цели», тем выше вероятность, что агенты выберут другой маршрут.
Пчелиный алгоритм предполагает, что изначально в случайных направлениях вылетает определенное количество агентов, а после обнаружения или не обнаружения потенциального ресурса возвращаются к рою, где принимается решение о том, сколько агентов направится к каждому из направлений, количество агентов зависит от количества обнаруженного ресурса. Пчелиный алгоритм ориентирован на поиск ресурсов в условиях неизвестной местности. Его ключевым достоинствами являются отсутствие необходимости высчитывания центра масс, взаимозаменяемость и равнозначность агентов, а также гибкая масштабируемость. Ключевой недостаток – отсутствие лидера, координирующего перемещение всей группы агентов, что осложнят управление агентами, как единой системой.
Алгоритм светлячков, заключающийся в том, что привлекательность светлячков определяется их яркостью. Агенты притягиваются к более яркому. Однако яркость затухает при удалении от агента. Если агент не наблюдает рядом других агентов, ярче него, он свободно блуждает по карте. Данный алгоритм эффективно подходит для боевой системы. Если за яркость принимать уровень опасности, то можно использовать модель, при которой агент с более высоким уровнем опасности будет привлекать других агентов, чтобы создать перевес сил и либо вступить в бой, либо продолжить сбор ресурсов, зная, что при столкновении группа агентов, которую сконцентрировал, победит и выживет.
При использовании нейронной сети для решения задачи необходимо учитывать сложности и особенности задачи. Если сложно свести задачу к одному из существующих типов нейронной сети, необходимо решать дополнительную задачу синтеза новой конфигурации.
Необходимо решить следующие задачи для определения оптимальной модели нейронной сети:
- классифицировать существующие модели нейронных сетей;
- проанализировать их сильные и слабые стороны;
- определить критерии, по которым будет проводиться отбор нейросети для построения модели;
- разработать ключевые характеристики по определению качества созданной модели, основанной на нейронной сети.
Модель сети является основной характеристикой нейронной сети. Нейронные сети можно классифицировать по задачам, которую решает сеть, видам используемых нейронов и структуре модели сети. Сегодня нейронные сети решают широкий круг задач, в частности, задачи управления, прогнозирования, распознавания и классификации образов, сжатия данных, аппроксимации, кластерного анализа и т.д.
По структуре связей нейронные сети разделяются на полносвязанные и неполносвязные. В первых передача выходного сигнала от нейрона осуществляется остальным нейронам, в том числе и самому себе. Всем нейронам подаются все входные сигналы. Неполносвязные сети, то есть сети, которые можно описать неполносвязным ориентированным графом, обычно называемым перцептроном, разделяют на однослойные и многослойные, с обратными, перекрестными и прямыми связями. В сетях с прямыми связями нейроны k-го слоя на входе могут быть соединены только с выходами нижележащих слоев. В то время как наличие перекрестных связей означает, что допустимы связи внутри одного слоя. Многослойные нейронные сети принято разделять на три типа: монотонные, сети без обратных связей и сети с обратными связями.
Кроме рассмотренной выше задачи координации перемещения роботов, необходимо решить задачу выбора оптимального маршрута, распределения общей цели между роботами, задачу оптимизации состава роботов, в зависимости от ключевых параметров (уровень здоровья, класс брони, мощь вооружения и т.д.). Реализовать систему, решающую все эти задачи можно с помощью конечного автомата, или модуля с конечным числом возможных состояний, а также с помощью нейронной сети. Важнейшей особенностью последней является наличие памяти и способность к обучению. Для обучения нейронной сети применяют так называемое обучение с подкреплением, когда системе на основе определенных параметров сообщают о качестве принятого решения. Параметры могут быть как простыми (количество собранных ресурсов, количество уничтоженных роботов противника и т.д.), комплексными (отношение «побед» к потерям, отношение собранных/разведанных ресурсов к потерям разведчиков и т.д.) и статистическими. Для повышения качества обучения, необходимо определить основные причины, которые должны побуждать робота к действию. Это позволит роботу автономно принимать решения, даже если в процессе обучения было рассмотрено небольшое число потенциальных состояний среды.
Обучение позволит определить приоритеты робота, а также список нежелательных ситуаций, которые необходимо избегать. Такое обучение будет происходить автоматически. Обучение с подкреплением, как класс задач, предполагает, что агент, взаимодействуя с определенной средой, должен выработать оптимальную модель такого взаимодействия.
Наиболее популярным методом для решения таких задач является Q-Learning. Обратная связь, которую получает агент, после взаимодействия с системой, представляет собой «награду», выраженную количественно. Агент должен стремится максимизировать такую награду.
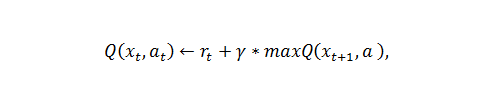
где 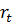 – награда, полученная при переходе из состояния системы – награда, полученная при переходе из состояния системы 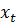 в в 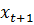 , , 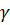 – дисконт-фактор 0 – дисконт-фактор 0 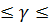 1, 1, 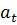 – действие, выбранное из множества всех возможных действий A. Q представлена как дисконтированная сумма награды, получаемой системой с момента времени t. – действие, выбранное из множества всех возможных действий A. Q представлена как дисконтированная сумма награды, получаемой системой с момента времени t.
Предлагаемый метод.
Предлагаемый метод заключается в замене табличного представления Q-функции на нейронную сеть. Это позволит существенно снизить требовательность к вычислительным ресурсам, в частности, памяти. При этом на вход сети будут подаваться соответствующие состояния, а выходом будет Q-значение действия 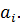
Для каждого действия предлагается обучать отдельную нейронную сеть. Такой подход позволит избежать конфликтных сигналов от разных выходов и обеспечит повышение общего качества решения задачи, позволяя построить нейронные сети, максимально адаптированные для решения конкретной задачи.
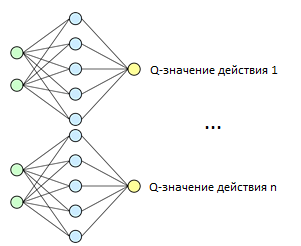
Рисунок 1. Общая модель нейронной сети.
Модель управления роботом строится в два этапа. На первом этапе будет происходить обучение сетей, отвечающих за конкретное действие. На втором этапе будет производиться обучение сети, отвечающей за переход от общей стратегии, направленной на исследование территории и сбор ресурсов, к стратегии непосредственных атакующих действий.
В течение первого этапа нейронные сети агента обучаются для следующих действий соответственно:
- исследование территории;
- выбор оптимального маршрута;
- боевое взаимодействие;
- распределение ролей;
- переход от исследования к нападению.
Основная задача второго этапа заключается в обучении нейронной сети, отвечающей за смену глобальной стратегии с исследования территории и мелких столкновений на полноценное агрессивно-наступательное поведение.
Конкретизируем цели обучения:
1. обучение исследованию территории:
- состояние среды: (не)преодолимое препятствие, агент союзник/враг, полезный ресурс;
- действия: пчелиный алгоритм, муравьиный алгоритм;
- награда: «+5» за увеличение ресурсов, «+1» за исследование среды;
2. выбор оптимального маршрута:
- состояние среды: относительная цена маршрута;
- действия: алгоритм поиска А*, алгоритм Дейкстры;
- награда: «+5» за построение более «дешевого» маршрута;
3. боевое взаимодействие:
- состояние среды: общая боевая сила противников, находящихся в зоне видимости, общая сила союзных агентов, находящихся в зоне видимости, алгоритм светлячка;
- действие: отступление, атака;
- награда: «+5» за уничтожение агента противника, «-5» за потерю своего агента;
4. распределение ролей:
- состояние среды: мирное время (исследование), военное время;
- действие: роль разведчика, роль добытчика ресурсов, роль солдата;
- награда: «+5» за победу в раунде, «-5» за поражение, «+2» за получение ресурса, «+2» за уничтожение агента противника;
5. переход от исследования к нападению:
- состояние среды: процент исследованной территории, отношение агрессивного поведения противника к общему числу столкновений;
- действия: переход к нападению;
- награда: «+5» за победу в раунде, «-5» за поражение.
Результаты экспериментов.
Обучение проводится в два этапа. На первом этапе проходит обучение нейронных сетей для каждого отдельного действия в специально смоделированных условиях. Второй этап состоит в обучении нейронной сети, которая отвечает за переход от общей тактики исследования/сбора ресурсов к нападению. Обучение организовано путем проведения сражений против моделей-противников Cwega, Spock73 и RobotClass, распространяемых на официальном форуме игры и являющихся, соответственно, победителями соревнований в 2012, 2014 и 2015 годах. Каждый раунд проходит на новой игровой территории. Построенные нейронные сети сравниваются по итогам игры с этими моделями.
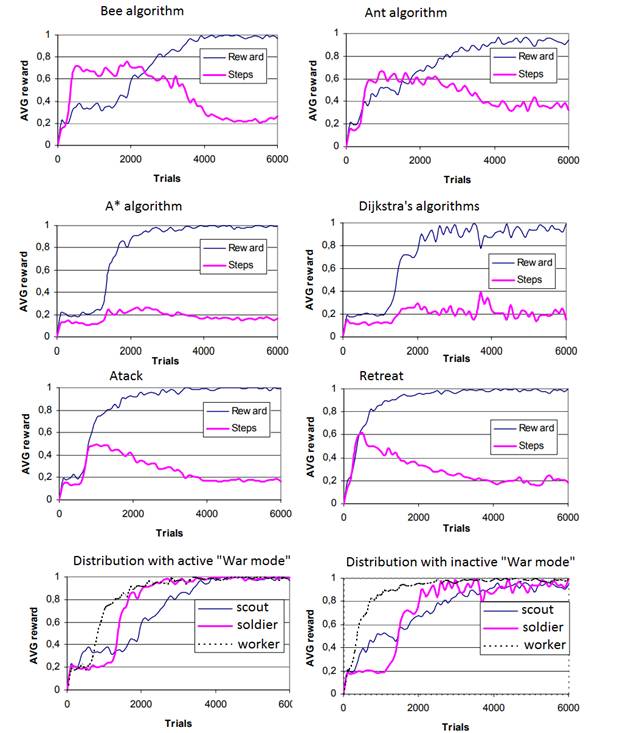
Рисунок 2. Графики средней награды в задачах.
Заключение.
В данной работе рассмотрена задача построения модели, осуществляющей групповое управление автономными агентами в мультиагентной системе на примере игры «Battlecode». Для решения задачи оптимизации управления и адаптации модели к динамично изменяющейся среде предложено обучение с подкреплением.
Сравнение результатов для различных действий и их влияние на итоговый результат раунда позволяет сделать вывод о том, что в условиях динамично меняющейся окружающей среды, пчелиный алгоритм эффективнее решает задачу исследования местности, при условии, что поиск ресурсов не менее важен, чем само исследование среды.
Более того, в условиях постоянно меняющейся среды, в том числе перемещение групп агентов-противников, также представляющих «препятствие» при перемещении, алгоритм поиска A* оказался более гибким и эффективным, чем Алгоритм Дейкстры.
Основываясь на полученных данных, можно утверждать, что обучение с подкреплением является эффективным инструментом в задаче группового управления в условиях динамично изменяющихся характеристик внешней среды. Таким образом, обучение с подкреплением будет эффективно в задачах, связанных с проектированием роботов различного назначения, от боевых роботов, до роботов-уборщиков, для которых человек или домашнее животное, являются динамичным препятствием.
Библиография
1. Sutton R.S., Barto A.G. Reinforcement Learning. An Introduction.-The MIT Press, 1998, 322 p.
2. Хайкин С. Нейронные сети. Полный курс.-М.: Вильямс, 2006, с. 1104.
3. Плахов, А. С. КРИ / А. С. Плахов // Организация разработки AI для стратегических игр[Электронный ресурс].- 2004. Режим доступа: http://masters.donntu.org/2014/fknt/kebikov/library/article6.htm
4. Шампандар, Дж. А. Искуственный интеллект в компьютерных играх / Дж. А. Шампандар.-М.: Вильямс, 2007.-768 стр.
5. В.В. Круглов, B.В. Борисов. Искусственные нейронные сети. Теория и практика /-М.: Горячая линия-Телеком, 2001.-382 с.
6. К.В. Картавцев, О.Н. Мелехова, С.В. Тимченко. Модель детерминированной сети роботов. // Доклады Томского государственного университета систем управления и радиоэлектроники – 2010, 1-1(21), 85-88 с.
7. Барский А.Б. Логические нейронные сети. М.: Бином, 2007, 352 с.
8. Л. Н. Ясницкий — Введение в искусственный интеллект, 25 с.
9. Горбачевская Е.Н. Классификация нейронных сетей. // Вестник Волжского университета им. В.Н. Татищева – 2012, 2(19), 35-41 с.
10. Соколов Д.О. Применение двухэтапного генетического программирования для построения автомата, управляющего моделью танка в игре «Robocode»[Электронный ресурс]. Бакалаврская работа.-СПбГУ ИТМО, 2009. Режим доступа: http://ntv.ifmo.ru/ru/article/263/primenenie_dvuhetapnogo_geneticheskogo_programmirovaniya_dlya_postroeniya_modeli_tanka_v_igre_%C2%ABROBOCODE%C2%BB.htm.
11. Ч.И. Игоревич. Применение машинного обучения для создания управляющих автоматов на примере игры Robocode.[Электронный ресурс], Режим доступа: http://ntv.ifmo.ru/file/article/264.pdf
12. Сандра Блейксли, Джефф Хокинс «Об интеллекте»: Издательский дом «Вильямс»; Москва-Санкт-Петербург-Киев; 2007 ISBN ISBN 978-5-8459-1139-1 (рус.), ISBN 0-8050-7456-2 (англ.), 240 с.
13. Новый ум короля. О компьютерах, мышлении и законах физики. Роджер Пенроуз, 1989. Издательство Оксфордского университета, с. 480, ISBN: 0-19-851973-7 (1-е изд.), 402 с.
14. Дж. Баррат. Последнее изобретение человечества. Искусственный интеллект и конец эры Homo sapiens. 2015, 312 с.
References
1. Sutton R.S., Barto A.G. Reinforcement Learning. An Introduction.-The MIT Press, 1998, 322 p.
2. Khaikin S. Neironnye seti. Polnyi kurs.-M.: Vil'yams, 2006, s. 1104.
3. Plakhov, A. S. KRI / A. S. Plakhov // Organizatsiya razrabotki AI dlya strategicheskikh igr[Elektronnyi resurs].- 2004. Rezhim dostupa: http://masters.donntu.org/2014/fknt/kebikov/library/article6.htm
4. Shampandar, Dzh. A. Iskustvennyi intellekt v komp'yuternykh igrakh / Dzh. A. Shampandar.-M.: Vil'yams, 2007.-768 str.
5. V.V. Kruglov, B.V. Borisov. Iskusstvennye neironnye seti. Teoriya i praktika /-M.: Goryachaya liniya-Telekom, 2001.-382 s.
6. K.V. Kartavtsev, O.N. Melekhova, S.V. Timchenko. Model' determinirovannoi seti robotov. // Doklady Tomskogo gosudarstvennogo universiteta sistem upravleniya i radioelektroniki – 2010, 1-1(21), 85-88 s.
7. Barskii A.B. Logicheskie neironnye seti. M.: Binom, 2007, 352 s.
8. L. N. Yasnitskii — Vvedenie v iskusstvennyi intellekt, 25 s.
9. Gorbachevskaya E.N. Klassifikatsiya neironnykh setei. // Vestnik Volzhskogo universiteta im. V.N. Tatishcheva – 2012, 2(19), 35-41 s.
10. Sokolov D.O. Primenenie dvukhetapnogo geneticheskogo programmirovaniya dlya postroeniya avtomata, upravlyayushchego model'yu tanka v igre «Robocode»[Elektronnyi resurs]. Bakalavrskaya rabota.-SPbGU ITMO, 2009. Rezhim dostupa: http://ntv.ifmo.ru/ru/article/263/primenenie_dvuhetapnogo_geneticheskogo_programmirovaniya_dlya_postroeniya_modeli_tanka_v_igre_%C2%ABROBOCODE%C2%BB.htm.
11. Ch.I. Igorevich. Primenenie mashinnogo obucheniya dlya sozdaniya upravlyayushchikh avtomatov na primere igry Robocode.[Elektronnyi resurs], Rezhim dostupa: http://ntv.ifmo.ru/file/article/264.pdf
12. Sandra Bleiksli, Dzheff Khokins «Ob intellekte»: Izdatel'skii dom «Vil'yams»; Moskva-Sankt-Peterburg-Kiev; 2007 ISBN ISBN 978-5-8459-1139-1 (rus.), ISBN 0-8050-7456-2 (angl.), 240 s.
13. Novyi um korolya. O komp'yuterakh, myshlenii i zakonakh fiziki. Rodzher Penrouz, 1989. Izdatel'stvo Oksfordskogo universiteta, s. 480, ISBN: 0-19-851973-7 (1-e izd.), 402 s.
14. Dzh. Barrat. Poslednee izobretenie chelovechestva. Iskusstvennyi intellekt i konets ery Homo sapiens. 2015, 312 s.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования – разработка метода, решающего задачу адаптивного мультиагентного управления / группового взаимодействия агентов в динамично изменяющейся среде (на примере игры «Battlecode»).
Методология исследования основана на имитационном моделировании (включая анализ, классификацию, прогнозирование, статистические методы) с применением ряда алгоритмов группового управления (SWARM, муравьиный алгоритм, пчелиный алгоритм, алгоритм светлячков и алгоритм движения косяка рыб), обучения искусственной нейронной сети.
Актуальность решения задач группового управления автономными агентами (синхронизация, диспетчеризация, достижение консенсуса / согласование характеристик, рандеву, распределенное управление формациями и пр.) связана с развитием беспилотных технологий (автомобилей, летательных дронов, подводных устройств, роботов-курьеров и пр.). В настоящее время удовлетворительные решения получены для ограниченного класса практически важных задач.
Научная новизна определяется полученными выводами о повышении эффективности Q-обучения при замене табличного представления Q-функции нейронной сетью. Показано, что в решении задачи исследования и патрулирования местности наилучшие результаты получаются при использовании пчелиного алгоритма (по сравнению с SWARM, муравьиным алгоритмом, алгоритмами светлячков и движения косяка рыб) и алгоритма поиска пути А* (по сравнению с алгоритмом Дейкстры).
Стиль изложения научный. Структура работы включает следующие разделы: Введение, Постановка задачи, Предлагаемый метод, Результаты экспериментов, Заключение, Библиография. Содержание соответствует названию. Раздел «Результаты экспериментов» необходимо расширить, дополнив текст обсуждением полученных результатов – как между собой (как минимум), так и (желательно) с моделями, исследованными другими авторами. При этом часть текста можно перенести в данный раздел из Заключения, оставив в Заключении основные выводы.
Рукопись проиллюстрирована двумя рисунками. Ссылки на рисунки в предшествующем тексте отсутствуют. Рисунок 2 следует представить на русском языке либо сопроводить переводом (в пояснениях либо предшествующем тексте).
Имеется ряд опечаток: самообучение модкли управления – самообучение модели управления; наиболее эффективных алгоритмов групповго управления – наиболее эффективных алгоритмов группового управления; Автор показывет, что – Автор показывает, что; нейронные сети разделяются на полносвязанные – нейронные сети разделяются на полносвязные; чем Алгоритм Дейкстры – чем алгоритм Дейкстры. Следует принять единообразное написание: «Battlecode» либо «BattleCode». В нумерованных списках после цифры желательно использовать скобку – 1), 2), 3) и т.д.
Библиография включает 14 источников отечественных и зарубежных авторов – монографии, научные статьи, выпускные квалификационные работы. Библиографические описания источников составлены с отклонениями от ГОСТ, что необходимо исправить (для книг – фамилия, затем инициалы автора / авторов; место издания, издательство, год издания, общее число страниц; для периодических издания – номер тома / выпуска, страницы начала и окончания статьи; страница – с.). Следует также привести ссылку на Интернет-портал игры «Battlecode».
Апелляция к оппонентам отсутствует. Необходимо проставить по тексту рукописи ссылки на используемые источники, обратив особое внимание на обсуждение полученных результатов в сравнении с работами иных авторов.
После доработки рукопись может быть рассмотрена на предмет публикации в журнале «Кибернетика и программирование».
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|





