|
Ęčáĺđíĺňčęŕ č ďđîăđŕěěčđîâŕíčĺ
Ďđŕâčëüíŕ˙ ńńűëęŕ íŕ ńňŕňüţ:
Đĺâíčâűő Ŕ.Â., Âĺëčćŕíčí Ŕ.Ń.
Ěĺňîäčęŕ ŕâňîěŕňčçčđîâŕííîăî ôîđěčđîâŕíč˙ ńňđóęňóđű äčçŕńńĺěáëčđîâŕííîăî ëčńňčíăŕ
// Ęčáĺđíĺňčęŕ č ďđîăđŕěěčđîâŕíčĺ.
2019. ą 2.
Ń. 1-16.
DOI: 10.25136/2644-5522.2019.2.28272 URL: https://nbpublish.com/library_read_article.php?id=28272
Ěĺňîäčęŕ ŕâňîěŕňčçčđîâŕííîăî ôîđěčđîâŕíč˙ ńňđóęňóđű äčçŕńńĺěáëčđîâŕííîăî ëčńňčíăŕ
Đĺâíčâűő Ŕëĺęńŕíäđ Âëŕäčěčđîâč÷
ęŕíäčäŕň ňĺőíč÷ĺńęčő íŕóę
äîöĺíň, ęŕôĺäđŕ Číôîđěŕöčîííîé áĺçîďŕńíîńňč, ÔĂÁÎÓ ÂÎ «Íîâîńčáčđńęčé ăîńóäŕđńňâĺííűé óíčâĺđńčňĺň ýęîíîěčęč č óďđŕâëĺíč˙ «ÍČÍŐ»
630099, Đîńńč˙, Íîâîńčáčđńęŕ˙ îáëŕńňü, ă. Íîâîńčáčđńę, óë. Ęŕěĺíńęŕ˙, 56
Revnivykh Aleksandr Vladimirovich
PhD in Technical Science
Associate Professor, Department of Information Security, Novosibirsk State University of Economics and Management
630099, Russia, Novosibirskaya oblast', g. Novosibirsk, ul. Kamenskaya, 56

|
al.revnivykh@mail.ru
|
|
 |
Äđóăčĺ ďóáëčęŕöčč ýňîăî ŕâňîđŕ
|
|
|
Âĺëčćŕíčí Ŕíŕňîëčé Ńĺđăĺĺâč÷
Ńďĺöčŕëčńň, ÔĂÁÎÓ ÂÎ «Ňţěĺíńęčé číäóńňđčŕëüíűé óíčâĺđńčňĺň»»
625000, Đîńńč˙, Ňţěĺíńęŕ˙ îáëŕńňü, ă. Ňţěĺíü, óë. Âîëîäŕđńęîăî, 38
Velizhanin Anatolii Sergeevich
Specialist, Tyumen Industrial University
625000, Russia, Tyumenskaya oblast', g. Tyumen', ul. Volodarskogo, 38
|
|
anatoliy.velizhanin@gmail.com
|
|
|
Äđóăčĺ ďóáëčęŕöčč ýňîăî ŕâňîđŕ
|
|
|
DOI: 10.25136/2644-5522.2019.2.28272
Äŕňŕ íŕďđŕâëĺíč˙ ńňŕňüč â đĺäŕęöčţ:
05-12-2018
Äŕňŕ ďóáëčęŕöčč:
25-12-2018
Ŕííîňŕöč˙:
Ďđĺäěĺň čńńëĺäîâŕíč˙ – ěĺňîäčęŕ đŕçáčĺíč˙ äčçŕńńĺěáëčđîâŕííîăî ęîäŕ íŕ ëîăč÷ĺńęčĺ áëîęč â ŕâňîěŕňč÷ĺńęîě đĺćčěĺ, ďîčńę ó˙çâčěîńňĺé ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ áĺç čńďîëüçîâŕíč˙ čńőîäíîăî ęîäŕ (ń čńďîëüçîâŕíčĺě áčíŕđíîăî ôŕéëŕ ëčáî ĺăî ýęâčâŕëĺíňŕ, ďîëó÷ĺííîăî đĺâĺđń-číćčíčđčíăîě). Îáúĺęňîě čńńëĺäîâŕíč˙ ˙âë˙ţňń˙ ńóůĺńňâóţůčĺ ŕíŕëčçŕňîđű ęîäŕ č îńîáĺííîńňč čő ôóíęöčîíŕëŕ. Öĺëüţ čńńëĺäîâŕíč˙ ˙âë˙ĺňń˙ đŕńńěîňđĺňü âîçěîćíîńňü đŕçáčĺíč˙ äčçŕńńĺěáëčđîâŕííîăî ęîäŕ íŕ ëîăč÷ĺńęčĺ áëîęč â ŕâňîěŕňč÷ĺńęîě đĺćčěĺ č íĺęîňîđűĺ ńâ˙çŕííűĺ ń ýňčě âîçěîćíűĺ ńëîćíîńňč. Ďîńňŕíîâęŕ ďđîáëĺěű. Ńëîćíîńňü ŕíŕëčçŕ áîëüřčő ďđîăđŕěěíűő ďđîäóęňîâ íŕ óđîâíĺ ěŕřčííîăî ęîäŕ îáóńëŕâëčâŕĺň íĺîáőîäčěîńňü ŕâňîěŕňčçŕöčč äŕííîăî ďđîöĺńńŕ. Ěĺňîäîëîăč˙ čńńëĺäîâŕíč˙ îńíîâŕíŕ íŕ ńî÷ĺňŕíčč ňĺîđĺňč÷ĺńęîăî č ýěďčđč÷ĺńęîăî ďîäőîäîâ ń ďđčěĺíĺíčĺě ěĺňîäîâ ńňŕňč÷ĺńęîăî č äčíŕěč÷ĺńęîăî ŕíŕëčçŕ, ńđŕâíĺíč˙, îáîáůĺíč˙, ŕëăîđčňěčçŕöčč, ěîäĺëčđîâŕíčč, ńčíňĺçŕ. Ęëţ÷ĺâűĺ âűâîäű. Đŕçáčĺíčĺ ęîäŕ íŕ áëîęč ďóňĺě ďîńëĺäîâŕňĺëüíîăî â đĺćčěĺ «ńňđî÷ęŕ çŕ ńňđî÷ęîé» ŕíŕëčçŕ ěŕřčííîăî ęîäŕ â íĺęîňîđűő ńëó÷ŕ˙ő ěîćĺň ďđčâĺńňč ę íĺâĺđíîé číňĺđďđĺňŕöčč. Ęđîěĺ ňîăî, ŕíŕëčç ęîäŕ ńîăëŕńíî âűâîäŕě ôóíęöčé ňŕę ćĺ íĺ ăŕđŕíňčđóĺň ďđŕâčëüíîńňč îďđĺäĺëĺíč˙ ăđŕíčö ôóíęöčé. Îäíŕęî â öĺëîě ěŕňđč÷íűé ěĺňîä ěîćĺň áűňü ďđčěĺíĺí äë˙ ŕíŕëčçŕ çŕâčńčěîńňĺé ôóíęöčé ďî âűäĺëĺííűě ňŕęčě îáđŕçîě áëîęŕě ęîäŕ. Íŕó÷íŕ˙ íîâčçíŕ ńâ˙çŕíŕ ń îďđĺäĺëĺíčĺě ŕâňîđîě ďĺđńďĺęňčâíűő âĺęňîđîâ čńńëĺäîâŕíč˙ ďđîăđŕěěíîăî ęîäŕ íŕ ó˙çâčěîńňč, îáîńíîâŕíčĺě ďîäőîäŕ (ďîńňđîĺíčĺ ěŕňđčöű ďĺđĺőîäîâ čç öĺëî÷čńëĺííűő çíŕ÷ĺíčé), ęîňîđűé ěîćĺň ˙âë˙ňüń˙ íŕ÷ŕëüíîé ńňŕäčĺé ďîäăîňîâęč ę ŕâňîěŕňčçčđîâŕííîěó ŕíŕëčçó äčçŕńńĺěáëčđîâŕííîăî ęîäŕ.
Ęëţ÷ĺâűĺ ńëîâŕ:
Číôîđěŕöčîííŕ˙ áĺçîďŕńíîńňü, Ó˙çâčěîńňč, Ŕíŕëčç ęîäŕ, Äčçŕńńĺěáëčđîâŕíčĺ, Ęîěďčë˙ňîđ FASM, Óňčëčňŕ IDA Pro, Ěŕňđčöŕ ńěĺćíîńňč, Ěŕňđč÷íűé ěĺňîä, Áëîęč ęîäŕ, Ŕëăîđčňě ďîńňđîĺíč˙ ěŕňđčöű
Abstract: The subject of the research is the method of splitting a disassembled code into logical blocks in automatic mode, searching for software vulnerabilities without using source code (using a binary file or its equivalent, obtained by reverse engineering).The object of the research is the existing code analyzers and features of their functionality.The aim of the study is to consider the possibility of splitting a disassembled code into logical blocks in automatic mode and some of the possible difficulties associated with this.Formulation of the problem. The complexity of analyzing large software products at the level of machine code necessitates the automation of this process. The research methodology is based on a combination of theoretical and empirical approaches using the methods of static and dynamic analysis, comparison, generalization, algorithmization, modeling, synthesis. Key findings. Splitting the code into blocks by sequential in line-by-line analysis of machine code in some cases can lead to misinterpretation. In addition, the analysis of the code according to the conclusions of the functions also does not guarantee the correctness of the determination of the boundaries of the functions. However, in general, the matrix method can be applied to analyze the dependencies of functions on the blocks of code thus selected.The scientific novelty is connected with the determination of promising vectors for the study of software code for vulnerability, the rationale for the approach (building the transition matrix from integer values), which may be the initial stage of preparation for the automated analysis of the disassembled code.
Keywords: Information security, Vulnerabilities, Code analyses, Disassembling, FASM compiler, IDA Pro utility, Adjacency matrix, Matrix method, Code blocks, Matrix building algorithm
Ââĺäĺíčĺ
1. Ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ (ĎÎ), đŕçíîîáđŕçčĺ ŕďďŕđŕňíűő ŕđőčňĺęňóđ č ňĺőíîëîăčé ďđîăđŕěěčđîâŕíč˙
Đŕçëč÷íîĺ ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ ńňŕëî íĺîňúĺěëĺěîé ÷ŕńňüţ ôŕęňč÷ĺńęč âńĺő ńôĺđ íŕřĺé ćčçíč. Ýňî îáóńëîâëĺíî řčđîęčě âíĺäđĺíčĺě đŕçëč÷íîăî číôîđěŕöčîííî-âű÷čńëčňĺëüíîăî îáîđóäîâŕíč˙ ďđŕęňč÷ĺńęč âî âńĺ îáëŕńňč äĺ˙ňĺëüíîńňč ÷ĺëîâĺęŕ. Ďđčěĺđŕěč ęîěďüţňĺđíűő ńčńňĺě ˙âë˙ţňń˙ îáű÷íűĺ ďĺđńîíŕëüíűĺ ęîěďüţňĺđű, ńĺđâĺđŕ, ěîáčëüíűĺ ňĺëĺôîíű, âńňđŕčâŕĺěűĺ ńčńňĺěű, ŕ ňŕęćĺ ěíîăîĺ äđóăîĺ. Ńîâđĺěĺííűĺ ěčęđîďđîöĺńńîđű ďîńňđîĺíű íŕ đŕçëč÷íűő ďđčíöčďŕő. Ýňî ŕđőčňĺęňóđű Intel x86, Intel x64, AMD64, Intel Itanium, ARM č ň. ď. Ęŕćäŕ˙ čç ŕđőčňĺęňóđ čěĺĺň ńâîč îńîáĺííîńňč č ďđčíöčďű ńîçäŕíč˙ č ôóíęöčîíčđîâŕíč˙ ďđîăđŕěěíűő ęîěďîíĺíňîâ â íĺé. Đŕçíîîáđŕçčĺ ŕďďŕđŕňíűő ŕđőčňĺęňóđ č ňĺőíîëîăčé ďđîăđŕěěčđîâŕíč˙ ôîđěčđóĺň ńëîćíóţ ăĺňĺđîăĺííóţ ńňđóęňóđó ńîâđĺěĺííűő číôîđěŕöčîííî-âű÷čńëčňĺëüíűő ńčńňĺě, ˙âë˙ţůčőń˙ áîëüřčěč ďđîăđŕěěíî-ŕďďŕđŕňíűěč ęîěďëĺęńŕěč.
2. Îáçîđ ňĺíäĺíöčé đŕçâčňč˙ ňĺőíîëîăčé đŕçđŕáîňęč ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙
2.1. Ňĺőíîëîăčč ńîçäŕíč˙ ďđîăđŕěěíűő đĺřĺíčé, ňĺőíîëîăčč Rapid Application Development
Ńëĺäóĺň îňěĺňčňü, ÷ňî ňĺőíîëîăčé ńîçäŕíč˙ ďđîăđŕěěíűő đĺřĺíčé ňŕę ćĺ čěĺĺňń˙ ěíîćĺńňâî, ÷ňî îáóńëîâëĺíî đŕçëč÷íűěč ďîňđĺáíîńň˙ěč ęîíĺ÷íűő ďîëüçîâŕňĺëĺé č çŕäŕ÷ŕěč, ęîňîđűĺ áűëč ďîńňŕâëĺíű ďĺđĺä ďđîăđŕěěčńňîě. Ęđîěĺ ňîăî, â ďîńëĺäíĺĺ âđĺě˙ âńĺ áîëüřĺĺ đŕńďđîńňđŕíĺíčĺ ďîëó÷ŕţň ňĺőíîëîăčč RAD (Rapid Application Development) — áűńňđîé đŕçđŕáîňęč ďđîăđŕěěíűő đĺřĺíčé. Ďđč÷číîé ýňîăî ˙âë˙ĺňń˙ ďîňđĺáíîńňü ďđîčçâîäčňĺëĺé ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ â ńîęđŕůĺíčč ńđîęîâ ďđîčçâîäńňâŕ ďî ýęîíîěč÷ĺńęčě ďđč÷číŕě. Ňŕęčě îáđŕçîě, ń ňĺ÷ĺíčĺě âđĺěĺíč, âńĺ áîëüřĺĺ ÷čńëî ďđîčçâîäčňĺëĺé ďđîăđŕěěíűő ńčńňĺě ńňŕđŕţňń˙ ęŕę ěîćíî äŕëüřĺ ŕáńňđŕăčđîâŕňüń˙ îň äĺňŕëĺé ôóíęöčîíčđîâŕíč˙ ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ â öĺëĺâîé îďĺđŕöčîííîé ńčńňĺěĺ č ńäĺëŕňü ěŕęńčěŕëüíűé óďîđ čěĺííî íŕ ńîęđŕůĺíčĺ ńđîęîâ ďđîčçâîäńňâŕ.
2.2. Ęđŕňęčé îáçîđ čńňîđčč ˙çűęîâ ďđîăđŕěěčđîâŕíč˙
Áĺăëî đŕńńěîňđčě čńňîđčţ ˙çűęîâ ďđîăđŕěěčđîâŕíč˙ íŕ íĺńęîëüęčő ďđčěĺđŕő.
2.2.1. Assembler
Íŕ ńěĺíó ďđîăđŕěěčđîâŕíčţ íĺďîńđĺäńňâĺííî â ěŕřčííűő ęîäŕő ďđčřĺë ˙çűę Assembler, ęëţ÷ĺâűĺ ńëîâŕ ęîňîđîăî, ďî ńóňč ńâîĺé, ˙âë˙ţňń˙ ýęâčâŕëĺíňŕěč ěŕřčííűő číńňđóęöčé. Äŕííűé ˙çűę ďîçâîëčë íĺńęîëüęî óďđîńňčňü ďđîöĺńń ńîçäŕíč˙ ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ č ńäĺëŕňü ÷ňĺíčĺ č íŕďčńŕíčĺ ďđîăđŕěěíűő ëčńňčíăîâ óäîáíĺĺ äë˙ ÷ĺëîâĺęŕ.
2.2.2. ßçűęč ďđîăđŕěěčđîâŕíč˙ Ń č Ń++. Ňđŕíńë˙öč˙ ďđîăđŕěěíîăî ęîäŕ, íŕďčńŕííîăî íŕ âűńîęîóđîâíĺâűő ˙çűęŕő ďđîăđŕěěčđîâŕíč˙, â ěŕřčííűĺ číńňđóęöčč
Çíŕ÷čňĺëüíî ďîçćĺ ďî˙âčëń˙ ˙çűę ďđîăđŕěěčđîâŕíč˙ C (â ęîíöĺ 1970-ő ăîäîâ), ďîçâîë˙ţůčé íĺ ňîëüęî ńîęđŕňčňü âđĺě˙ ďđîčçâîäńňâŕ ďđîăđŕěěíűő đĺřĺíčé ďî ńđŕâíĺíčţ ń Assembler, íî č ďđĺäîńňŕâë˙ţůčé âîçěîćíîńňü ńáîđęč ďđîăđŕěěű áĺç ěîäčôčęŕöčč (ďđč óńëîâčč, ÷ňî ďđîăđŕěěŕ íĺ čńďîëüçóĺň ęîä ďëŕňôîđěĺííî-çŕâčńčěűő ęîěďîíĺíňîâ č ň. ď.) ďîä äđóăîé ŕđőčňĺęňóđîé, ŕ ňŕę ćĺ ďđĺäëŕăŕţůčé áîëĺĺ óäîáíűé äë˙ ďîíčěŕíč˙ ÷ĺëîâĺęîě ńčíňŕęńčń, ŕáńňđŕăčđó˙ ďđîăđŕěěčńňŕ îň ěíîăčő äĺňŕëĺé ôóíęöčîíčđîâŕíč˙ ěčęđîďđîöĺńńîđŕ. Íŕ ňîň ěîěĺíň ýňî áűë ńâîĺăî đîäŕ ďđîđűâ â đŕçâčňčč ˙çűęîâ ďđîăđŕěěčđîâŕíč˙. Íĺńęîëüęî ďîçćĺ ďî˙âčëŕńü čäĺ˙ îáúĺęňíî-îđčĺíňčđîâŕííîăî ďîäőîäŕ ę đŕçđŕáîňęĺ ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙, ÷ňî ďđčâĺëî ę ńîçäŕíčţ ˙çűęŕ ďđîăđŕěěčđîâŕíč˙ Ń++.
Ďđîăđŕěěű, ńîçäŕííűĺ íŕ C/C++, â đ˙äĺ ńčňóŕöčé ôóíęöčîíčđóţň ěĺäëĺííĺĺ, ÷ĺě ŕíŕëîăč÷íűĺ ďđîăđŕěěű, íŕďčńŕííűĺ íŕ Assembler. Ńâ˙çŕíî ýňî â ňîě ÷čńëĺ ń óâĺëč÷ĺíčĺě ôŕęňč÷ĺńęč čńďîëí˙ĺěîăî ďđîöĺńńîđîě îáúĺěŕ ęîäŕ. Ňŕę, ďđîăđŕěěŕ, íŕďčńŕííŕ˙ íŕ ˙çűęĺ Assembler, â áčíŕđíîě ďđĺäńňŕâëĺíčč çŕ÷ŕńňóţ çíŕ÷čňĺëüíî ěĺíüřĺ, ÷ĺě ŕíŕëîăč÷íŕ˙ ďđîăđŕěěŕ, íŕďčńŕííŕ˙ íŕ ˙çűęĺ ďđîăđŕěěčđîâŕíč˙ C/C++. Őîň˙ äŕííîĺ óňâĺđćäĺíčĺ íĺ âńĺăäŕ ńďđŕâĺäëčâî ďđč ńđŕâíĺíčč îňäĺëüíűő ôóíęöčîíŕëüíűő áëîęîâ, íŕďđčěĺđ, öčęëŕ ń ďđčđŕůĺíčĺě ďĺđĺěĺííîé ďî îďđĺäĺëĺííîěó óńëîâčţ. Çŕ÷ŕńňóţ áîëüřčé îáúĺě ěŕřčííîăî ęîäŕ ďîńëĺ ęîěďčë˙öčč čç âűńîęîóđîâíĺâűő ˙çűęîâ ďđîăđŕěěčđîâŕíč˙ ńâ˙çŕí ń âęëţ÷ĺíčĺě äîďîëíčňĺëüíűő ďîäęëţ÷ŕĺěűő ôŕéëîâ, őđŕí˙ůčő, íŕďđčěĺđ, čńďîëüçóĺěűĺ ęëŕńńű Ń++, ęîňîđűĺ çŕ÷ŕńňóţ ńîäĺđćŕň čçëčříčé (äë˙ äŕííîé ęîíęđĺňíîé çŕäŕ÷č) ôóíęöčîíŕë.
Ňŕęčě îáđŕçîě, ňđŕíńë˙öč˙ îňäĺëüíűő ÷ŕńňĺé ďđîăđŕěěíîăî ęîäŕ, íŕďčńŕííîăî íŕ âűńîęîóđîâíĺâűő ˙çűęŕő ďđîăđŕěěčđîâŕíč˙, â ěŕřčííűĺ číńňđóęöčč, ěîćĺň ďđčâîäčňü ę ôîđěčđîâŕíčţ çíŕ÷čňĺëüíî áîëĺĺ îáúĺěíîăî č, îň÷ŕńňč, čçáűňî÷íîăî ęîäŕ, íĺćĺëč íĺďîńđĺäńňâĺííîĺ íŕďčńŕíčĺ ĺăî íŕ ˙çűęĺ Assembler. Îäíŕęî íĺ âî âńĺő ńëó÷ŕ˙ő ęîä, íŕďčńŕííűé íŕ C/C++, âűďîëí˙ĺňń˙ äîëüřĺ [1]. Íŕďđčěĺđ, číńňđóęöčč ďĺđĺőîäŕ ÷ŕůĺ âńĺăî ňđŕíńëčđóţňń˙ â ńîîňâĺňńňâóţůčĺ ěŕřčííűĺ číńňđóęöčč č çŕ÷ŕńňóţ íĺ ôîđěčđóţň čçëčříčé ěŕřčííűé ęîä. Ęđîěĺ ňîăî, íŕ ńęîđîńňü âűďîëíĺíč˙ ďđîăđŕěěű âëč˙ĺň č ńďîńîá âűďîëíĺíč˙ đŕçëč÷íűő çŕäŕ÷.  ÷ŕńňíîńňč, đŕçëč÷íűĺ ŕëăîđčňěű ěîăóň áűňü đĺŕëčçîâŕíű íĺńęîëüęčěč ńďîńîáŕěč íĺ ňîëüęî ń ňî÷ęč çđĺíč˙ ŕëăîđčňěč÷ĺńęîăî ďîńňđîĺíč˙, íî č ń ňî÷ęč çđĺíč˙ ďđčěĺí˙ĺěűő číńňđóęöčé ďđîöĺńńîđŕ äë˙ îđăŕíčçŕöčč ëîăčęč ôóíęöčîíčđîâŕíč˙ âűńîęîóđîâíĺâîăî ďđîăđŕěěíîăî ęîäŕ.
2.2.3. ßçűęč ďđîăđŕěěčđîâŕíč˙ Java, C#, JavaScript, Python, C# 4
ßçűęč ďđîăđŕěěčđîâŕíč˙ Java, C# č ň. ď. â ĺůĺ áîëüřĺé ńňĺďĺíč ŕáńňđŕăčđîâŕëč ďđîăđŕěěčńňŕ äŕćĺ îň ěĺőŕíčçěîâ óďđŕâëĺíč˙ ďŕě˙ňüţ, ďđĺäëîćčâ «ŕâňîěŕňč÷ĺńęóţ ńáîđęó ěóńîđŕ», ęîăäŕ âčđňóŕëüíŕ˙ ěŕřčíŕ ńŕěîńňî˙ňĺëüíî đĺřŕĺň ęŕęŕ˙ ďŕě˙ňü äîëćíŕ ďđîäîëćŕňü áűňü âűäĺëĺííîé, ŕ ęŕęóţ ěîćíî îńâîáîäčňü. Ęđîěĺ ňîăî, ěíîćĺńňâî ˙çűęîâ íŕďîäîáčĺ JavaScript, Python, C# 4 (â äčŕëĺęň čěĺííî ýňîé âĺđńčč äîáŕâëĺíî ęëţ÷ĺâîĺ ńëîâî dynamic) ďđĺäëŕăŕţň äčíŕěč÷ĺńęóţ ňčďčçŕöčţ, ÷ňî â ĺůĺ áîëüřĺé ńňĺďĺíč ŕáńňđŕăčđóĺň äŕćĺ îň ňĺőíîëîăčé ěĺćďđîöĺńńíîăî âçŕčěîäĺéńňâč˙, óďđîůŕĺň, íŕďđčěĺđ, óďđŕâëĺíčĺ OLE îáúĺęňŕěč č ň. ď.
Ńëĺäóĺň îňěĺňčňü, ÷ňî ęŕćäîĺ ďîńëĺäóţůĺĺ ďîęîëĺíčĺ ˙çűęîâ ďđîăđŕěěčđîâŕíč˙ âńĺ â áîëüřĺé ńňĺďĺíč óäŕë˙ĺň ďđîăđŕěěčńňŕ îň ëţáűő äĺňŕëĺé ôóíęöčîíčđîâŕíč˙ ęîěďüţňĺđíűő ńčńňĺě, ńîçäŕâŕ˙ ńâîĺîáđŕçíóţ «ďĺńî÷íčöó», â ęîňîđîé ęîěďčë˙ňîđ č ńđĺäŕ âűďîëíĺíč˙ ńëĺäčň çŕ ďđŕâčëüíîńňüţ ôóíęöčîíčđîâŕíč˙ áîëüřîăî ÷čńëŕ íčçęîóđîâíĺâűő îďĺđŕöčé [2]. Äŕííűé ôŕęň, íĺńîěíĺííî, ďîëîćčňĺëüíî ńęŕçűâŕĺňń˙ íŕ ńđîęŕő ďđîčçâîäńňâŕ ďđîăđŕěěíűő đĺřĺíčé íĺ ňîëüęî čç-çŕ ńîęđŕůĺíč˙ âđĺěĺíč, çŕňđŕ÷ĺííîăî íŕ đŕçđŕáîňęó, íî č çŕ ń÷ĺň ńîęđŕůĺíč˙ ÷čńëŕ ňđóäíî îáíŕđóćčâŕĺěűő îřčáîę â đŕçđŕáŕňűâŕĺěűő ďđîăđŕěěíűő ęîěďîíĺíňŕő (ŕ çíŕ÷čň č ńîęđŕůĺíč˙ âđĺěĺíč íŕ îňëŕäęó) áëŕăîäŕđ˙ ćĺńňęîěó ęîíňđîëţ ńî ńňîđîíű ęîěďčë˙ňîđŕ č îńîáĺííîńň˙ě ńčíňŕęńčńŕ ńŕěčő ˙çűęîâ ďđîăđŕěěčđîâŕíč˙. Ń äđóăîé ńňîđîíű, ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ (äŕëĺĺ – ĎÎ), đŕçđŕáîňŕííîĺ íŕ ďîäîáíűő ˙çűęŕő ďđîăđŕěěčđîâŕíč˙, âî ěíîăčő ńëó÷ŕ˙ő ôóíęöčîíčđóĺň çíŕ÷čňĺëüíî ěĺäëĺííĺĺ ŕíŕëîăč÷íűő ďđîăđŕěě, ńîçäŕííűő íŕ C/C++.
2.3. Ó˙çâčěîńňč
 ńëó÷ŕĺ íŕëč÷č˙ ó˙çâčěîńňč â ęŕęîé-ëčáî čç äčíŕěč÷ĺńęčő áčáëčîňĺę čńďîëí˙ţůĺé ńđĺäű čëč ďëŕňôîđěű, âîçíčęŕĺň âĺđî˙ňíîńňü ýęńďëóŕňŕöčč äŕííîé ó˙çâčěîńňč ďîńđĺäńňâîě ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙, ôóíęöčîíčđóţůĺăî â ó˙çâčěîé ńčńňĺěĺ. Ó÷čňűâŕ˙ ěŕńńîâîńňü đŕńďđîńňđŕíĺíč˙ íĺęîňîđűő ńđĺä čńďîëíĺíč˙ č ďëŕňôîđě (íŕďđčěĺđ, NET Framework âőîäčň â ńňŕíäŕđňíóţ ďîńňŕâęó ńîâđĺěĺííűő âĺđńčé Microsoft Windows), äŕííűé ôŕęň ěîćĺň ńňŕňü ęđčňč÷íűě [3]. Ęđîěĺ ňîăî, äîďîëíčňĺëüíűé ńëîé â âčäĺ âčđňóŕëüíîé ěŕřčíű ňŕę ćĺ ďîâűřŕĺň îáůóţ ńëîćíîńňü ôóíęöčîíčđîâŕíč˙ číôîđěŕöčîííî-âű÷čńëčňĺëüíîé ńčńňĺěű, ÷ňî ěîćĺň ďđčâĺńňč ę äîďîëíčňĺëüíűě ďđîáëĺěŕě číňĺăđŕöčč â č áĺç ňîăî ńëîćíóţ ńčńňĺěó [4].
Ďîěčěî ďđî÷ĺăî, ěíîăîĺ ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ čěĺĺň îáůčĺ áčáëčîňĺęč, đŕçđŕáŕňűâŕĺěűĺ ęŕę ęîěěĺđ÷ĺńęčěč îđăŕíčçŕöč˙ěč, ňŕę č îäčíî÷íűěč ďđîăđŕěěčńňŕěč. Çŕ÷ŕńňóţ äŕííűĺ áčáëčîňĺęč, ŕ ňŕę ćĺ ęëŕńńű, đŕçđŕáîňŕííűĺ ďđîăđŕěěčńňîě äë˙ ďđîřëîăî ďđîĺęňŕ, íŕőîä˙ň ďđčěĺíĺíčĺ â íîâűő ďđîĺęňŕő. Ňŕęčě îáđŕçîě, îäíč č ňĺ ćĺ ó˙çâčěîńňč ďĺđĺőîä˙ň îň îäíîăî ďđîăđŕěěíîăî ďđîĺęňŕ ę äđóăîěó [5], ÷ňî äĺëŕĺň âîçěîćíűě čő ýęńďëóŕňŕöčţ ëčřü ń íĺçíŕ÷čňĺëüíîé ěîäčôčęŕöčĺé ýęńďëîčňŕ.
2.4. Ňĺőíčęŕ çŕůčňű číňĺëëĺęňóŕëüíîé ńîáńňâĺííîńňč íŕ ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ, íŕďčńŕííîĺ íŕ ˙çűęŕő ďđîăđŕěěčđîâŕíč˙ ń Just In Time-ęîěďčë˙öčĺé
Îňäĺëüíűé âîďđîń ďđĺäńňŕâë˙ĺň ńîáîé č ňĺőíčęŕ çŕůčňű číňĺëëĺęňóŕëüíîé ńîáńňâĺííîńňč íŕ ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ, íŕďčńŕííîĺ íŕ ˙çűęŕő ďđîăđŕěěčđîâŕíč˙ ń JIT (Just In Time — ňî÷íî â ńđîę) ęîěďčë˙öčĺé. Ňŕę, ďđîăđŕěěű, íŕďčńŕííűĺ, íŕďđčěĺđ, íŕ C# ěîćíî íĺ ňîëüęî äĺęîěďčëčđîâŕňü îáđŕňíî â âűńîęîóđîâíĺâűé čńőîäíűé ęîä, íî č ńîáđŕňü â čńďîëí˙ĺěűé ôŕéë ńíîâŕ, áëŕăîäŕđ˙ ěĺňŕčíôîđěŕöčč, ńîőđŕí˙ĺěîé â čńďîëí˙ĺěűő ôŕéëŕő ęîěďčë˙ňîđîě. Ďđîăđŕěěű, íŕďčńŕííűĺ íŕ C++, äĺęîěďčëčđîâŕňü â ôóíęöčîíčđóţůčé č ńďîńîáíűé â äŕëüíĺéřĺě áűňü ńęîěďčëčđîâŕííűě ęŕęčě-ëčáî ęîěďčë˙ňîđîě ˙çűęŕ C/C++ âűńîęîóđîâíĺâűé ęîä äî ńčő ďîđ íĺ óäŕâŕëîńü, ďîńęîëüęó ôŕęňč÷ĺńęč âń˙ číôîđěŕöč˙ î ńňđóęňóđĺ ďđîăđŕěěű â őîäĺ ńáîđęč ňĺđ˙ĺňń˙ [6].
2.5. Ďđĺîáđŕçîâŕíčĺ äčçŕńńĺěáëčđîâŕííűő ëčńňčíăîâ č ěŕřčííîăî ęîäŕ. Native-ďđîăđŕěěíűĺ ęîěďîíĺíňű
Âĺäóňń˙ đŕçđŕáîňęč, íŕďđŕâëĺííűĺ íŕ ďđĺîáđŕçîâŕíčĺ äčçŕńńĺěáëčđîâŕííűő ëčńňčíăîâ č ěŕřčííîăî ęîäŕ â íĺęîĺ ďîäîáčĺ âűńîęîóđîâíĺâîăî ęîäŕ íŕ C/C++ (íŕďđčěĺđ, äčçŕńńĺěáëĺđ IDA Pro ńîäĺđćčň â ńĺáĺ ďîäîáíűé ôóíęöčîíŕë, ďđĺäîńňŕâë˙˙ ďńĺâäîęîä, íŕďîěčíŕţůčé ďî ńčíňŕęńčńó ęîä íŕ ˙çűęĺ ďđîăđŕěěčđîâŕíč˙ C/C++).
Íĺ ďîääŕţňń˙ ńáîđęĺ č äčçŕńńĺěáëčđîâŕííűĺ ęîäű áĺç çíŕ÷čňĺëüíîé ďđĺäâŕđčňĺëüíîé ěîäčôčęŕöčč. Ńëĺäóĺň îňěĺňčňü, ÷ňî íĺ ňîëüęî ďđîăđŕěěű, íŕďčńŕííűĺ íŕ ˙çűęĺ ďđîăđŕěěčđîâŕíč˙ C/C++, íĺ ďîääŕţňń˙ ňŕęîěó äĺęîěďčëčđîâŕíčţ â ńîîňâĺňńňâóţůčé âűńîęîóđîâíĺâűé ęîä. Íŕďđčěĺđ, đŕńńěŕňđčâŕ˙ îďĺđŕöčîííóţ ńčńňĺěó Microsoft Windows, ëţáîĺ ďđîăđŕěěíîĺ îáĺńďĺ÷ĺíčĺ, ńęîěďčëčđîâŕííîĺ â đĺćčěĺ Native (íĺďîńđĺäńňâĺííî â ěŕřčííűĺ ęîäű) íĺ ńěîćĺň áűňü ęŕ÷ĺńňâĺííî ďđĺîáđŕçîâŕíî â ńîîňâĺňńňâóţůčé âűńîęîóđîâíĺâűé ęîä, ŕ ëčřü âîçěîćíî ďîëó÷ĺíčĺ äčçŕńńĺěáëčđîâŕííűő ëčńňčíăîâ č ýëĺěĺíňîâ ďńĺâäîęîäŕ, ďđĺäëîćĺííűő, íŕďđčěĺđ, äčçŕńńĺěáëĺđîě IDA Pro.  ňî ćĺ âđĺě˙, ďđîäîëćŕ˙ ďđčěĺđ ń Microsoft Windows, ďđîăđŕěěű, íŕďčńŕííűĺ ďîä ďëŕňôîđěó. NET Framework, íŕďđčěĺđ, íŕ ˙çűęĺ ďđîăđŕěěčđîâŕíč˙ C#, ëĺăęî äĺęîěďčëčđóţňń˙ â ńîîňâĺňńňâóţůčé âűńîęîóđîâíĺâűé ęîä, íŕďđčěĺđ, ń ďîěîůüţ óňčëčňű .Net Reflector.
Äë˙ Native ďđîăđŕěěíűő ęîěďîíĺíňîâ â áîëüřčíńňâĺ ńëó÷ŕĺâ îáúĺě íĺîáőîäčěîé äë˙ âűďîëíĺíč˙ ęîěďčë˙öčč äčçŕńńĺěáëčđîâŕííűő ëčńňčíăîâ ěîäčôčęŕöčč ÷đĺçâű÷ŕéíî âĺëčę. Îäíŕęî, äŕćĺ â ńëó÷ŕĺ đó÷íîăî ôîđěčđîâŕíč˙ ęîäŕ, ńďîńîáíîăî áűňü ńîáđŕííűě â čńďîëí˙ĺěűé ôŕéë čç ďđĺäâŕđčňĺëüíî çíŕ÷čňĺëüíî îáđŕáîňŕííűő äčçŕńńĺěáëčđîâŕííűő ëčńňčíăîâ, íĺëüç˙ ăŕđŕíňčđîâŕňü ďđŕâčëüíîăî ôóíęöčîíčđîâŕíč˙ đĺçóëüňčđóţůĺăî čńďîëí˙ĺěîăî ôŕéëŕ, ŕ çíŕ÷čň č áîëüřîé âĺđî˙ňíîńňč ńîâĺđřĺíč˙ îřčáęč ďđč đó÷íîě čńďđŕâëĺíčč ęîäŕ [3, 7]. Ęđîěĺ ňîăî, â őîäĺ ńáîđęč, íŕńňđîéęč ęîěďčë˙ňîđŕ č ęîěďîíîâůčęŕ ěîăóň ďđčâĺńňč ę ôîđěčđîâŕíčţ íĺńęîëüęî îňëč÷íîăî ôŕéëŕ. Ňŕęćĺ, ńëîćíî óňâĺđćäŕňü, ÷ňî äčçŕńńĺěáëĺđ ŕáńîëţňíî áĺçîřčáî÷íî îáđŕáîňŕë äâîč÷íűé ôŕéë, đŕçěĺđű ęîňîđîăî ěîăóň áűňü íĺ îäíó ńîňíţ ěĺăŕáŕéň.
2.6. Ďđîčçâîäčňĺëüíîńňü, ˙äđî îďĺđŕöčîííîé ńčńňĺěű Linux
Íĺńěîňđ˙ íŕ řčđîęîĺ đŕńďđîńňđŕíĺíčĺ ˙çűęîâ ďđîăđŕěěčđîâŕíč˙ C#, Java, Python, JavaScript, ďđĺäîńňŕâë˙ţůčő ěíîćĺńňâî đŕçëč÷íűő ďđĺčěóůĺńňâ äë˙ ďđîăđŕěěčńňŕ, íĺęîňîđűé ôóíęöčîíŕë íĺâîçěîćíî čëč íĺýôôĺęňčâíî đĺřŕňü ń čő čńďîëüçîâŕíčĺě. Ďđč÷číŕěč ýňîěó ěîăóň áűňü, íŕďđčěĺđ, âîďđîńű ďđîčçâîäčňĺëüíîńňč. ßäđî îďĺđŕöčîííîé ńčńňĺěű Linux, ŕ ňŕęćĺ ěíîăčő äđóăčő îďĺđŕöčîííűő ńčńňĺě, íŕďčńŕíî íŕ ˙çűęĺ ďđîăđŕěěčđîâŕíč˙ Ń. Äë˙ ĺăî đĺŕëčçŕöčč, íŕďđčěĺđ, íŕ Java ďîňđĺáîâŕëîńü áű ńîçäŕíčĺ âčđňóŕëüíîé ěŕřčíű, ńďîńîáíîé đŕáîňŕňü áĺç îďĺđŕöčîííîé ńčńňĺěű č ńŕěîé, â ęŕęîě-ňî ńěűńëĺ, ˙âë˙ňüń˙ ńâîĺîáđŕçíîé îďĺđŕöčîííîé ńčńňĺěîé. Đĺŕëčçîâŕňü ňŕęóţ âčđňóŕëüíóţ ěŕřčíó áűëî áű âîçěîćíî ňîëüęî íŕ ˙çűęŕő ďđîăđŕěěčđîâŕíč˙, đĺçóëüňŕňîě îáđŕáîňęč ęîňîđűő ęîěďčë˙ňîđîě, ˙âë˙ĺňń˙ áčíŕđíűé ęîä ń ěŕřčííűěč číńňđóęöč˙ěč äë˙ äŕííîăî ěčęđîďđîöĺńńîđŕ. Čńęëţ÷ĺíčĺě ěîăóň áűňü ňîëüęî ńëó÷ŕč, ĺńëč ěčęđîďđîöĺńńîđ, íŕďđčěĺđ, âî âńňđîĺííîé ďŕě˙ňč čěĺë áű íĺáîëüřóţ âčđňóŕëüíóţ ěŕřčíó. Îäíŕęî â ňŕęîě ńëó÷ŕĺ, äŕííŕ˙ âčđňóŕëüíŕ˙ ěŕřčíŕ áóäĺň ńâîĺîáđŕçíîé ěčęđîîďĺđŕöčîííîé ńčńňĺěîé, đĺŕëčçóţůĺé áŕçîâűé îăđŕíč÷ĺííűé ôóíęöčîíŕë.
Ňŕęčě îáđŕçîě, íĺńěîňđ˙ íŕ íŕđŕńňŕţůóţ ňĺíäĺíöčţ â čńďîëüçîâŕíčč ˙çűęîâ ďđîăđŕěěčđîâŕíč˙ íŕďîäîáčĺ Java, C#, Python č ň. ď., ěű čěĺĺě ěíîćĺńňâî ďđîăđŕěěíűő đĺřĺíčé, đŕçđŕáîňŕííűő č ôóíęöčîíčđóţůčő ń čńďîëüçîâŕíčĺě ďđîăđŕěěíűő ěîäóëĺé, íŕďčńŕííűő íŕ ˙çűęŕő C/C++, Assembler č ň. ď., ôîđěčđóţůčő ěŕřčííűé ęîä â ďđîöĺńńĺ ńáîđęč đĺřĺíč˙.
3. Ďîäőîä ę ďîčńęó ó˙çâčěîńňĺé â ďđîăđŕěěíîě îáĺńďĺ÷ĺíčč áĺç čńďîëüçîâŕíč˙ čńőîäíîăî ęîäŕ
3.1. Îđčĺíňŕöč˙ íŕ áčíŕđíűé ôŕéë čëč ĺăî ýęâčâŕëĺíň, ďîëó÷ĺííűé đĺâĺđń-číćčíčđčíăîě. Fuzzing
Âŕćíűě ˙âë˙ĺňń˙ ďîčńę ó˙çâčěîńňĺé â ďđîăđŕěěíîě îáĺńďĺ÷ĺíčč, îđčĺíňčđó˙ńü íĺ íŕ čńőîäíűĺ ęîäű äŕííîăî ďđîăđŕěěíîăî ďđîäóęňŕ, ŕ čěĺííî íŕ ńŕě áčíŕđíűé ôŕéë čëč ĺăî ýęâčâŕëĺíň, ďîëó÷ĺííűé đĺâĺđń-číćčíčđčíăîě. Ęđîěĺ ňîăî, äë˙ ŕíŕëčçŕ ńîâđĺěĺííűő ďđîăđŕěěíűő đĺřĺíčé íĺîáőîäčě đ˙ä ńđĺäńňâ ŕâňîěŕňčçŕöčč ýňîăî ďđîöĺńńŕ. Íŕ ńĺăîäí˙říčé äĺíü, îäíčě čç đŕńďđîńňđŕíĺííűő ěĺňîäčę ďîčńęŕ ó˙çâčěîńňĺé â ĎÎ áĺç čńďîëüçîâŕíč˙ čńőîäíîăî ęîäŕ ˙âë˙ĺňń˙ Fuzzing [8]. Äŕííŕ˙ ěĺňîäčęŕ îńíîâŕíŕ íŕ ôîđěčđîâŕíčč âŕđčŕíňîâ âőîäíűő äŕííűő, ŕ çŕňĺě âíĺäđĺíčč čő â ęŕ÷ĺńňâĺ âőîäíűő äŕííűő â čńďîëí˙ĺěűé ôŕéë, â îćčäŕíčč íŕ âîçíčęíîâĺíčĺ čńęëţ÷ĺíč˙ â ďđîăđŕěěíîě ěîäóëĺ [9].
Äŕííŕ˙ ěĺňîäčęŕ äŕëŕ çíŕ÷čňĺëüíűĺ đĺçóëüňŕňű ńîăëŕńíî čńňî÷íčęŕě [8] č [10]. Îäíŕęî äë˙ đĺŕëčçŕöčč äŕííîé ěĺňîäčęč íĺîáőîäčěî çíŕňü ňî÷ęč âőîäŕ číôîđěŕöčîííűő ďîňîęîâ â ďđîöĺńń. Ďîäîáíîăî đîäŕ ňî÷ĺę âőîäŕ ěîćĺň áűňü âĺńüěŕ çíŕ÷čňĺëüíîĺ ęîëč÷ĺńňâî. Ýňî č îáű÷íűĺ âőîäíűĺ ďŕđŕěĺňđű, ďĺđĺäŕâŕĺěűĺ ÷ĺđĺç ęîěŕíäíóţ ńňđîęó, č čńďîëüçóĺěűĺ ďĺđĺěĺííűĺ îęđóćĺíč˙, č ěĺćďđîöĺńńíîĺ âçŕčěîäĺéńňâčĺ, ŕ ňŕęćĺ ěíîćĺńňâî äđóăčő âŕđčŕíňîâ âíĺäđĺíč˙ číôîđěŕöčč â čńďîëí˙ţůčéń˙ ďđîöĺńń. Ďîěčěî ďđî÷ĺăî, äŕííűé ďîäőîä íĺ ăŕđŕíňčđóĺň ďîëíîîáúĺěíîńňč ňĺńňčđîâŕíč˙. Ň. ĺ. âďîëíĺ âîçěîćíî č íŕëč÷čĺ íĺ ďđîňĺńňčđîâŕííűő âĺňîę ďîňîęŕ âűďîëíĺíč˙. Äŕííűé âîďđîń đŕńńěîňđĺí â đŕáîňĺ [10], ăäĺ ďđĺäëîćĺíű íĺęîňîđűĺ âŕđčŕíňű đĺřĺíč˙ äŕííîé ďđîáëĺěű.
Ňŕę ćĺ âŕćíî îňěĺňčňü, ÷ňî Fuzzing ńŕě ďî ńĺáĺ ˙âë˙ĺňń˙ âčäîě äčíŕěč÷ĺńęîăî ŕíŕëčçŕ, ŕ çíŕ÷čň ďđîăđŕěěíűé ěîäóëü, ďîäâĺđćĺííűé ňĺńňčđîâŕíčţ, çŕďóńęŕĺňń˙ â îďđĺäĺëĺííîé ńđĺäĺ, ęîňîđŕ˙ ěîćĺň îęŕçŕňü íĺďîńđĺäńňâĺííîĺ âëč˙íčĺ íŕ őîä âűďîëíĺíč˙ ňĺńňčđóĺěîé ďđîăđŕěěű, ŕ, ńëĺäîâŕňĺëüíî, č íŕ đĺçóëüňŕňű čńńëĺäîâŕíč˙ [11]. Äŕííűé ôŕęňîđ ěîćĺň íĺăŕňčâíî ńęŕçŕňüń˙ â ńëó÷ŕ˙ő, ęîăäŕ ęîëč÷ĺńňâî îďđĺäĺëĺííűő ňî÷ĺę âőîäŕ â čńńëĺäóĺěűé ďđîöĺńń ěĺíüřĺ, ÷ĺě čő đĺŕëüíîĺ ÷čńëî.
3.2. Ęđčňĺđčč âűáîđŕ âĺęňîđŕ čńńëĺäîâŕíč˙ äčçŕńńĺěáëčđîâŕííîăî ëčńňčíăŕ
3.2.1. Ďđĺäâŕđčňĺëüíűé ńňŕňč÷ĺńęčé ŕíŕëčç.
Îďđĺäĺëĺíčĺ ňî÷ĺę âőîäŕ â ďđîöĺńń ˙âë˙ĺňń˙ âŕćíîé çŕäŕ÷ĺé, ęîňîđŕ˙ ěîćĺň áűňü âűďîëíĺíŕ â őîäĺ ďđĺäâŕđčňĺëüíîăî ńňŕňč÷ĺńęîăî ŕíŕëčçŕ. Ňŕę ćĺ ńňŕňč÷ĺńęčé ŕíŕëčç ěîćĺň áűňü čńďîëüçîâŕí č äë˙ îďđĺäĺëĺíč˙ íŕčáîëĺĺ ďîäőîä˙ůĺăî íŕáîđŕ âőîäíűő äŕííűő, ŕ ňŕęćĺ íŕčáîëĺĺ číňĺđĺńíűő â ęŕćäîě ęîíęđĺňíîě ńëó÷ŕĺ âĺęňîđîâ čńńëĺäîâŕíč˙ [12]. Ňŕęčě îáđŕçîě, đĺçóëüňŕňű ńňŕňč÷ĺńęîăî ŕíŕëčçŕ ěîăóň áűňü čńďîëüçîâŕíű ďđč äčíŕěč÷ĺńęîě ŕíŕëčçĺ.
Ďîä âĺęňîđîě čńńëĺäîâŕíč˙ äčçŕńńĺěáëčđîâŕííîăî ëčńňčíăŕ áóäĺě ďîíčěŕňü íŕďđŕâëĺíčĺ č ďîńëĺäîâŕňĺëüíîńňü ďĺđĺőîäîâ, ďîňĺíöčŕëüíî îáđŕçóţůčő číňĺđĺńóţůčé íŕń ďîňîę âűďîëíĺíč˙. Íŕ ýňŕďĺ ńňŕňč÷ĺńęîăî ŕíŕëčçŕ ěű íĺ ěîćĺě ăŕđŕíňčđîâŕňü, ÷ňî âűďîëíĺíčĺ ęŕęîé-ëčáî îňäĺëüíîé âĺňęč â ęîäĺ ďî íŕďđŕâëĺíčţ äŕííîăî âĺęňîđŕ čńńëĺäîâŕíč˙ â óńëîâč˙ő ęŕęîé-ëčáî ęîíęđĺňíîé đĺŕëüíîé ńčńňĺěű áóäĺň âűďîëíĺíî [13].  çŕâčńčěîńňč îň öĺëč čńńëĺäîâŕíč˙ ěű ěîćĺě čěĺňü đŕçëč÷íűĺ âĺęňîđŕ čńńëĺäîâŕíč˙ äŕćĺ äë˙ îäíîăî č ňîăî ćĺ ďđîăđŕěěíîăî ěîäóë˙. Ňŕę, ĺńëč ěű ďűňŕĺěń˙ îáíŕđóćčňü ó˙çâčěîńňč íŕ ńđűâ ńňĺęŕ, ňî öĺëĺńîîáđŕçíĺĺ âűáđŕňü âĺęňîđ čńńëĺäîâŕíč˙, ęîňîđűé ďđčâĺäĺň ę ďđîőîäó ďî áîëüřĺěó ÷čńëó ďîňĺíöčŕëüíî îďŕńíűő ňî÷ĺę â ďđîăđŕěěĺ (ńđĺäč ňŕęčő ňî÷ĺę ěîăóň áűňü âűçîâű ôóíęöčé ńňŕíäŕđňíîé áčáëčîňĺęč ˙çűęŕ ďđîăđŕěěčđîâŕíč˙ Ń/Ń++, íŕďđčěĺđ, ňŕęčĺ, ęŕę strcpy č ň. ď.) [14]. Äë˙ îďđĺäĺëĺíč˙ âîçěîćíűő âĺęňîđîâ čńńëĺäîâŕíč˙ íŕ ýňŕďĺ ńňŕňč÷ĺńęîăî ŕíŕëčçŕ íĺîáőîäčěî ďđĺäâŕđčňĺëüíî ďîńňđîčňü ęŕđňó âűçîâîâ čńńëĺäóĺěîăî ěîäóë˙. Ďîä ęŕđňîé âűçîâîâ áóäĺě ďîíčěŕňü ďđĺäńňŕâëĺíčĺ (ňĺęńňîâîĺ, ăđŕôč÷ĺńęîĺ čëč ëţáîĺ äđóăîĺ), îňđŕćŕţůĺĺ ďîńëĺäîâŕňĺëüíîńňü âűçîâîâ ôóíęöčé. Ďîäîáíűĺ ęŕđňű âűçîâîâ ńňđî˙ň íĺęîňîđűĺ äčçŕńńĺěáëĺđű, íŕďđčěĺđ, IDA Pro (ăđŕôč÷ĺńęčé ďđčěĺđ îňđűâęŕ ęŕđňű âűçîâîâ čçîáđŕćĺí íŕ đčń. 1).
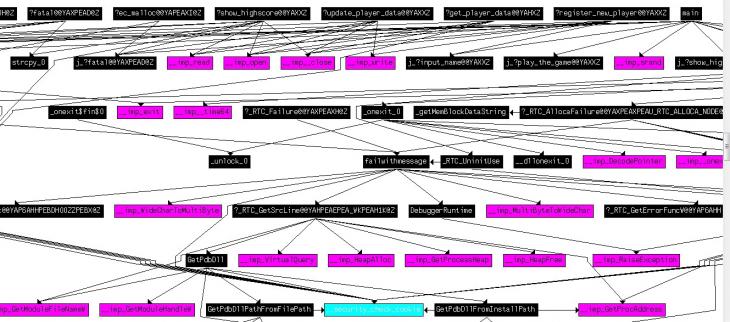
Đčń. 1.Ďđčěĺđ îňđűâęŕ ęŕđňű âűçîâîâ, ďîńňđîĺííűé ďđîăđŕěěîé IDA Pro
Ďîńňđîĺíčĺ ďîäîáíűő ęŕđň âűçîâîâ č îďđĺäĺëĺíč˙ äîńňčćčěîńňč ôóíęöčé ěîćĺň áűňü đĺŕëčçîâŕíî đŕçíűěč ńďîńîáŕěč.
3.2.2. Čńďîëüçîâŕíčĺ ěŕňĺěŕňč÷ĺńęčő ěŕňđčö
Îäíčě čç âŕđčŕíňîâ ˙âë˙ĺňń˙ čńďîëüçîâŕíčĺ ěŕňĺěŕňč÷ĺńęčő ěŕňđčö. Îďčđŕ˙ńü íŕ ňî, ÷ňî ęŕđňŕ âűçîâîâ ˙âë˙ĺňń˙ ăđŕôîě, ńňđîčňń˙ ěŕňđčöŕ ńěĺćíîńňč. Ĺńëč A — ěŕňđčöŕ ńěĺćíîńňč ăđŕôŕ G, ňî ěŕňđčöŕ Am îáëŕäŕĺň ńëĺäóţůčě ńâîéńňâîě: ýëĺěĺíň â i-é ńňđîęĺ, j-ě ńňîëáöĺ đŕâĺí ÷čńëó ďóňĺé čç i-é âĺđřčíű â j-ţ, ńîńňî˙ůčő čç đîâíî m đĺáĺđ. Ďîńňđîčâ íŕ îńíîâĺ äŕííîăî ěŕňđčöó äîńňčćčěîńňč, ěű čěĺĺě číôîđěŕöčţ î äîńňčćčěîńňč âĺđřčí ăđŕôŕ, ŕ çíŕ÷čň č î âűçîâŕő ôóíęöčé ďđîăđŕěěű, ńîăëŕńíî íŕřĺé çŕäŕ÷ĺ.  đŕáîňĺ [10] äŕííŕ˙ ěĺňîäčęŕ áűëŕ îďčńŕíŕ äë˙ îďđĺäĺëĺíč˙ ęîíĺ÷íîé ěŕňđčöű äîńňčćčěîńňč, ęîňîđŕ˙ îňđŕćŕĺň âîçěîćíîńňü ďĺđĺőîäŕ čç çŕäŕííîé ôóíęöčč â íĺęîňîđóţ äđóăóţ. Íî đĺçóëüňčđóţůŕ˙ ěŕňđčöŕ íĺ îňđŕćŕĺň ďđîěĺćóňî÷íűő ďóňĺé, ŕ îňđŕćŕĺň ëčřü ďîňĺíöčŕëüíóţ âîçěîćíîńňü ďĺđĺőîäŕ č ďîęŕçűâŕĺň ňîëüęî ęîëč÷ĺńňâĺííóţ îöĺíęó, íŕńęîëüęî ěíîăî âűçîâîâ äđóăčő ôóíęöčé čěĺĺňń˙ ó äŕííîé ôóíęöčč [15]. Ęđîěĺ ňîăî, ďîńňđîĺíčĺ ěŕňđčöű ńěĺćíîńňč, ńîăëŕńíî čńňî÷íčęó [10] ďđĺäďîëŕăŕĺňń˙ âî âđĺě˙ äčíŕěč÷ĺńęîăî ŕíŕëčçŕ.
Ňŕęčě îáđŕçîě, îäíčě čç îńíîâíűő ęđčňĺđčĺâ âűáîđŕ âĺęňîđŕ čńńëĺäîâŕíč˙ ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ ďđĺäďîëŕăŕëîńü ń÷čňŕňü čěĺííî ęîëč÷ĺńňâî âűçűâŕĺěűő ôóíęöčé. Îäíŕęî čńńëĺäîâŕíčĺ ďđîăđŕěěíűő ęîěďîíĺíňîâ íŕ ó˙çâčěîńňč ěîćĺň áîëĺĺ ńďĺöčôč÷íűě [16, 17]. Ňŕę, íŕďđčěĺđ, íĺęîňîđűĺ čńńëĺäîâŕíč˙ ěîăóň áűňü íŕďđŕâëĺíű íŕ ďîčńę ó˙çâčěîńňĺé íŕ ńđűâ ńňĺęŕ, ŕ íĺęîňîđűĺ íŕ ďîčńę óňĺ÷ĺę ďŕě˙ňč č ň. ď. [18]. Ďîčńę îďđĺäĺëĺííîăî ňčďŕ ó˙çâčěîńňĺé, âĺđî˙ňíî, ďîňđĺáóĺň áîëĺĺ ńďĺöčôč÷íűő ěĺňîäčę, ŕ ňŕęćĺ íŕčáîëĺĺ ďĺđńďĺęňčâíűěč ěîăóň îęŕçŕňüń˙ íĺńęîëüęî äđóăčĺ âĺęňîđű čńńëĺäîâŕíč˙, íĺćĺëč ňĺńňčđîâŕíčĺ âńĺő ôóíęöčé ďî î÷ĺđĺäč â çŕâčńčěîńňč îň ęîëč÷ĺńňâŕ äî÷ĺđíčő âűçîâîâ ďđĺäëîćĺííîĺ â čńňî÷íčęĺ [10]. Ňŕę, íŕďđčěĺđ, íŕčáîëĺĺ číňĺđĺńíűěč âĺęňîđŕěč čńńëĺäîâŕíč˙ äë˙ îáíŕđóćĺíč˙ ó˙çâčěîńňĺé íŕ ńđűâ ńňĺęŕ ěîăóň áűňü âĺňęč ęîäŕ, âĺäóůčĺ ę áîëüřĺěó ęîëč÷ĺńňâó âűçîâîâ ôóíęöčé ńňŕíäŕđňíîé áčáëčîňĺęč C/C++ đŕáîňű ńî ńňđîęŕěč. Ŕ äë˙ âű˙âëĺíč˙ îřčáîę óďđŕâëĺíč˙ ďŕě˙ňüţ — ôóíęöčč đŕáîňű ń äčíŕěč÷ĺńęîé ďŕě˙ňüţ, óęŕçŕňĺë˙ěč č ň. ď. [19] Ňŕęčě îáđŕçîě, ěű čěĺĺě íĺîáőîäčěîńňü őđŕíĺíč˙ đŕńřčđĺííîé č ńňđóęňóđčđîâŕííîé číôîđěŕöčč î âíóňđĺííĺě óńňđîéńňâĺ ďđîăđŕěěű. Őŕđŕęňĺđ őđŕíčěîé äîďîëíčňĺëüíîé číôîđěŕöčč çŕâčńčň îň ňîăî, ęŕęîé čěĺííî ňčď ó˙çâčěîńňĺé ěű ďűňŕĺěń˙ îáíŕđóćčňü.
3.3. Ńďîńîáű őđŕíĺíč˙ äîďîëíčňĺëüíîé číôîđěŕöčč
Äë˙ őđŕíĺíč˙ äîďîëíčňĺëüíîé číôîđěŕöčč ěîćíî âîńďîëüçîâŕňüń˙ đŕçëč÷íűěč ńďîńîáŕěč.  ÷ŕńňíîńňč, ěű ěîćĺě čńďîëüçîâŕňü ňîň ćĺ ěĺňîä ěŕňĺěŕňč÷ĺńęčő ěŕňđčö. Äë˙ ęŕćäîăî ňčďŕ ó˙çâčěîńňĺé ďđĺäëŕăŕĺňń˙ ôîđěčđîâŕňü îň îäíîé č áîëĺĺ äîďîëíčňĺëüíűő ěŕňđčö (â çŕâčńčěîńňč îň ÷čńëŕ ęđčňĺđčĺâ, îďđĺäĺë˙ţůčő ńňĺďĺíü ďîňĺíöčŕëüíîé îďŕńíîńňč ó÷ŕńňęŕ ęîäŕ), ăäĺ çíŕ÷ĺíč˙ěč ýëĺěĺíňîâ ęŕćäîé ěŕňđčöű áóäĺň ęîëč÷ĺńňâî ďîňĺíöčŕëüíî îďŕńíűő ó÷ŕńňęîâ ęîäŕ íŕ äŕííîě řŕăĺ. Äŕííűé ďîäőîä ďđîâîöčđóĺň ěíîăîęđčňĺđčŕëüíűé ďîäőîä íĺ ňîëüęî äë˙ îňäĺëüíűő ňčďîâ ó˙çâčěîńňĺé, íî č â đŕěęŕő îäíîăî ňčďŕ. Ňŕę, íŕďđčěĺđ, ó˙çâčěîńňč íŕ ńđűâ ńňĺęŕ ěîăóň őŕđŕęňĺđčçîâŕňüń˙ ęŕę ńňŕňč÷ĺńęčě áóôĺđîě, ňŕę č čńďîëüçîâŕíčĺě ďîňĺíöčŕëüíî íĺáĺçîďŕńíűő ôóíęöčé ńňŕíäŕđňíîé áčáëčîňĺęč ˙çűęŕ ďđîăđŕěěčđîâŕíč˙ C/C++.
3.4. Îďđĺäĺëĺíčĺ ńňĺďĺíč îďŕńíîńňč ó÷ŕńňęŕ ęîäŕ, čńďîëüçîâŕíčĺ äë˙ ďîńňđîĺíč˙ ěŕňđčö íĺďîńđĺäńňâĺííî áëîęîâ ęîäŕ
Äë˙ îďđĺäĺëĺíč˙ ńňĺďĺíč îďŕńíîńňč ó÷ŕńňęŕ ęîäŕ â đŕěęŕő îďđĺäĺëĺííîăî ęđčňĺđč˙ ďđĺäďîëŕăŕĺňń˙ čńďîëüçîâŕíčĺ đŕçëč÷íűő ďđŕâčë, ˙âë˙ţůčőń˙ ŕëăîđčňěŕěč ďîčńęŕ. Íŕďđčěĺđ, â ńëó÷ŕĺ îáíŕđóćĺíč˙ ęîäŕ, ńîîňâĺňńňâóţůĺěó îďđĺäĺëĺííîěó ďđŕâčëó, ďđĺäëŕăŕĺňń˙ číęđĺěĺíň çíŕ÷ĺíč˙ ňĺęóůĺăî ýëĺěĺíňŕ ěŕňđčöű AIcurrJcurr [20].
 đŕáîňĺ [10] ýëĺěĺíňŕěč ěŕňđčöű ńěĺćíîńňč â îńíîâíîě đŕńńěŕňđčâŕëčńü îňäĺëüíűĺ ôóíęöčč, îäíŕęî ńňđóęňóđŕ ŕńńĺěáëĺđíîăî ęîäŕ ěîćĺň áűňü ÷đĺçâű÷ŕéíî çŕďóňŕíŕ č íĺ âî âńĺő ńëó÷ŕ˙ő ěîćíî ÷ĺňęî č îäíîçíŕ÷íî âĺđíî âűäĺëčňü ăđŕíčöű ôóíęöčč. Ďđîâĺäĺě ýęńďĺđčěĺíň (Ëčńňčíă 1.1.). Îńíîâűâŕ˙ńü íŕ ňîě, ÷ňî ďî ńóňč ńâîĺé číńňđóęöčč call č jmp â ŕđőčňĺęňóđĺ Intel x86, ŕ ňŕę ćĺ â Intel x86_64 ďî ńóňč ńâîĺé ˙âë˙ţňń˙ áĺçóńëîâíűěč ďĺđĺőîäŕěč, ńôîđěčđóĺě íĺ ńëîćíűé ýęńďĺđčěĺíňŕëüíűé ęîä íŕ ˙çűęĺ Assembler â ďđîăđŕěěĺ-ŕńńĺěáëĺđĺ fasm (flat assembler).
Ëčńňčíă 1.
format PE64 GUI 5.0
entry start
section '.text' code readable executable
start:
sub rsp,8*5
mov r9d,0
lea r8,[_caption]
lea rdx,[_message]
mov rcx,0
call [MessageBoxA]
call proc_1;
after_proc_1_call:
call proc_2;
after_proc_2_call:
end_start_proc:
mov r9d,0
lea r8,[_caption]
lea rdx,[_message_end_start_proc]
mov rcx,0
call [MessageBoxA]
mov ecx,eax
call [ExitProcess]
proc_1:
sub rsp,8*5
mov r9d,0
lea r8,[_caption]
lea rdx,[_message_1]
mov rcx,0
call [MessageBoxA]
add rsp,8*5
jmp proc_2
proc_2:
sub rsp,8*5
mov r9d,0
lea r8,[_caption]
lea rdx,[_message_2]
mov rcx,0
call [MessageBoxA]
add rsp,8*5
ret
section '.data' data readable writeable
_caption db 'Win64 assembly program',0
_message db 'Hello World start_proc!',0
_message_1 db 'proc_1!',0
_message_2 db 'proc_2!',0
_message_end_start_proc db 'Good by start_proc!',0
section '.idata' import data readable writeable
dd 0,0,0,RVA kernel_name,RVA kernel_table
dd 0,0,0,RVA user_name,RVA user_table
dd 0,0,0,0,0
kernel_table:
ExitProcess dq RVA _ExitProcess
dq 0
user_table:
MessageBoxA dq RVA _MessageBoxA
dq 0
kernel_name db 'KERNEL32.DLL',0
user_name db 'USER32.DLL',0
_ExitProcess dw 0
db 'ExitProcess',0
_MessageBoxA dw 0
db 'MessageBoxA',0
4. Đĺçóëüňŕňű
4.1. Đĺçóëüňŕňű ŕíŕëčçŕ ęîäŕ, ŕíŕëčçŕ ďĺđĺęđ¸ńňíűő ńńűëîę IDA Pro 6.1
 äŕííîě ëčńňčíăĺ ěű âčäčě, ÷ňî ďĺđĺőîä íŕ ěĺňęó «proc_1» č «proc_2» čç ęîäŕ â áëîęĺ «start» îńóůĺńňâë˙ĺňń˙ ęîěŕíäîé «call».  ňî ćĺ âđĺě˙ ďĺđĺőîä íŕ ěĺňęó «proc_2» îńóůĺńňâë˙ĺňń˙ čç áëîęŕ ęîäŕ îň ěĺňęč «proc_1» ń ďîěîůüţ číńňđóęöčč jmp. Äŕííűé ęîä ˙âë˙ĺňń˙ íĺńęîëüęî íĺ ňčďč÷íűě. Äčçŕńńĺěáëĺđ IDA Pro 6.1 ďđîŕíŕëčçčđîâŕâ áčíŕđíűé ôŕéë ńîîáůŕĺň, ÷ňî ěű čěĺĺě 3 ôóíęöčč: «start», «sub_401058», «sub_401083». Ďđč ýňîě â ôóíęöčč «sub_401058» â ăđŕôč÷ĺńęîě ďđĺäńňŕâëĺíčč, îňęđűňîě ďî óěîë÷ŕíčţ, ěîćíî óâčäĺňü ńîîáůĺíčĺ «sub_401058 endp ; sp-analysis failed» íŕ ęđŕńíîě ôîíĺ (đčń. 2, 3).
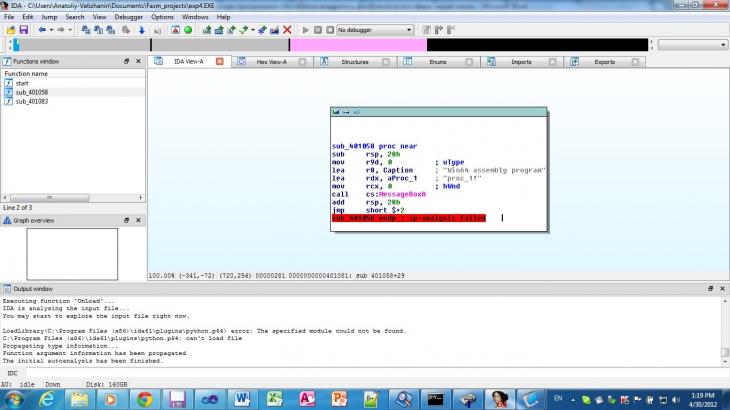
Đčń. 2. Đĺçóëüňŕň ŕíŕëčçŕ ęîäŕ â IDA Pro 6.1
Äŕííűé ôŕęň ďîäňâĺđćäŕĺň, ÷ňî ęîđđĺęňíîĺ ŕâňîěŕňč÷ĺńęîĺ îďđĺäĺëĺíčĺ ăđŕíčö ôóíęöčč íĺ âńĺăäŕ ˙âë˙ĺňń˙ âîçěîćíűě [21].
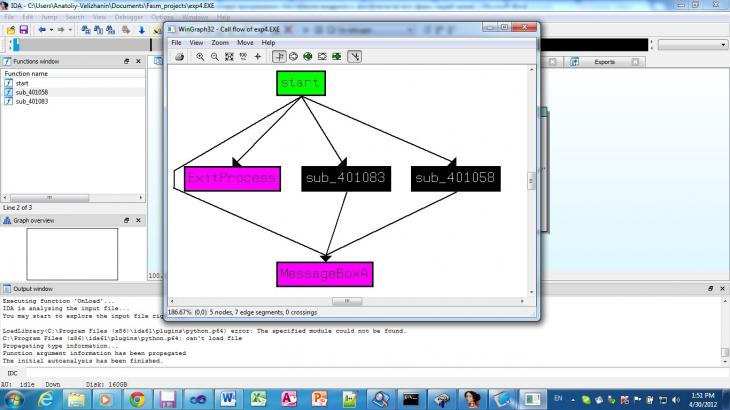
Đčń. 3. Đĺçóëüňŕň ŕíŕëčçŕ ďĺđĺęđĺńňíűő ńńűëîę IDA Pro 6.1
Ń ňî÷ęč çđĺíč˙ ŕíŕëčçŕňîđŕ ęîäŕ, âńňđîĺííîăî â äčçŕńńĺěáëĺđ â äŕííîé ďđîăđŕěěĺ, čěĺĺňń˙ 3 ôóíęöčč. Îäíŕęî, ýňî íĺäîńňŕňî÷íî ňî÷íî îňđŕćŕĺň ńóňč ďđîčńőîä˙ůĺăî. Íĺńěîňđ˙ íŕ ňî, ÷ňî ěű čěĺĺě číńňđóęöčč ďĺđĺőîäŕ «call» íŕ ôóíęöčč «proc_1» č «proc_2» čç ôóíęöčč «start», íŕ ńŕěîě äĺëĺ ěű čěĺĺě äĺëî č ń ďđîěĺćóňî÷íűě ďĺđĺőîäîě čő áëîęŕ ęîäŕ ôóíęöčč «proc_1» â áëîę ęîäŕ ôóíęöčč «proc_2». Ňŕęčě îáđŕçîě, ŕíŕëčçŕňîđ ęîäŕ, îăđŕíč÷čâ ôóíęöčţ «proc_1» ŕäđĺńîě ďĺđâîé číńňđóęöčč áëîęŕ ęîäŕ «proc_2», íĺńęîëüęî íĺňî÷íî îňđŕçčë ďđîčńőîä˙ůĺĺ, ďîńęîëüęó ń ďîçčöčč ôóíęöčč «proc_1» ôóíęöč˙ «proc_2» ˙âë˙ĺňń˙ âńĺăî ëčřü ďđîäîëćĺíčĺě ôóíęöčč «proc_1». Íŕ đčń. 1.2. čçîáđŕćĺí đĺçóëüňŕň ăđŕôč÷ĺńęîăî ďđĺäńňŕâëĺíč˙ ăđŕôŕ âűçîâîâ. Ęđîěĺ ňîăî, ńëĺäóĺň îňěĺňčňü, ÷ňî â ńŕěîě ˙çűęĺ ďđîăđŕěěčđîâŕíč˙ Assembler íĺň ďîí˙ňč˙ ôóíęöčč čëč ďđîöĺäóđű â ďđčâű÷íîě äë˙ âűńîęîóđîâíĺâűő ˙çűęîâ ďđîăđŕěěčđîâŕíč˙ ńěűńëĺ. Čěĺţňń˙ ëčřü číńňđóęöčč ďĺđĺőîäîâ. Ňŕę, číńňđóęöč˙ «call» âűďîëí˙ĺň âńĺăî ëčřü áĺçóńëîâíűé ďĺđĺőîä, íî â îňëč÷čĺ îň číńňđóęöčč «jmp», ďîěĺůŕĺň â ńňĺę ŕäđĺń âîçâđŕňŕ. Číńňđóęöč˙ «ret» ďđîčçâîäčň îáđŕňíűé ďĺđĺőîä ďî ŕäđĺńó čç ńňĺęŕ č ň. ď. Âńĺ ýňî íĺńęîëüęî îňëč÷ŕĺňń˙ îň ďđĺäńňŕâëĺíč˙ ěĺőŕíčçěŕ đŕáîňű ńóůíîńňč «ôóíęöč˙» â âűńîęîóđîâíĺâűő ˙çűęŕő ďđîăđŕěěčđîâŕíč˙.
Ňŕęčě îáđŕçîě, äë˙ ďîńňđîĺíč˙ ěŕňđčö ńěĺćíîńňč č äë˙ ôîđěčđîâŕíč˙ äîďîëíčňĺëüíűő číôîđěŕöčîííűő ěŕňđčö â ęŕ÷ĺńňâĺ čő ýëĺěĺíňîâ ďđĺäëŕăŕĺňń˙ čńďîëüçîâŕňü íĺ «ôóíęöčč» â čő ďđčâű÷íîě äë˙ âűńîęîóđîâíĺâűő ˙çűęîâ ďđîăđŕěěčđîâŕíčč (ňŕęčő ęŕę C++, C# č ň. ď.) ďîíčěŕíčč, ŕ íĺďîńđĺäńňâĺííî áëîęč ęîäŕ. Ňîăäŕ ęŕćäűé áëîę ęîäŕ áóäĺň őŕđŕęňĺđčçîâŕňüń˙ îňńóňńňâčĺě îďĺđŕöčé ďĺđĺőîäîâ. Âńňđĺňčâ îďĺđŕöčţ ďĺđĺőîäŕ ŕëăîđčňě äîëćĺí íŕ÷ŕňü íîâűé áëîę. Ňîăäŕ â đĺçóëüňŕňĺ ěű ďîëó÷čě äĺđĺâî áëîęîâ, ăäĺ ęŕćäűé áëîę áóäĺň őŕđŕęňĺđčçîâŕňüń˙ äîďîëíčňĺëüíűěč číôîđěŕöčîííűěč ěŕňđčöŕěč.
Îáúĺäčíčâ âűřĺńęŕçŕííîĺ î ěĺňîäčęĺ ďîčńęŕ ďóňĺé ń čńďîëüçîâŕíčĺě ěŕňđčöű ńěĺćíîńňč č ďđĺäëîćĺííűé ďîäőîä ń íŕáîđîě číôîđěŕöčîííűő ěŕňđčö, ŕ ňŕęćĺ ěĺňîäčęó đŕçáčĺíč˙ ęîäŕ íŕ áëîęč äë˙ ôîđěčđîâŕíč˙ ěŕňđčö ńěĺćíîńňč, ěű ěîćĺě îďđĺäĺëčňü íŕčáîëĺĺ ďĺđńďĺęňčâíűĺ âĺęňîđű čńńëĺäîâŕíč˙ ďđîăđŕěěíîăî ęîäŕ íŕ ó˙çâčěîńňč.
4.2. Âŕđčŕíň đĺŕëčçŕöčč ďđĺäëîćĺííîăî ŕëăîđčňěŕ
Âęđŕňöĺ đŕńńěîňđčě îäčí čç âŕđčŕíňîâ đĺŕëčçŕöčč äŕííîăî ŕëăîđčňěŕ.
1. Íŕ ďĺđâîě řŕăĺ ďđĺäëŕăŕĺňń˙ đŕçáčňü äčçŕńńĺěáëčđîâŕííűé ęîä íŕ áëîęč, ŕ íĺ íŕ ôóíęöčč. Äë˙ đŕçáčĺíč˙ ěű ďîńëĺäîâŕňĺëüíî ďĺđĺáčđŕĺě číńňđóęöčč äčçŕńńĺěáëčđîâŕííîăî ëčńňčíăŕ č, ęîăäŕ âńňđĺ÷ŕĺě číńňđóęöčţ, ęîňîđŕ˙ ěîćĺň ďîâëč˙ňü íŕ őîä âűďîëíĺíč˙ ďđîăđŕěěű (äë˙ ŕđőčňĺęňóđű x86 č óíŕńëĺäîâŕííűő ýňî číńňđóęöčč óńëîâíîăî, áĺçóńëîâíîăî ďĺđĺőîäîâ, «call», «ret»), çŕęđűâŕĺě ňĺęóůčé áëîę. Ńëĺäóţůčé áëîę íŕ÷číŕĺňń˙ ńî ńëĺäóţůĺé číńňđóęöčč. Ňŕęčě îáđŕçîě, â ęîíöĺ öčęëŕ ěű ďîëó÷ŕĺě íŕáîđ áëîęîâ, ďî ęîíĺ÷íűě ŕäđĺńŕě ęîňîđűő íŕőîä˙ňń˙ číńňđóęöčč ďĺđĺőîäîâ.
2. Íŕ âňîđîě řŕăĺ ěű ńâ˙çűâŕĺě ďîëó÷ĺííűĺ đŕíĺĺ áëîęč ń ęîäîě. Äë˙ đĺŕëčçŕöčč ýňîăî ďđĺäëŕăŕĺňń˙ ďîńëĺäîâŕňĺëüíî ďĺđĺáčđŕňü áëîęč č äë˙ ęŕćäîăî áëîęŕ ŕíŕëčçčđîâŕňü ńńűëęč íŕ ŕäđĺńŕ ďđĺäëŕăŕĺěűő ďĺđĺőîäîâ.  ńëó÷ŕĺ îďĺđŕöčé óńëîâíűő ďĺđĺőîäîâ (äë˙ ŕđőčňĺęňóđű ďđîöĺńńîđîâ ő86 č óíŕńëĺäîâŕííűő) ŕäđĺń ďĺđĺőîäŕ ďĺđĺäŕĺňń˙ ÷ĺđĺç ĺäčíńňâĺííűé ŕđăóěĺíň číńňđóęöčč óńëîâíîăî ďĺđĺőîäŕ. Ňŕę ćĺ ďĺđĺőîä äë˙ ýňîé ŕđőčňĺęňóđű ďđîöĺńńîđîâ ěîćĺň áűňü ďđîčçâĺäĺí íŕ ęîěŕíäó, đŕńďîëîćĺííóţ ďî ńëĺäóţůĺěó ŕäđĺńó, íĺďîńđĺäńňâĺííî çŕ ęîěŕíäîé óńëîâíîăî ďĺđĺőîäŕ. Číńňđóęöč˙ «ret» îńóůĺńňâë˙ĺň ďĺđĺőîä ďî ŕäđĺńó, ńëĺäóţůĺěó çŕ ńîîňâĺňńňâóţůĺé ĺé číńňđóęöčč «call» (çŕ čńęëţ÷ĺíčĺě ńëó÷ŕĺâ ěîäčôčęŕöčč â ęîäĺ ŕäđĺńŕ âîçâđŕňŕ, đŕńďîëîćĺííîěó â ńňĺęĺ. Äë˙ îáű÷íîăî ĎÎ ňŕęŕ˙ ěîäčôčęŕöč˙ ˙âë˙ĺňń˙ íĺ ňčďč÷íîé)
 đĺçóëüňŕňĺ äŕííîăî řŕăŕ ěű ďîëó÷ŕĺě äĺđĺâî ďĺđĺőîäîâ, ęîňîđîĺ áóäĺň čńďîëüçîâŕíî â äŕëüíĺéřĺě äë˙ ńîńňŕâëĺíč˙ îöĺíęč ďĺđńďĺęňčâíîńňč âĺęňîđŕ čńńëĺäîâŕíč˙ äë˙ ďîčńęŕ ńîîňâĺňńňâóţůĺăî ňčďŕ ó˙çâčěîńňč. Ęđîěĺ ňîăî, äŕííîĺ äĺđĺâî ďîçâîë˙ĺň îďđĺäĺëčňü č íĺčńďîëüçóĺěűĺ ó÷ŕńňęč ęîäŕ, ęîňîđűĺ çŕ÷ŕńňóţ čńďîëüçóţňń˙ âčđóńŕěč äë˙ âíĺäđĺíč˙ â čńďîëí˙ĺěűé ôŕéë. Îäíîé čç ďđč÷čí, ďî ęîňîđűě íĺęîňîđűĺ âčđóńű ńňŕđŕţňń˙ âíĺäđ˙ňüń˙ čěĺííî â íĺčńďîëüçóĺěűĺ ó÷ŕńňęč čńďîëí˙ĺěîăî ôŕéëŕ, óńňŕíîâčâ ďĺđĺőîä íŕ ńâîĺ ňĺëî, ˙âë˙ĺňń˙ ňî, ÷ňî âíĺäđĺíčĺ â ďđîčçâîëüíóţ ďîçčöčţ ěîćĺň ďîâëĺ÷ü íŕđóřĺíčĺ đŕáîňîńďîńîáíîńňč čńďîëí˙ĺěîăî ôŕéëŕ, ŕ çíŕ÷čň, íŕđóřčň ńęđűňíîńňü ôŕęňŕ çŕđŕćĺíč˙. Äë˙ őîňü ńęîëüęî-ňî îáú¸ěíűő ďđîăđŕěě äŕííîĺ äĺđĺâî áóäĺň ÷đĺçâű÷ŕéíî áîëüřčě č íĺóäîáíűě äë˙ ŕíŕëčçŕ ÷ĺëîâĺęîě. Äđîáëĺíčĺ íŕ ďîäîáíűĺ áëîęč ďđčâîäčň ę çíŕ÷čňĺëüíîé ôđŕăěĺíňŕöčč äčçŕńńĺěáëčđîâŕííîăî ęîäŕ, ÷ňî óâĺëč÷čâŕĺň ńëîćíîńňü âčçóŕëüíîăî âîńďđč˙ňč˙ äŕííîăî ęîäŕ. Îäíŕęî, â îňëč÷čĺ îň číńňđóěĺíňîâ íŕďîäîáčĺ IDA Pro, ęîňîđűĺ íŕöĺëĺíű íŕ ŕíŕëčç ÷ĺëîâĺęîě, íŕřĺé çŕäŕ÷ĺé ˙âë˙ĺňń˙ ďîńňđîĺíčĺ ŕëăîđčňěŕ äë˙ ŕâňîěŕňčçčđîâŕííîăî ŕíŕëčçŕ ń ěčíčěŕëüíűě ó÷ŕńňčĺě ýęńďĺđňŕ. Ńňîëü ěĺëęîĺ äđîáëĺíčĺ ęîäŕ ďîçâîë˙ĺň čçáĺćŕňü âűřĺîďčńŕííîé ńčňóŕöčč ń îřčáęîé ŕíŕëčçŕ ńňđóęňóđű ęîäŕ ďđîăđŕěěîé IDA Pro.
3. Âűďîëíčâ ďđîőîä ďî ďîëó÷ĺííîěó íŕ ďđĺäűäóůĺě řŕăĺ äĺđĺâó, ëčáî ńďčńęó ýëĺěĺíňîâ äĺđĺâŕ (ńďčńîę áëîęîâ ęîäŕ), ęîňîđűé íŕ ďđĺäűäóůĺě řŕăĺ ěű čńďîëüçîâŕëč äë˙ ôîđěčđîâŕíč˙ äĺđĺâŕ, ôîđěčđóĺě íŕ÷ŕëüíóţ ěŕňĺěŕňč÷ĺńęóţ ěŕňđčöó ńěĺćíîńňč. Äŕííŕ˙ ěŕňđčöŕ, ďî áîëüřĺé ÷ŕńňč, ńîäĺđćčň íóëč, ďîńęîëüęó ęŕćäűé áëîę ęîäŕ â íŕřĺě ŕëăîđčňěĺ ěîćĺň čěĺňü ňîëüęî 2 ŕäđĺńŕ, íŕ ęîňîđűĺ îńóůĺńňâë˙ĺňń˙ ďĺđĺőîä â ńëó÷ŕĺ óńëîâíîăî ďĺđĺőîäŕ č 1 ŕäđĺń â ńëó÷ŕĺ áĺçóńëîâíîăî. Ýňî ńâ˙çŕíî ń ňĺě, ÷ňî, ńîăëŕńíî ŕđőčňĺęňóđĺ ő86 č óíŕńëĺäîâŕííűě, ęîěŕíäŕ áĺçóńëîâíîăî ďĺđĺőîäŕ ďĺđĺäŕ¸ň óďđŕâëĺíčĺ ďî ŕäđĺńó, óęŕçŕííîěó â ŕđăóěĺíňĺ, ŕ ęîěŕíäŕ óńëîâíîăî ďĺđĺőîäŕ ëčáî ďî ŕäđĺńó, óęŕçŕííîěó â ŕđăóěĺíňĺ, ëčáî ďĺđĺäŕ¸ň óďđŕâëĺíčĺ íŕ ńëĺäóţůóţ çŕ äŕííîé ęîěŕíäîé číńňđóęöčţ.
Äë˙ ńîęđŕůĺíč˙ čçäĺđćĺę îďĺđŕňčâíîé ďŕě˙ňč ęîěďüţňĺđŕ ěű ěîăëč áű ńôîđěčđîâŕňü äŕííóţ ěŕňđčöó čç áčňîâűő çíŕ÷ĺíčé. Îäíŕęî ńôîđěčđîâŕâ ĺĺ čç öĺëî÷čńëĺííűő çíŕ÷ĺíčé, ěű ńěîćĺě čńďîëüçîâŕňü ĺĺ äë˙ őđŕíĺíč˙ äîďîëíčňĺëüíîé číôîđěŕöčč î âĺńĺ ęŕćäîăî îňäĺëüíîăî ýëĺěĺíňŕ. Ęîíęđĺňíŕ˙ đĺŕëčçŕöč˙ ěîćĺň áűňü íĺńęîëüęî đŕçëč÷íîé č ďđč ýňîě ěîćĺň čńďîëüçîâŕňüń˙ ęŕę âíóňđĺíí˙˙ ńčńňĺěŕ őđŕíĺíč˙ äîďîëíčňĺëüíîé číôîđěŕöčč, ňŕę č âíĺří˙˙:
Ŕ) âíóňđĺíí˙˙ čńďîëüçóĺňń˙ ňîăäŕ, ęîăäŕ ěű ńîőđŕí˙ĺě ęîíęđĺňíóţ đĺŕëčçŕöčţ â âčäĺ ńîîňâĺňńňâóţůčő çíŕ÷ĺíčé áîëüřčő ĺäčíčöű â ěŕňđčöĺ ńěĺćíîńňč. Íŕďđčěĺđ, â ńëó÷ŕĺ, ęîăäŕ ěű čńďîëüçóĺě ëčřü îäčí ęđčňĺđčé îďđĺäĺëĺíč˙ âĺńŕ.
Á) âíĺří˙˙ ńčńňĺěŕ őđŕíĺíč˙ äîďîëíčňĺëüíîé číôîđěŕöčč čńďîëüçóĺňń˙ ňîăäŕ, ęîăäŕ ěű ńîőđŕí˙ĺě ĺ¸ â îňäĺëüíűő ńňđóęňóđŕő äŕííűő. Íŕďđčěĺđ, â ńëó÷ŕ˙ő, ęîăäŕ ěű čńďîëüçóĺě ěíîăîęđčňĺđčŕëüíűé ŕíŕëčç âĺńŕ ýëĺěĺíňîâ.
Ňŕęčě îáđŕçîě, ďđĺäëîćĺííűé ŕëăîđčňě ďîńňđîĺíč˙ ěŕňđčöű ďĺđĺőîäîâ ďîçâîë˙ĺň áîëĺĺ ďîäđîáíî, íĺćĺëč ŕíŕëîăč÷íűé ďîäőîä, îďčđŕţůčéń˙ íŕ âűçîâű ôóíęöčé, đŕńńěîňđĺňü ńňđóęňóđó čńńëĺäóĺěîăî ďđîăđŕěěíîăî ęîěďîíĺíňŕ. Íĺńîěíĺííî, ńňîëü ěĺëęîĺ äđîáëĺíčĺ îáúĺěíűő äčçŕńńĺěáëčđîâŕííűő ëčńňčíăîâ ˙âë˙ĺňń˙ íĺóäîáíűě äë˙ âîńďđč˙ňč˙ ÷ĺëîâĺęîě, îäíŕęî, ęŕę óćĺ ńîîáůŕëîńü âűřĺ, íĺîáőîäčěîé ˙âë˙ĺňń˙ ŕâňîěŕňčçŕöč˙ ďđîöĺńńŕ ŕíŕëčçŕ.
Çŕęëţ÷ĺíčĺ
Îďčńŕííűé ďîäőîä ěîćĺň ˙âë˙ňüń˙ íŕ÷ŕëüíîé ńňŕäčĺé ďîäăîňîâęč ę ŕâňîěŕňčçčđîâŕííîěó ŕíŕëčçó äčçŕńńĺěáëčđîâŕííîăî ęîäŕ, ôîđěčđó˙ čç ńďëîříîăî ëčńňčíăŕ ÷ĺňęî îđăŕíčçîâŕííóţ ńčńňĺěó áëîęîâ ń âűńîęîé ńňĺďĺíüţ äĺňŕëüíîńňč. Îáđŕňčě âíčěŕíčĺ íŕ ňî, ÷ňî äčçŕńńĺěáëĺđ IDA Pro, ďîńňđîčâ ęŕđňó ďĺđĺőîäîâ ďî ôóíęöč˙ě, ďîçâîë˙ĺň ŕíŕëîăč÷íűě îáđŕçîě ďîńňđîčňü č ńőĺěó ęŕćäîé ôóíęöčč â îňäĺëüíîńňč. Ďđĺäëîćĺííűé ďîäőîä îňëč÷ŕĺňń˙ ňĺě, ÷ňî čńęëţ÷ŕĺň âűäĺëĺíčĺ ňŕęîăî îňäĺëüíî ýëĺěĺíňŕ ęŕę «ôóíęöč˙» â ďîíčěŕíčč ýňîăî ňĺđěčíŕ, ńîăëŕńíî ˙çűęŕě ďđîăđŕěěčđîâŕíč˙ âűńîęîăî óđîâí˙, íŕďđčěĺđ, C/C++. Ęđîěĺ ňîăî, äŕííűé ďîäőîä ďđĺäëŕăŕĺň âű˙âëĺíčĺ íŕčáîëĺĺ ďĺđńďĺęňčâíűő âĺęňîđîâ čńńëĺäîâŕíč˙ íŕ îńíîâĺ ńóůíîńňč ęŕćäîăî áëîęŕ ęîäŕ č ňĺęóůĺé öĺëč čńńëĺäîâŕíč˙.
Áčáëčîăđŕôč˙
1. Đĺâíčâűő Ŕ. Â. Ěîíčňîđčíă číôîđěŕöčîííîé číôđŕńňđóęňóđű îđăŕíčçŕöčč / Ŕ. Â. Đĺâíčâűő, Ŕ. Ě. Ôĺäîňîâ // Âĺńňíčę ÍĂÓ. Ńĺđ.: Číôîđěŕöčîííűĺ ňĺőíîëîăčč. — 2013. — Ň. 11. — ą 4. — Ń. 84–91. ISSN 1818-7900. URL: https://nsu.ru/xmlui/bitstream/handle/nsu/1295/2013_V11_N4_8.pdf.
2. Ďđčěĺíĺíčĺ ęîěďčë˙ňîđíűő ďđĺîáđŕçîâŕíčé äë˙ ďđîňčâîäĺéńňâč˙ ýęńďëóŕňŕöčč ó˙çâčěîńňĺé ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ / Ŕ. Đ. Íóđěóőŕěĺňîâ [č äđ.] // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2014. — Ň. 26. — ą
3. Ń. 113-124. ISSN 2079-8156. 3.Îöĺíęŕ ęđčňč÷íîńňč ďđîăđŕěěíűő äĺôĺęňîâ â óńëîâč˙ő đŕáîňű ńîâđĺěĺííűő çŕůčňíűő ěĺőŕíčçěîâ /Ŕ. Í. Ôĺäîňîâ [č äđ.] // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2016. — Ň. 28. — ą 5. — Ń. 73–92. DOI: 10.15514/ISPRAS-2016-28(5)-4
4. Ěóőŕíîâŕ Ŕ. Ŕ. Ęëŕńńčôčęŕöč˙ óăđîç č ó˙çâčěîńňĺé číôîđěŕöčîííîé áĺçîďŕńíîńňč â ęîđďîđŕňčâíűő ńčńňĺěŕő / Ŕ. Ŕ. Ěóőŕíîâŕ, Ŕ. Â Đĺâíčâűő, Ŕ. Ě Ôĺäîňîâ // Âĺńňíčę ÍĂÓ. Ńĺđ.: Číôîđěŕöčîííűĺ ňĺőíîëîăčč. — 2013. — Ň. 11. — ą 2. — Ń. 55-72. ISSN 1818-7900.
5. Đĺâíčâűő Ŕ. Â. Ďîëčňčęč îáíîâëĺíč˙ đĺńóđńîâ â číôîđěŕöčîííűő ńčńňĺěŕő / Ŕ. Â. Đĺâíčâűő, Ŕ. Ě. Ôĺäîňîâ // Âĺńňíčę ÍĂÓ. Ńĺđ.: Číôîđěŕöčîííűĺ ňĺőíîëîăčč. — 2013. — Ň. 11. — ą 2. —Ń. 82–105. ISSN 1818-7900.
6. Ôĺäîňîâ Ŕ. Í. Ďîńňđîĺíčĺ ďđĺäčęŕňîâ áĺçîďŕńíîńňč äë˙ íĺęîňîđűő ňčďîâ ďđîăđŕěěíűő äĺôĺęňîâ / Ŕ. Í. Ôĺäîňîâ [č äđ.] // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2017. — Ň. 29. — ą 6. — Ń. 151–162. ISSN 2079-8156. DOI: 10.15514/ISPRAS-2017-29(6)-8.
7. Íŕäĺćäčí Ĺ.Í. Ŕíŕëčç ó˙çâčěîńňĺé ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ ďđč ďđîĺęňčđîâŕíčč ěĺőŕíčçěŕ číňĺăđčđîâŕííîé çŕůčňű ęîđďîđŕňčâíîé číôîđěŕöčîííîé ńčńňĺěű / Ĺ.Í. Íŕäĺćäčí, Ĺ.Č. Ůčďöîâŕ, Ň.Ë. Řĺđřŕęîâŕ. // Ńîâđĺěĺííűĺ íŕóęîĺěęčĺ ňĺőíîëîăčč. — 2017. — ą 10. — Ń. 32–38. ISSN 1812-7320. URL: http://www.top-technologies.ru/ru/article/view?id=36824
8. Ńŕňňîí Ě. Fuzzing: čńńëĺäîâŕíčĺ ó˙çâčěîńňĺé ěĺňîäîě ăđóáîé ńčëű / Ě. Ńŕňňîí, Ŕ. Ăđčí, Ď. Ŕěčíč. — ŃĎá.-Ě.: Ńčěâîë-Ďëţń, 2009. — 560 ń. ISBN: 978-5-93286-147-9.
9. Âĺëčćŕíčí Ŕ. Ń. Ýâđčńňč÷ĺńęčé ěĺňîä ďîčńęŕ ó˙çâčěîńňĺé â ĎÎ áĺç čńďîëüçîâŕíč˙ čńőîäíîăî ęîäŕ / Ŕ. Ń. Âĺëčćŕíčí, Ŕ. Â. Đĺâíčâűő // XIV Đîńńčéńęŕ˙ ęîíôĺđĺíöč˙ ń ěĺćäóíŕđîäíűě ó÷ŕńňčĺě "Đŕńďđĺäĺëĺííűĺ číôîđěŕöčîííűĺ č âű÷čńëčňĺëüíűĺ đĺńóđńű" (DICR-2012). ISBN 978-5-905569-05-0. 26 íî˙áđ˙-30 íî˙áđ˙ 2012, Íîâîńčáčđńę. URL: http://conf.ict.nsc.ru/files/conferences/dicr2012/fulltext/140768/141800/%D0%A0%D0%B5%D0%B2%D0%BD%D0%B8%D0%B2%D1%8B%D1%85%20%20%D0%AD%D0%B2%D1%80%D0%B8%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9%20%D0%BC%D0%B5%D1%82%D0%BE%D0%B4.pdf
10. Áëŕăîäŕđĺíęî Ŕ. Â. Đŕçđŕáîňęŕ ěĺňîäŕ, ŕëăîđčňěîâ č ďđîăđŕěě äë˙ ŕâňîěŕňč÷ĺńęîăî ďîčńęŕ ó˙çâčěîńňĺé ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ â óńëîâč˙ő îňńóňńňâč˙ čńőîäíîăî ęîäŕ: äčńńĺđňŕöč˙ ... ęŕíäčäŕňŕ ňĺőíč÷ĺńęčő íŕóę: 05.13.19 / Ŕ. Â. Áëŕăîäŕđĺíęî; [Ěĺńňî çŕůčňű: Ţć. ôĺäĺđ. óí-ň]. — Ňŕăŕíđîă, 2011. — 140 ń.: čë. OD 61 12-5/251.
11. Řóäđŕę Ě. Î. Ŕâňîěŕňčçčđîâŕííűé ďîčńę ó˙çâčěîńňĺé â áčíŕđíîě ęîäĺ / Ě. Î. Řóäđŕę, Ň. Ń. Őĺčđőŕáŕđîâ // Đĺřĺňíĺâńęčĺ ÷ňĺíč˙: ěŕňĺđčŕëű XVI Ěĺćäóíŕđ. íŕó÷. ęîíô., ďîńâ˙ů. ďŕě˙ňč ăĺíĺđ. ęîíńňđóęňîđŕ đŕęĺň.-ęîńěč÷. ńčńňĺě ŕęŕä. Ě. Ô. Đĺřĺňíĺâŕ (7–9 íî˙á. 2012, ă. Ęđŕńíî˙đńę): â 2 ÷. / ďîä îáů. đĺä. Ţ. Ţ. Ëîăčíîâŕ; Ńčá. ăîń. ŕýđîęîńěč÷. óí-ň. — Ęđŕńíî˙đńę, 2012. — ×. 2. — Ń. 691–692.
12. Âîđîďŕĺâ Ä. Ď. Čńńëĺäîâŕíčĺ ďđîăđŕěěíűő ó˙çâčěîńňĺé â ęîěďüţňĺđíűő ńčńňĺěŕő č ŕíŕëčç ďđčěĺí˙ĺěîăî ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ äë˙ ďđîâĺäĺíč˙ ŕňŕę íŕ âű÷čńëčňĺëüíóţ ńčńňĺěó / Ä. Ď. Âîđîďŕĺâ, Č. Ŕ. Çŕóăîëęîâ // Âĺńňíčę ŇĂÓ. — 2014. — Ň. 19. — ą 2. Ń. — 637–638. ISSN 1810-0198. URL: https://cyberleninka.ru/article/v/issledovanie-programmnyh-uyazvimostey-v-kompyuternyh-sistemah-i-analiz-primenyaemogo-programmnogo-obespecheniya-dlya-provedeniya-atak
13. Ěčđîíîâ Ń. Â. Ňĺőíîëîăčč ęîíňđîë˙ áĺçîďŕńíîńňč ŕâňîěŕňčçčđîâŕííűő ńčńňĺě íŕ îńíîâĺ ńňđóęňóđíîăî č ďîâĺäĺí÷ĺńęîăî ňĺńňčđîâŕíč˙ ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ / Ń. Â.Ěčđîíîâ, Ă. Â. Ęóëčęîâ // Ęčáĺđíĺňčęŕ č ďđîăđŕěěčđîâŕíčĺ. — 2015. — ą 5. — Ń.158–172. ISSN 2306-4196. DOI: 10.7256/2306-4196.2017.1.20351
14. Íĺďîěí˙ůčő Ŕ. Â., Ęóëčęîâ Ă. Â., Ńîńíčí Ţ. Â., Íŕů¸ęčí Ď. Ŕ. Ěĺňîäű îöĺíčâŕíč˙ çŕůčůĺííîńňč číôîđěŕöčč â ŕâňîěŕňčçčđîâŕííűő ńčńňĺěŕő îň íĺńŕíęöčîíčđîâŕííîăî äîńňóďŕ // Âîďđîńű çŕůčňű číôîđěŕöčč. — 2014. — ą 1 (104). — Ń. 3–12. ISSN 2073-2600.
15. Ôĺäîňîâ Ŕ. Í. Ěĺňîä îöĺíęč ýęńďëóŕňčđóĺěîńňč ďđîăđŕěěíűő äĺôĺęňîâ // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2016. — Ň. 28. — ą 4. — Ń. 137–148. ISSN 2079-8156. DOI: 10.15514/ISPRAS-2016-28(4)-8.
16. Ěĺňîä ďîčńęŕ ó˙çâčěîńňč ôîđěŕňíîé ńňđîęč / Č. Ŕ. Âŕőđóřĺâ [č äđ.] // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2015. — Ň. 27. — ą 4. — Ń. 23-34. ISSN 2079-8156. DOI: 10.15514/ISPRAS-2015-27(4)-2
17. Ďŕäŕđ˙í Â. Ŕ. Ŕâňîěŕňčçčđîâŕííűé ěĺňîä ďîńňđîĺíč˙ ýęńďëîéňîâ äë˙ ó˙çâčěîńňč ďĺđĺďîëíĺíč˙ áóôĺđŕ íŕ ńňĺęĺ / Â. Ŕ Ďŕäŕđ˙í, Â. Â. Ęŕóřŕí, Ŕ. Í. Ôĺäîňîâ // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2014. — Ň. 26. — ą 6. — Ń. 127–144. ISSN 2079-8156.
18. Ęîçŕ÷îę Ŕ. Â., Ęî÷ĺňęîâ Ĺ. Â. Îáîńíîâŕíčĺ âîçěîćíîńňč ďđčěĺíĺíč˙ âĺđčôčęŕöčč ďđîăđŕěě äë˙ îáíŕđóćĺíč˙ âđĺäîíîńíîăî ęîäŕ. // Âîďđîńű ęčáĺđáĺçîďŕńíîńňč. — 2016. — Bűď. 3(16). — Ń. 25–32. ISSN 2311-3456.
19. Ŕçűěřčí Č. Ě. Ŕíŕëčç áĺçîďŕńíîńňč ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ / Č. Ě. Ŕçűěřčí, Â. Î. ×óęŕíîâ // Áĺçîďŕńíîńňü číôîđěŕöčîííűő ňĺőíîëîăčé. — 2014. —ą 1. — Ń. 45–47. ISSN 2074-7136.
20. Ńîńíčí Ţ. Â. Ęîěďëĺęń ěŕňĺěŕňč÷ĺńęčő ěîäĺëĺé îďňčěčçŕöčč ęîíôčăóđŕöčč ńđĺäńňâ çŕůčňű číôîđěŕöčč îň íĺńŕíęöčîíčđîâŕííîăî äîńňóďŕ / Ţ. Â. Ńîńíčí, Ă. Â. Ęóëčęîâ, Ŕ. Â. Íĺďîěí˙ůčő // Ďđîăđŕěěíűĺ ńčńňĺěű č âű÷čńëčňĺëüíűĺ ěĺňîäű. . — 2015. — ą 1. — Ń. 32–44. ISSN 2305-6061. DOI: 10.7256/2305-6061.2015.1.14124
21. Ěĺëęîăđŕíóë˙đíŕ˙ đŕíäîěčçŕöč˙ ŕäđĺńíîăî ďđîńňđŕíńňâŕ ďđîăđŕěěű ďđč çŕďóńęĺ / Ŕ. Đ. Íóđěóőŕěĺňîâ [č äđ.] // Ňđóäű číńňčňóňŕ ńčńňĺěíîăî ďđîăđŕěěčđîâŕíč˙ ĐŔÍ. — 2014. — Ň. 29. — ą 6. — Ń. 163–182. — ISSN 2079-8156.
References
1. Revnivykh A. V. Monitoring informatsionnoi infrastruktury organizatsii / A. V. Revnivykh, A. M. Fedotov // Vestnik NGU. Ser.: Informatsionnye tekhnologii. — 2013. — T. 11. — ą 4. — S. 84–91. ISSN 1818-7900. URL: https://nsu.ru/xmlui/bitstream/handle/nsu/1295/2013_V11_N4_8.pdf.
2. Primenenie kompilyatornykh preobrazovanii dlya protivodeistviya ekspluatatsii uyazvimostei programmnogo obespecheniya / A. R. Nurmukhametov [i dr.] // Trudy instituta sistemnogo programmirovaniya RAN. — 2014. — T. 26. — ą
3. S. 113-124. ISSN 2079-8156. 3.Otsenka kritichnosti programmnykh defektov v usloviyakh raboty sovremennykh zashchitnykh mekhanizmov /A. N. Fedotov [i dr.] // Trudy instituta sistemnogo programmirovaniya RAN. — 2016. — T. 28. — ą 5. — S. 73–92. DOI: 10.15514/ISPRAS-2016-28(5)-4
4. Mukhanova A. A. Klassifikatsiya ugroz i uyazvimostei informatsionnoi bezopasnosti v korporativnykh sistemakh / A. A. Mukhanova, A. V Revnivykh, A. M Fedotov // Vestnik NGU. Ser.: Informatsionnye tekhnologii. — 2013. — T. 11. — ą 2. — S. 55-72. ISSN 1818-7900.
5. Revnivykh A. V. Politiki obnovleniya resursov v informatsionnykh sistemakh / A. V. Revnivykh, A. M. Fedotov // Vestnik NGU. Ser.: Informatsionnye tekhnologii. — 2013. — T. 11. — ą 2. —S. 82–105. ISSN 1818-7900.
6. Fedotov A. N. Postroenie predikatov bezopasnosti dlya nekotorykh tipov programmnykh defektov / A. N. Fedotov [i dr.] // Trudy instituta sistemnogo programmirovaniya RAN. — 2017. — T. 29. — ą 6. — S. 151–162. ISSN 2079-8156. DOI: 10.15514/ISPRAS-2017-29(6)-8.
7. Nadezhdin E.N. Analiz uyazvimostei programmnogo obespecheniya pri proektirovanii mekhanizma integrirovannoi zashchity korporativnoi informatsionnoi sistemy / E.N. Nadezhdin, E.I. Shchiptsova, T.L. Shershakova. // Sovremennye naukoemkie tekhnologii. — 2017. — ą 10. — S. 32–38. ISSN 1812-7320. URL: http://www.top-technologies.ru/ru/article/view?id=36824
8. Satton M. Fuzzing: issledovanie uyazvimostei metodom gruboi sily / M. Satton, A. Grin, P. Amini. — SPb.-M.: Simvol-Plyus, 2009. — 560 s. ISBN: 978-5-93286-147-9.
9. Velizhanin A. S. Evristicheskii metod poiska uyazvimostei v PO bez ispol'zovaniya iskhodnogo koda / A. S. Velizhanin, A. V. Revnivykh // XIV Rossiiskaya konferentsiya s mezhdunarodnym uchastiem "Raspredelennye informatsionnye i vychislitel'nye resursy" (DICR-2012). ISBN 978-5-905569-05-0. 26 noyabrya-30 noyabrya 2012, Novosibirsk. URL: http://conf.ict.nsc.ru/files/conferences/dicr2012/fulltext/140768/141800/%D0%A0%D0%B5%D0%B2%D0%BD%D0%B8%D0%B2%D1%8B%D1%85%20%20%D0%AD%D0%B2%D1%80%D0%B8%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9%20%D0%BC%D0%B5%D1%82%D0%BE%D0%B4.pdf
10. Blagodarenko A. V. Razrabotka metoda, algoritmov i programm dlya avtomaticheskogo poiska uyazvimostei programmnogo obespecheniya v usloviyakh otsutstviya iskhodnogo koda: dissertatsiya ... kandidata tekhnicheskikh nauk: 05.13.19 / A. V. Blagodarenko; [Mesto zashchity: Yuzh. feder. un-t]. — Taganrog, 2011. — 140 s.: il. OD 61 12-5/251.
11. Shudrak M. O. Avtomatizirovannyi poisk uyazvimostei v binarnom kode / M. O. Shudrak, T. S. Kheirkhabarov // Reshetnevskie chteniya: materialy XVI Mezhdunar. nauch. konf., posvyashch. pamyati gener. konstruktora raket.-kosmich. sistem akad. M. F. Reshetneva (7–9 noyab. 2012, g. Krasnoyarsk): v 2 ch. / pod obshch. red. Yu. Yu. Loginova; Sib. gos. aerokosmich. un-t. — Krasnoyarsk, 2012. — Ch. 2. — S. 691–692.
12. Voropaev D. P. Issledovanie programmnykh uyazvimostei v komp'yuternykh sistemakh i analiz primenyaemogo programmnogo obespecheniya dlya provedeniya atak na vychislitel'nuyu sistemu / D. P. Voropaev, I. A. Zaugolkov // Vestnik TGU. — 2014. — T. 19. — ą 2. S. — 637–638. ISSN 1810-0198. URL: https://cyberleninka.ru/article/v/issledovanie-programmnyh-uyazvimostey-v-kompyuternyh-sistemah-i-analiz-primenyaemogo-programmnogo-obespecheniya-dlya-provedeniya-atak
13. Mironov S. V. Tekhnologii kontrolya bezopasnosti avtomatizirovannykh sistem na osnove strukturnogo i povedencheskogo testirovaniya programmnogo obespecheniya / S. V.Mironov, G. V. Kulikov // Kibernetika i programmirovanie. — 2015. — ą 5. — S.158–172. ISSN 2306-4196. DOI: 10.7256/2306-4196.2017.1.20351
14. Nepomnyashchikh A. V., Kulikov G. V., Sosnin Yu. V., Nashchekin P. A. Metody otsenivaniya zashchishchennosti informatsii v avtomatizirovannykh sistemakh ot nesanktsionirovannogo dostupa // Voprosy zashchity informatsii. — 2014. — ą 1 (104). — S. 3–12. ISSN 2073-2600.
15. Fedotov A. N. Metod otsenki ekspluatiruemosti programmnykh defektov // Trudy instituta sistemnogo programmirovaniya RAN. — 2016. — T. 28. — ą 4. — S. 137–148. ISSN 2079-8156. DOI: 10.15514/ISPRAS-2016-28(4)-8.
16. Metod poiska uyazvimosti formatnoi stroki / I. A. Vakhrushev [i dr.] // Trudy instituta sistemnogo programmirovaniya RAN. — 2015. — T. 27. — ą 4. — S. 23-34. ISSN 2079-8156. DOI: 10.15514/ISPRAS-2015-27(4)-2
17. Padaryan V. A. Avtomatizirovannyi metod postroeniya eksploitov dlya uyazvimosti perepolneniya bufera na steke / V. A Padaryan, V. V. Kaushan, A. N. Fedotov // Trudy instituta sistemnogo programmirovaniya RAN. — 2014. — T. 26. — ą 6. — S. 127–144. ISSN 2079-8156.
18. Kozachok A. V., Kochetkov E. V. Obosnovanie vozmozhnosti primeneniya verifikatsii programm dlya obnaruzheniya vredonosnogo koda. // Voprosy kiberbezopasnosti. — 2016. — Byp. 3(16). — S. 25–32. ISSN 2311-3456.
19. Azymshin I. M. Analiz bezopasnosti programmnogo obespecheniya / I. M. Azymshin, V. O. Chukanov // Bezopasnost' informatsionnykh tekhnologii. — 2014. —ą 1. — S. 45–47. ISSN 2074-7136.
20. Sosnin Yu. V. Kompleks matematicheskikh modelei optimizatsii konfiguratsii sredstv zashchity informatsii ot nesanktsionirovannogo dostupa / Yu. V. Sosnin, G. V. Kulikov, A. V. Nepomnyashchikh // Programmnye sistemy i vychislitel'nye metody. . — 2015. — ą 1. — S. 32–44. ISSN 2305-6061. DOI: 10.7256/2305-6061.2015.1.14124
21. Melkogranulyarnaya randomizatsiya adresnogo prostranstva programmy pri zapuske / A. R. Nurmukhametov [i dr.] // Trudy instituta sistemnogo programmirovaniya RAN. — 2014. — T. 29. — ą 6. — S. 163–182. — ISSN 2079-8156.
Đĺçóëüňŕňű ďđîöĺäóđű đĺöĺíçčđîâŕíč˙ ńňŕňüč
 ńâ˙çč ń ďîëčňčęîé äâîéíîăî ńëĺďîăî đĺöĺíçčđîâŕíč˙ ëč÷íîńňü đĺöĺíçĺíňŕ íĺ đŕńęđűâŕĺňń˙.
Ńî ńďčńęîě đĺöĺíçĺíňîâ čçäŕňĺëüńňâŕ ěîćíî îçíŕęîěčňüń˙ çäĺńü.
Ďđĺäěĺň čńńëĺäîâŕíč˙ đŕńńěîňđĺí ŕâňîđîě â číňĺđĺńíîě đŕęóđńĺ, ÷ňî, íĺńîěíĺííî, ďđčâëĺ÷ĺň âíčěŕíčĺ íŕó÷íîé îáůĺńňâĺííîńňč.
Ěĺňîäîëîăč˙ čńńëĺäîâŕíč˙, čńďîëüçóĺěŕ˙ ŕâňîđîě, ďîçâîë˙ĺň ńäĺëŕňü âűâîäű, ďđĺäńňŕâë˙ţůčĺ îďđĺäĺëĺííűé íŕó÷íűé číňĺđĺń.
Ďóáëčęŕöč˙ ěîćĺň âűçâŕňü áîëüřîé číňĺđĺń ó ŕóäčňîđčč ćóđíŕëŕ.
Ńňŕňü˙ ńîäĺđćčň ďđčçíŕęč ńóůĺńňâĺííîé íŕó÷íîé íîâčçíű.
Äŕííŕ˙ ńňŕňü˙ őŕđŕęňĺđčçóĺňń˙ ëîăč÷ĺńęîé ďîńëĺäîâŕňĺëüíîńňüţ, óďîđ˙äî÷ĺííîé ńčńňĺěîé ńâ˙çč ěĺćäó ÷ŕńň˙ěč čńńëĺäîâŕíč˙, ÷ňî ńâčäĺňĺëüńňâóĺň î íŕó÷íîě ńňčëĺ čçëîćĺíč˙.
Áčáëčîăđŕôč˙ ńňŕňüč ńîäĺđćčň çíŕ÷čňĺëüíîĺ ÷čńëî ńńűëîę íŕ íŕó÷íűĺ ďóáëčęŕöčč ďî ňĺěĺ čńńëĺäîâŕíč˙.  ńâ˙çč ń ÷ĺě, ńëĺäóĺň îňěĺňčňü áîëüřóţ đŕáîňó ďî ńáîđó íŕó÷íîăî ěŕňĺđčŕëŕ.
 ńňŕňüĺ äŕí ęđŕňęčé, íî äîńňŕňî÷íűé äë˙ ďîíčěŕíč˙ íŕó÷íűő ďđîáëĺě îáçîđ đŕáîň äđóăčő čńńëĺäîâŕňĺëĺé ďî ńőîćĺé ňĺěŕňčęĺ.
Âńĺ âűâîäű, ńäĺëŕííűĺ â ńňŕňüĺ, őîđîřî îáîńíîâŕíű. Ěűńëč ŕâňîđŕ čçëîćĺíű â ńňđîăîé ëîăč÷íîé ďîńëĺäîâŕňĺëüíîńňč č ˙ńíî ńôîđěóëčđîâŕíű.
|
