|
ГЛАВНАЯ
> Вернуться к содержанию
Кибернетика и программирование
Правильная ссылка на статью:
Райхлин В.А., Минязев Р.Ш., Классен Р.К.
Эффективность консервативных СУБД больших объемов на кластерной платформе
// Кибернетика и программирование.
2018. № 5.
С. 44-62.
DOI: 10.25136/2644-5522.2018.5.22301 URL: https://nbpublish.com/library_read_article.php?id=22301
Эффективность консервативных СУБД больших объемов на кластерной платформе
Райхлин Вадим Абрамович
доктор физико-математических наук
профессор, кафедра Компьютерных систем, Казанский национальный исследовательский технический университет им. А.Н. Туполева — КАИ
1420111, Россия, республика Татарстан, г. Казань, ул. К. Маркса, 10
Raikhlin Vadim Abramovich
Doctor of Physics and Mathematics
Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University
1420111, Russia, respublika Tatarstan, g. Kazan', ul. K. Marksa, 10

|
no-form@evm.kstu-kai.ru
|
|
 |
Минязев Ринат Шавкатович
кандидат технических наук
доцент, кафедра Компьютерных систем, Казанский национальный исследовательский технический университет им. А.Н. Туполева — КАИ
1420111, Россия, республика Татарстан, г. Казань, ул. К. Маркса, 10
Minyazev Rinat Shavkatovich
PhD in Technical Science
Associate Professor, Department of Computer Systems, Tupolev Kazan National Research Technical University
1420111, Russia, respublika Tatarstan, g. Kazan', ul. K. Marksa, 10
|
|
txf13@mail.ru
|
|
 |
|
Классен Роман Константинович
аспирант, кафедра Компьтерных систем, Казанский национальный исследовательский технический университет им. А. Н. Туполева — КАИ
420111, Россия, республика Татарстан, г. Казань, ул. К.маркса, 10
Klassen Roman Konstantinovich
Postgraduate Student, Department of Computer Systems, Tupolev Kazan National Research Technical University
420111, Russia, respublika Tatarstan, g. Kazan', ul. K.marksa, 10
|
|
klassen.rk@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2018.5.22301
Дата направления статьи в редакцию:
14-03-2017
Дата публикации:
25-11-2018
Аннотация:
Обсуждаются результаты оригинальных исследований принципов организации и особенностей функционирования консервативных СУБД кластерного типа. Актуальность принятой ориентации на работу с базами данных больших объемов определяется современными тенденциями интеллектуальной обработки больших информационных массивов. Повышение объема баз данных требует их хеширования по узлам кластера. Это обуславливает необходимость использования регулярного плана обработки запросов с динамической сегментацией промежуточных и временных отношений. Дается сравнительная оценка получаемых результатов с альтернативным подходом "ядро на запрос" при условии репликации БД по узлам кластера. Значительное место в статье занимает теоретический анализ возможностей GPU-акселерации применительно к консервативным СУБД с регулярным планом обработки запросов. Экспериментальные исследования проводились на специально разработанных натурных моделях — СУБД Clusterix, Clusterix-M, PerformSys с применением средств MySQL на исполнительном уровне. Теоретический анализ возможностей GPU-акселерации выполнен на примере предлагаемого проекта Clusterix-G. Показаны: особенности поведения СУБД Clusterix в динамике и оптимальный архитектурный вариант системы; повышение "в разы" масштабируемости и производительности системы при переходе к мультикластеризации (СУБД Clusterix-M) либо к перспективной технологии «ядро на запрос» (PerformSys); неконкурентоспособность GPU-акселерации в сравнении с подходом «ядро на запрос» для баз данных средних объемов, не превышающих размеры оперативной памяти узла кластера, но не умещающихся в глобальной памяти графического процессора. Для баз данных больших объемов предложена гибридная технология (проект Clusterix-G) с разделением кластера на две части. Одна из них выполняет селектирование и проецирование над хешированной по узлам и сжатой базой данных. Другая – соединение по схеме «ядро на запрос». Функции GPU-ускорителей в разных частях своеобразны. Теоретический анализ показал бόльшую эффективность такой технологии в сравнении с Clusterix-M. Но вопрос о целесообразности использования графических ускорителей в рамках подобной архитектуры требует дальнейшего экспериментального исследования. Отмечено, что проект Clusterix-M сохраняет жизнеспособность в области Big Data. Аналогично — с подходом «ядро на запрос» при доступности использования современных дорогих информационных технологий.
Ключевые слова:
Консервативные СУБД, Большие данные, Регулярный план обработки, Хеширование по узлам, Динамическая сегментация отношений, Масшабируемость, Производительность, Мультикластеризация, Перспективная технология, Эффективность графических ускорителей
УДК: 681.3
Abstract: The results of original research on the principles of organization and features of the operation of conservative DBMS of cluster type are discussed. The relevance of the adopted orientation to work with large-scale databases is determined by modern trends in the intellectual processing of large information arrays. Increasing the volume of databases requires them to be hashed over cluster nodes. This necessitates the use of a regular query processing plan with dynamic segmentation of intermediate and temporary relationships. A comparative evaluation of the results obtained with the alternative "core-to-query" approach is provided, provided that the database is replicated across cluster nodes. A significant place in the article is occupied by a theoretical analysis of GPU-accelerations with respect to conservative DBMS with a regular query processing plan. Experimental studies were carried out on specially developed full-scale models - Clusterix, Clusterix-M, PerformSys with MySQL at the executive level. Theoretical analysis of the GPU-accelerations is performed using the example of the proposed project Clusterix-G. The following are shown: the peculiarities of the behavior of the Clusterix DBMS in dynamics and the optimal architectural variant of the system; Increased "many times" scalability and system performance in the transition to multiclustering (DBMS Clusterix-M) or to the advanced technology "core-to-query" (PerformSys); Non-competitiveness of GPU-acceleration in comparison with the "core-to-query" approach for medium-sized databases that do not exceed the size of the cluster's memory, but do not fit into the GPU's global memory. For large-scale databases, a hybrid technology (the Clusterix-G project) is proposed with the cluster divided into two parts. One of them performs selection and projection over a hashed by nodes and a compressed database. The other is a core-to-query connection. Functions of GPU accelerators in different parts are peculiar. Theoretical analysis showed greater effectiveness of such technology in comparison with Clusterix-M. But the question of the advisability of using graphic accelerators within this architecture requires further experimental research. It is noted that the Clusterix-M project remains viable in the Big Data field. Similarly - with the "core-to-query" approach with the availability of modern expensive information technologies.
Keywords: Conservative DBMS, Big Data, Regular processing plan, Host hashing, Dynamic relationship segmentation, Scalability, Performance, Multiclusterisation, Advanced technology, GPU-accelerators efficiency
Используемые обозначения – Clusterix, Clusterix-M, Clusterix-G– названия затрагиваемых в статье проектов консервативных СУБД на кластерной платформе, принятые разработчиками этих проектов.
– MySQL – применяемая в этих проектах инструментальная СУБД.
– PerformSys («ядро на запрос», «узел на множество запросов») – перспективная технология консервативных СУБД.
– GPU(Graphics Processing Unit) – сопроцессор, широко применяемый как ускоритель трехмерной графики. Используется и при выполнении обычных вычислений – подход GPGPU (General-Purpose GPU).
– CPU – центральный процессор.
– TPC(Transaction Processing Performance Council) – Совет по производительности обработки транзакций.
– TPC-H – один из тестов производительности систем принятия решений. Введение Проблема масштабируемости по числу узлов кластера и повышения производительности всегда была и остается одной из серьезнейших проблем параллельных СУБД [1-4]. В настоящее время имеется немалое число разработок таких СУБД на платформе вычислительных кластеров. Большинство из них осуществляет поддержку работы internet-сервисов, выполняющих сравнительно простые операций типа selectи insertнад динамически изменяемыми базами данных. Причина в том, что повышение скорости обработки сложных запросов до сих пор проблематично [5]. Наше рассмотрение ориентировано на построение параллельных СУБД консервативного типа (с эпизодическим обновлением данных в специально выделяемое время) больших объемов (до единиц TB). Его актуальность определяется тенденциями интеллектуальной обработки информационных массивов. Примером тому является проект специализированной системы SciDB для обработки научных данных (результатов испытаний, наблюдений за состоянием среды и др.) [6-8]. Для них характерен высокий удельный вес именно сложных запросов типа select – project – join, оперирующих множеством таблиц с большим числом операций соединения join. Такие базы данных приходится хешировать по узлам кластера.
Поэтому единственно приемлемым планом обработки запросов оказывается регулярный [9] (рис.1) по схеме
СЕЛЕКЦИЯ (σ) – ПРОЕКЦИЯ (π) – СОЕДИНЕНИЕ (σθ(R x S)) .
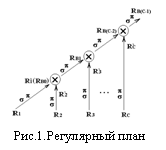 Здесь < x > – декартово произведение, селектирование в операции соединения ведется по θ‑соответствию кортежей отношений R и S. По условиюсоединение всегда естественное и проводится по полям первичного ключа. При использовании стратегии «множество узлов кластера – на один запрос» база данных оказывается распределенной по узлам. Получение любого промежуточного Ri' и любого временного RB(i-2) отношений происходит параллельно. При этом теоретически возможно совмещение обоих процессов, если за время съема с дисков и предварительной обработки (селекции с проекцией) исходного отношения Riуспевает сформироваться временное отношение RB(i-2). Для целей исследования была разработана натурная модель – СУБД Clusterix[10]. Здесь < x > – декартово произведение, селектирование в операции соединения ведется по θ‑соответствию кортежей отношений R и S. По условиюсоединение всегда естественное и проводится по полям первичного ключа. При использовании стратегии «множество узлов кластера – на один запрос» база данных оказывается распределенной по узлам. Получение любого промежуточного Ri' и любого временного RB(i-2) отношений происходит параллельно. При этом теоретически возможно совмещение обоих процессов, если за время съема с дисков и предварительной обработки (селекции с проекцией) исходного отношения Riуспевает сформироваться временное отношение RB(i-2). Для целей исследования была разработана натурная модель – СУБД Clusterix[10].
1. СУБД Clusterix Функциональная характеристика. Обработка запросов – 2-уровневая. На нижнем уровене выполняются операции селекции (σ) и проекции (π) над исходными отношениями Riбазы данных. Результатом обработки этого уровня является промежуточное отношение Ri'. На верхнем уровне реализуется операция соединения RBi–1 = Ri' ►◄ RBi–2 = π (σθ(Ri'xRBi–2)), где RBi–1 и RBi–2 – временные отношения как результаты соединений в i- и в (i-1)-шагах соответственно. Фильтрация на нижнем уровне значительно снижает объемы данных, передаваемых на верхний уровень.
Отношения БД распределены по дискам на процессорах нижнего уровня (IOr) с применением хеш-функции к первичному ключу для каждого кортежа отношения. Требованию равномерного распределения кортежей хорошо удовлетворяет выбор в качестве нее функции деления по модулю [11]. Основание деления – число процессоров нижнего уровня (nIO). Остаток от деления r однозначно определяет номер страницы (процессора IOr), куда будет распределен кортеж. Процессоры верхнего уровня обработки запроса называются процессорами JOIN. Хеш-функция, использованная в Clusterix, имеет следующий вид:
hash=((key_field1 mod M) + (key_field2 mod M) + … + (key_fieldP mod M)) mod M,
где P – количество полей в первичном ключе; M = nIO– основание деления по модулю; mod – операция деления по модулю. Как показали эксперименты на примере теста TPC-H (M=2,3,4,6,8,12,16,18,24), данный подход обеспечивает достаточно равномерное распределение данных по страницам. Хешированные страницы хранятся на узлах IOr в виде отношений базы данных tpchK, где K = r.
Кроме исполнительных процессоров (IOr и JOINj), есть еще два процессора. Процессор УПР реализует функции мониторинга и управления остальными процессорами системы. Для реализации функций объединения результатов обработки с уровня JOIN введен процессор SORT. Он дополнительно выполняет функции агрегации (SUM(), AVG(), MAX(), MIN() и др.) и сортировки результата предшествующей операции соединения. В Clusterix реализован вариант совместной работы процессоров УПР и SORT на Host ЭВМ. Работа на уровне файловой системы, системных буферов, алгоритмов доступа к данным, работы с индексами и т.п. реализуется с помощью стандартной СУБД MySQL.
Система реализует потоково-конвейерный механизм обработки запросов. Конвейерность достигается за счет совмещения работ на нижнем, верхнем уровнях обработки и на уровне SORT (рис.2). Так реализуется вертикальный параллелизм. Его особенностью является совмещение последней операции на уровне JOIN для одного запроса и первой операции на уровне IO для следующего.

В Clusterix реализуется и горизонтальный параллелизм, который достигается параллельной работой нескольких процессоров одного уровня над разными частями данных одного и того же запроса. Применение динамической сегментации промежуточных и временных отношений позволяет реализовать параллельное выполнение операции соединения на множестве процессоров JOINj. Для обеспечения надежной работы системы на всех уровнях применена барьерная синхронизация.
Программная система. Параллельная СУБД Clusterixпредставляет композицию четырех программных модулей: mlisten, msort, irun, jrun. Модуль mlistenреализует функцию логического процессора УПР, модуль msort– SORT, модуль irun– IO, модуль jrun– JOIN. Модули mlisten и msortфункционируют на Host. Назначение модуля mlisten: получение входного запроса от пользователя и передача результатов обработки обратно; пересылка команд управления модулям irun, jrun, msort; мониторинг работы модулей системы; сбор статистической информации. Модуль msortпредназначен для выполнения операции объединения результатов обработки JOIN с последующим выполнением операций агрегации и сортировки результата. Назначение модуля irun – выполнение операций селекции и проекции над исходными отношениями базы данных. На каждом узле уровня IO располагается своя страница исходной БД. Номер этой страницы определяется текущей конфигурацией и присваивается ей при запуске системы. Поэтому каждая страница (и соответствующий ей модуль irun) имеет уникальный номер. То же – и с модулем jrun, который выполняет операции соединения. Количество модулей irunи jrunдля любой конфигурации одинаково. Число физических процессоров, на которых функционируют программные модули irunи jrun, может быть различно.
Моделирование процессов, протекающих в Clusterix, выполнялось при разном числе узлов кластера (физических процессоров) и разном распределении в них программных модулей (логических процессоров). Здесь и далее понятия «логический процессор» и «программный модуль» (irunили jrun) используются как синонимы. На каждом физическом процессоре могут выполняться несколько логических. Общее количество физических процессоров в кластере (включая Host) N=2n+1, где n=1,2,… Величина 2n = p+q, p и q – числа физических процессоров IO и JOIN. В дальнейшем фигурирует их отношение k = q/p.
Рассматривались три типа конфигураций Clusterix: «линейка», «симметрия» и «асимметрия». В конфигурации «линейка» (с условным значением k=0) на каждом физическом процессоре кластера выполняются оба логических процессора: irunи jrun. Модули функционируют в режиме разделения времени при условии барьерной синхронизации. Сихронизация выполняется передачей коротких сетевых сообщений и осуществляется модулем mlisten. Каждый узел кластера имеет устройство внешней памяти. Для конфигурации «симметрия» характерна реализация каждого логического процессора на отдельном физическом процессоре. Любому узлу, на котором выполняется модуль irun, соответствует узел с модулем jrun. Числа узлов JOIN и IO одинаковы: p=q=n, k=1. Конфигурации «асимметрия» предназначена для моделирования таких нагрузок, при которых основная часть работ приходится на узлы IO. Поэтому количество физических процессоров IO больше по сравнению с числом физических процессоров JOIN. На каждом физическом процессоре JOIN выполняется несколько логических процессоров jrun. Исследования показали, что количество совместно работающих логических процессоров jrunна одном узле не должно превышать трех. Поэтому здесь k=1/2, 1/3.
Запросы, на которых проводится тестирование, размещаются в специальном интерфейсном отношении queryсистемной базы данных в оттранслированном виде для каждого из трех программных модулей: irun, jrun и msort. Программа-клиента посылает номер SQL-запроса. Модуль mlistenзапускает для обработки запроса функцию-поток Процесс h, где h – порядковый номер запроса в системе. Процесс h считывает пакет команд запроса из отношения queryи передает его соответствующим модулям для исполнения.
Анализ экспериментальных данных. В качестве представительского теста (ПТ) использовался ограниченный тест TPC-H из 14 запросов, не содержащих операций записи. Далее приводятся результаты модельного эксперимента на натурной модели – СУБД Clustrerix, полученные для двух кластерных платформ [12,13]:
– Платформа 1. Host – cервер Intel Core 4 Xeon 5320 (2,4 GHz, RAM 4GB). Исполнительные узлы – 13 ПК Intel Core 2 Duo 6320 (1,87 GHz, RAM 3GB, жесткий диск SATA 125GB); локальная сеть GigabitEthernet. На каждый компьютер установлена операционная система Linux. Все процессоры дополнительно оснащены СУБД MySQL.
– Платформа 2. Вычислительный кластер фирмы SUN из 22 узлов 2 Quad-core Intel Xeon E5450 CPU/1,87GHz/32GB. Интерконнект между узлами – GigabitEthernet/Infiniband 4X (20Gbps DDR) с 24-портовыми коммутаторами Cisco. Дисковая подсистема узла – SAS диски XRB-SS2CD-146G10KZ с пропускной способностью 300 МB/s. Как и ранее, – Linux, MySQL.
На рис.3a,b приведены экспериментальные зависимости производительности, полученные усреднением на 5 вариантах перестановок запросов ПТ для платформы 1 и разных объемов баз данных.
|
a
 Рис.3. Среднее время выполнения ПТ. Платформа 1. Рис.3. Среднее время выполнения ПТ. Платформа 1.
a) VБД = 1GB; b) VБД = 5,4 GB
|
b

|
Обозначим: hG – граница масштабируемости по числу узлов h, mG – граничное число страниц. Характерно, что для любой конфигурации при h = hG= (1+k)mG производительность кластера всегда максимальна. Эту закономерность подтверждают и ранее проведенные исследования для случая одноядерных узлов [14,15]. Заметим, что параметр mGзависит от используемой платформы и, при неизменных ПТ и схеме БД, растет с увеличением VБД. Граница масштабируемости максимальна для симметрии: hGсим = 2mG. Но переход от «линейки» к «симметрии» при неизменной нагрузке не приводит к существенному увеличению максимума производительности. Для принятого ПТ конфигурация «линейка» оказывается наиболее эффективной.
Случаю 2-процессорных SMP-узлов отвечает платформа 2. По ассоциации с предыдущим ограничимся для нее исследованием конфигурации «линейка». На рис.4a показан полученный для «линейки» график зависимости времени T (сек.) выполнения ПТ от числа рабочих узлов кластера (h) в случае VБД =5,4GB . Видимый порог масштабируемости hG =7-8.
Наличие двух процессоров в узле позволяет существенно улучшить масштабируемость «линейки» и повысить ее максимальное быстродействие на границе масштабируемости. Это достигается установкой на каждый SMP-узел вычислительного кластера двух серверов MySQL. Один из них связан с процессами IO, другой – с процессами Join. В итоге появляется еще одна конфигурация, названная «совмещенная симметрия». Для сравнения производительности конфигураций «линейка» и «совмещенная симметрия» при разном числе узлов проведена обработка последовательности запросов как конкатенации трех перестановок ПТ. Полученные результаты представлены на рис.4b. Тройное увеличение длины и соответствующее изменение характеристики внешней нагрузки нового теста привело к снижению величины hG для «линейки» с 7 до 5. Конфигурация «совмещенная симметрия» показывает hG = 7 с падением Tmin на 25% в сравнении с «линейкой».
|
a

Рис. 4. Платформа 2, VБД = 5,4GB
a) действие ПТ; b) конкатенация 3-х перестановок ПТ
|
b

|
В процессе исследований конфигурации «линейка» дополнительно установлены [16] факты: 1) значительного («в разы») временного доминирования задержек барьерной синхронизации над всеми другими задержками в системе вблизи порога масштабируемости; 2) резкого нарастания задержек на всех этапах обработки при h ≈ 1,5mG; 3) критичности системы к использованию чрезмерного числа узлов в связи с ростом порога масштабируемости при увеличении объемов обрабатываемых баз данных. Интенсивная динамическая сегментация при чрезмерном росте h приводит к перегрузке по интерконнекту и, как следствие, к «зависанию» системы. 2. Мультикластеризация Переход к мультикластеризации, когда на одном достаточно мощном вычислительном кластере реализуется множество одновременно работающих СУБД Clusterix с репликацией между ними консервативной базы данных, должен способствовать росту производительности системы в целом. Такой переход означает изменение идеологии обработки запросов в кластерной системе: от «множества маломощных узлов на один запрос» к одному мощному узлу на каждый запрос». При этом «мощный узел» реализуется как монокластер – компонент кластера в целом с установкой на него системы Clusterix. Число узлов монокластера отвечает грани масштабируемости.
Исследование вопросов мультиклаcтеризации проводилось на модифицированной натурной модели – СУБД Clusterix-M [13]. Host (главная ЭВМ) включает модуль ROUTER, который распределяет поток запросов, поступающих от N клиентов между n монокластерами-компонентами. Поддерживаются два вида очередей запросов – внутренних(в монокластерах) и внешней(в ROUTER). По условию запрос не покидает своей очереди до окончания его обработки. Очередной запрос от каждого пользователя поступает на вход сервера СУБД сразу, как будет получен ответ на предыдущий запрос. Поэтому в любой момент времени суммарное число запросов L, находящихся в сервере, L = N. Суммарная длина всех внутренних очередей Ɩn= r∙n ≤ N, r≥1. Длина внешней очереди L–Ɩn ≥ 0.
Основная задача балансировки нагрузки в мультикластере состоит в нахождении такого способа распределения запросов между монокластерами, который минимизирует (в среднем) время ожидания ответа на вновь поступивший запрос и разброс этого времени. Круговое распределение – наиболее простой и, как показали исследования, достаточно эффективный метод балансировки нагрузки мультикластера. Принятое название об-условлено тем, что первые Ɩn запросов распределяются по монокластерам-компонентам в порядке мест, занимаемых ими в обрабатываемой последовательности:
|
Ɩn–n+1
|
Ɩn–n+2
|
- - -
|
Ɩn
|
← r- запросы
|
|
- - -
|
- - -
|
- - -
|
|
- - -
|
|
+1
|
n+2
|
- - -
|
|
2n
|
|
1
|
2
|
- - -
|
n
|
←1-запросы
|
В дальнейшем всякий раз пополняется та из внутренних очередей, которая первой завершила обработку своего 1-запроса. Считается, что в процессе работы системы значение Ɩn неизменно. По окончании обработки любого 1-запроса освободившееся место занимает очередной запрос из внешней очереди. И в тот же момент на вход СУБД поступает новый запрос. Проведенными исследованиями установлено, что наилучшее решение сформулированной ранее задачи балансировки нагрузки мультикластера круговым способом обеспечивает выбор значения r = 2.
Преимущества мультикластеризации подтверждают результаты проведенного сравнительного тестирования равносложных однокластерных и многокластерных архитектур на платфтормах 1 и 2 (см. раздел 1). Эксперимент проводится на тестовых базах данных объемами VБД = 1GB и 5,4GB. Для обеих платформ в случае мультикластера запросы распределялись между монокластерами по «круговому» алгоритму со значением параметра r = 2. Подсистемой сбора статистической информации СУБД Clusterix фиксировалось среднее время T выполнения ПТ по пяти его перестановкам. Сначала обрабатывалась база данных объемом 1GB на платформе 1. Монокластеры мультикластерной архитектуры конфигурировались как «линейка» с числом узлов hМ ≅ hG=3 (см. рис.3a). Результаты тестирования показаны на рис.5a. При переходе от однокластерной архитектуры к равносложной мультикластерной повышается и масштабируемость, и производительность.
Затем для платформы 2 была проведена обработка последовательности как конкатенации трех перестановок запросов ПТ с объемом базы данных 5,4GB (рис.5b). Монокластеры-компоненты конфигурировались как «совмещенная симметрия», чему соответствует hG=7 (рис.4b). Варьировалось количество монокластеров n и число их узлов hm. В случае hm= 4 наблюдался рост масштабируемости мультикластера по сравнению с однокластерной системой в 2,3 раза; при hМ = 6 – более чем в 2,6 раз. Степень роста производительности на пороге масштабируемости – в 2,4 и не менее чем в 3 раза соответственно.
|
a

Рис.5. Тестирование производительности мультикластера
a) платформа 1; b) платформа 2
|
b

|
3. Один узел кластера на множество запросов До сих пор при работах с базами данных мало используется вычислительный потенциал современных многоядерных процессоров. Примером могут служить рассмотренные реализации СУБД Clusterixи Clusterix-M на SUN-кластере с многоядерными узлами. Использование таких узлов позволяет по иному подойти к решению проблемы создания мощного узла на основе технологии MySQL (либо PostgreSQL). Самостоятельное применение СУБД MySQL последних версий позволяет полностью использовать ресурсы многоядерных узлов с реализацией монокластера на одном узле (стратегия «один узел кластера на множество запросов»). В работе [17] удалось обеспечить 100% загрузку всех ядер при специальной настройке MySQL 5.6.
Полученный на платформе 2 при новых условиях эксперимента (ПТ – случайная последовательность из 800 запросов на множестве запросов ограниченного теста TPC-H), определенной роутеризации в узле и ограничении VБД размерами оперативной памяти ОП узла (вся БД хранится в ОП) график зависимости времени выполнения ПТ в минутах от количества узлов в системе показан на рис.6.

Рис.6. График среднего времени выполнения ПТ
Наблюдается снижение Tminна 25% в сравнении с конфигурацией «совмещенная симметрия» (рис.4b) при неизменном hG=7, прежнем VБД = 5,4 GB и более чем на порядок большем числе обрабатываемых запросов. Но при значительных VБД >VОП такой подход уже неприменим. Здесь, аналогично Clusterix, необходимо применять хеширование БД на множестве узлов кластера с использованием регулярного плана бработки запросов. 4. Применение графических ускорителей Графические ускорители (GPU) уже применяются для ускорения работы СУБД CoGaDb [18], как расширение PG-Storm для Postgres [19] и др. Использование GPU позволяет существенно снизить время выполнения отдельных операций. При VБД ≤ 3GB вся БД может храниться в глобальной памяти GPU (6GB для GPU Fermi). Тогда выполнение сервисных функций (прием запросов, их синтаксический анализ и др.) возлагается на CPU, а обработкой запросов будет заниматься только GPU. Эффективность такой СУБД может быть достаточно высока. При значительных VБД необходимость обмена данными с GPU существенно снижает производительность. Скорость передачи данных по шине PCI-e значительно ниже, чем скорость обмена с оперативной памятью. Так, скорость чтения/записи для 3-канальной оперативной памяти типа DDR3-1600 составляет 38,4 GB/s [20], в то время как для шины PCI-e 2.0x16 – 6,4 GB/s [21]. Именно по этой причине достигнутый в [22] рост производительности сервера БД от использования GPU при обработке достаточно простых одиночных запросов не превысил 40%. Далее рассматривается возможный подход к использованию GPU-акселераторов на уровне IO в случае хранения распределенной базы данных в оперативной памяти узлов в сжатом виде, передачи по сети сжатых отношений Ri' и возможно максимальной загрузке ядер многоядерного процессора на уровне JOIN с применением в нем GPU-акселерации для разжатия поступающих данных.
Сжатие баз данных. Сжатая база данных сохраняется в оперативной памяти узла. Разжатие данных вносит дополнительную задержку в обработку данных на GPU. Эта задержка частично нивелирует выигрыш во времени передачи. Различают СУБД, ориентированные на хранение данных по строкам и по столбцам. Лучшие показатели по сжатию имеют СУБД второго типа. Этот вопрос детально исследован в [23]. Сжатая база данных разделена на блоки. Под блоком данных далее понимается часть сжатого столбца (либо набор «коротких» столбцов) с объемом разжатых данных, равным объему буфера разжатых данных GPU. Алгоритм подготовки данных для сжатия следующий:
1. Найти самое «длинное» поле (длиной RS) в обрабатываемом отношении R.
2. Найти в соответствующем столбце (столбцах) количество записей RC, которое гарантированно умещается в отведенной памяти, RC=[BS/RS], где BS – объем памяти, отведенной для разжатых данных в графическом ускорителе.
3. Выдавать из отношения R данные по столбцам для сжатия с шагом RC.
По условию к каждому IO-узлу по шине PCI-e подключаются 2 графических процессора GPU 1 и GPU 2. Запрос поступает в систему «разбитым» на подзапросы согласно регулярному плану обработки (см. ранее). Для каждой таблицы, участвующей в обработке, проецируется набор колонок, необходимых для выполнения операций «select». В графические укорители GPU 1 и GPU 2 по-блочно последовательно передаются колонки одной таблицы. Пока выполняется расжатие, селектирование одного блока и его сжатие в GPU 1, следующий блок передается в GPU 2 и наоборот. Сжатые результаты возвращаются в хост-память. И так для всех отношений, участвующих в обработке каждого запроса.
Был проведен эксперимент с целью сравнения времен, затрачиваемых на простое копирование, с суммой времен, необходимых для копирования данных, сжатых по алгоритму RLE (Run Length Encoding) [24], и их разжатия в GPU. Эксперимент проводился на базе вычислительного узла с следующими характеристиками: Quad-core Intel Core i5-4670K CPU/2,5GHz/ 24GB RAM (DDR3-1600 в двухканальном режиме), 64-битная ОС Windows 10, дисковая подсистема узла – SSD SV300S37A/ 120GB с пропускной способностью 450 МB/s, GPU – Nvidia GTX 770 (с объемом памяти 2GB GDDR5).
Наибольшая эффективность передачи данных была достигнута для коэффициента сжатия K = 4-5. При бóльшем сжатии увеличивается время разжатия данных, которое может превысить время обычного копирования. В табл.1 показан процент увеличения эффективности передачи сжатых данных (K = 4 и 5) с последующим разжатием по сравнению с простым копированием. Как видно из таблицы, при передаче небольшого объема данных простое копирование оказывается быстрее. При объемах >12 Мбайт предварительное сжатие дает ускорение в окрестности 30% (примерно в 1,5 раза). Для сотен Мбайт можно ожидать ускорение до 40%.
Таблица 1. Изменение эффективности передачи данных
|
Размер (Мбайт)
|
Копирование, мс
|
Копирование и восстановление сжатой информации, мс
|
Увеличение эффективности передачи, %
|
|
K = 4
|
K = 5
|
K = 4
|
K = 5
|
|
0,38
|
1
|
4
|
4
|
-300%
|
-300%
|
|
4,20
|
3
|
6
|
8
|
-167%
|
-100%
|
|
8,01
|
5
|
9
|
9
|
-80%
|
-80%
|
|
11,83
|
7
|
12
|
12
|
-71%
|
-71%
|
|
15,64
|
21
|
15
|
15
|
29%
|
29%
|
|
19,45
|
26
|
20
|
19
|
27%
|
23%
|
|
23,27
|
31
|
23
|
24
|
23%
|
26%
|
|
27,08
|
35
|
26
|
27
|
23%
|
26%
|
|
30,90
|
41
|
30
|
29
|
29%
|
27%
|
|
34,71
|
45
|
35
|
32
|
29%
|
22%
|
|
38,53
|
50
|
35
|
35
|
30%
|
30%
|
|
42,34
|
55
|
38
|
38
|
31%
|
31%
|
|
46,16
|
59
|
41
|
42
|
29%
|
31%
|
|
49,97
|
64
|
44
|
44
|
31%
|
31%
|
|
53,79
|
68
|
48
|
48
|
29%
|
29%
|
|
57,60
|
75
|
50
|
51
|
32%
|
33%
|
|
61,42
|
80
|
53
|
53
|
34%
|
34%
|
Сравнительные оценки времени выполнения операций «select-project» и «join». Используется прежняя платформа, но без GPU. В качестве инструментальной была выбрана СУБД MySQL 5.7. Для запросов прежнего ПТ были сформированы загрузочные модули «select-project» (по каждому Ri) и «join» (по каждому запросу в целом). При этом все операции «project» были «опущены вниз». Объем тестовой БД составил 1GB. Она предварительно загружалась в оперативную память. Сравнивались времена, затрачиваемые на реализацию всех операций «select-project» и единой процедуры «join» по каждому запросу ПТ (см. ниже; ее последовательное выполнение согласно регулярному плану рис.1 оказывается вдвое медленнее), со временами с выполнением этих запросов в целом СУБД MySQL 5.7. Эта процедура выполнялась по следующему алгоритму:
- Создание промежуточных отношений в памяти MySQL для хранения результата «select-project».
- Индексация промежуточных отношений.
- Выполнение операции R1′join (join R2′(join R3′( … ))) … ).
Полученные результаты представлены в табл.2
Таблица 2. Сравнение времен на реализацию по-отдельности операций «select-project», «join»и запроса в целом
|
№ за- проса
|
Время обработки запроса, сек
|
Отношение времен обработки
|
|
Оригинального запроса
|
Выполнение «select-project»
|
Индексация рез-та
«select-project»
|
Выполнение «join»
|
tΣjoin
|
|
|
tобщ
|
tΣσ,π
|
tинд
|
t join
|
tинд+ t join
|
tобщ / tΣσ,π
|
tобщ /tΣjoin
|
|
1
|
21,579
|
9,808
|
0,000
|
0,000
|
0,000
|
2,20
|
нет «join»
|
|
2
|
0,145
|
2,050
|
3,633
|
0,011
|
3,644
|
0,07
|
0,040
|
|
3
|
2,142
|
7,939
|
3,270
|
0,163
|
3,433
|
0,27
|
0,624
|
|
4
|
1,035
|
6,668
|
1,623
|
0,470
|
2,093
|
0,16
|
0,495
|
|
5
|
1,123
|
8,721
|
11,892
|
0,154
|
12,046
|
0,13
|
0,093
|
|
6
|
2,846
|
5,054
|
0,000
|
0,000
|
0,000
|
0,56
|
нет «join»
|
|
7
|
0,901
|
7,624
|
5,506
|
0,261
|
5,767
|
0,12
|
0,156
|
|
8
|
3,335
|
9,837
|
22,394
|
0,081
|
22,475
|
0,34
|
0,148
|
|
9
|
5,315
|
11,355
|
26,805
|
2,234
|
29,039
|
1,00
|
0,183
|
|
10
|
1,850
|
6,707
|
1,614
|
0,944
|
2,558
|
0,28
|
0,723
|
|
11
|
0,229
|
1,896
|
1,209
|
0,069
|
1,278
|
0,12
|
0,179
|
|
12
|
3,760
|
6,561
|
0,809
|
0,075
|
0,884
|
0,57
|
4,253
|
|
13
|
3,302
|
1,833
|
0,714
|
4,703
|
5,417
|
1,80
|
0,610
|
|
14
|
3,270
|
5,339
|
0,198
|
0,264
|
0,462
|
0,61
|
7,078
|
|
Итого
|
50,830
|
91,392
|
79,667
|
9,428
|
89,096
|
0,556
|
0,571
|
Как следует из табл.2, значения tΣσ,π(кроме запросов № 1, 13) и tΣjoin (кроме запросов № 12, 14) превышают tобщ. Это объясняется тем, что MySQL 5.7 оптимизирует исполнение запросов. Усредненные значения tобщ/tΣσ,π= 0,556 и tобщ/tΣjoin = 0,571 примерно одинаковы: tΣjoin /tΣσ,π =0,975. В частности, полученный результат позволяет сделать интересный вывод относительно перспективной стратегии «множество запросов на один узел кластера» с репликацией БД по отдельным узлам, ориентированной на работу с консервативными базами данных умеренных объемов – до 100GB , не превышающих объем оперативной памяти узла (по условию онне превышает 128GB): переход к GPU-кластерам с использованием регулярного плана обработки запросов и адаптацией инструментальных СУБД к такой платформе в этом случае неконкурентоспособен, независимо от места реализации «select–project»- и «join»-обработок: на CPU или GPU. Здесь целесообразна разработка специализированных СУБД с оптимизацией запросов применительно к использованию графических ускорителей [25].
Сжатие данных в результате «select-project»-обработки – полезное для дальнейшего знание. При подсчете объема несжатых данных для любого из рассматриваемых запросов, определялась длина каждого поля каждой строки всех таблиц, участвующих в обработке запроса, и все полученные длины суммировались. Подсчет выполнялся средствами MySQL путем модификации запросов. Пример модификации запроса №3:
-- O'
SELECT O_ORDERDATE, O_SHIPPRIORITY, O_ORDERKEY, O_CUSTKEY
FROM ORDERS
WHERE O_ORDERDATE < DATE '1995-03-31';
-- O' LENGTH
SELECT SUM(LENGTH(O_ORDERDATE), LENGTH(O_SHIPPRIORITY), LENGTH(O_ORDERKEY), LENGTH(O_CUSTKEY))
FROM ORDERS
WHERE O_ORDERDATE < DATE '1995-03-31';
|
Здесь O' – один из подзапросов «select – project», полученных после претрансляции этого запроса; O' LENGTH – запрос для подсчета объема возвращаемых данных. Результаты измерений объемов информации необходимой для обработки запросов приведены в табл.3.
Таблица 3. Объемы данных для обработки запросов TPC-H
|
№ запроса
|
Объем данных для обработки, байт
|
Коэффициент уменьшения объема данных
|
|
До выборки по условиям
|
После выборки по условиям
|
|
|
Vобщ
|
(σ, π)Σ
|
Vобщ/(σ, π)Σ
|
|
1
|
675 846 277
|
134 255 929
|
5,03
|
|
2
|
137 651 393
|
13 526 703
|
10,18
|
|
3
|
855 794 582
|
76 991 966
|
11,12
|
|
4
|
832 798 438
|
428 049 230
|
1,95
|
|
5
|
857 126 234
|
139 324 211
|
6,15
|
|
6
|
675 846 277
|
1 339 256
|
504,64
|
|
7
|
857 125 865
|
78 759 670
|
10,88
|
|
8
|
879 261 359
|
179 338 247
|
4,90
|
|
9
|
970 449 462
|
234 598 226
|
4,14
|
|
10
|
855 796 681
|
49 964 804
|
17,13
|
|
11
|
342 555 947
|
27 528 586
|
12,44
|
|
12
|
832 798 438
|
23 140 549
|
35,99
|
|
13
|
179 948 305
|
18 706 950
|
9,62
|
|
4
|
697 981 402
|
6 548 108
|
106,59
|
|
Итого
|
9 695 098 066
|
1 412 072 435
|
6,87
|
В этой таблице: – полный объем отношений, необходимый для выполнения запроса; – сумма объемов тех же отношений после уменьшения объема данных с использованием условий выборки из запроса (секции where). Имеем, в среднем, примерно 7-кратное уменьшение объема данных.
Анализ для простейшего случая. Рассмотрим пример обработки системой рис.7 с двумя исполнительными узлами (узлы: 1 – IO и 2 – JOIN) и одним управляющим (Mgm) представительского теста ПТ из 14 запросов в случае VБД= 1GB. Все узлы – 12-ядерные. Узел IO (с GPU) выполняет «select–project»-обработку запросов над сжатой БД. Узел JOIN – единые процедуры «join» по каждому запросу ПТ, параллельно по 12 запросам (ядро на запрос). GPU в JOIN выполняет разжатие сжатых отношений Ri' «на проходе», по мере их поступления в JOIN.
При этом, согласно табл.3, суммарный объем отношений, задействованных в процессе выполнения ПТ, Vобщ∑≈ 9,7GB. В результате сжатия исходной информации после «select–project»-обработки остается (σ, π)Σ ≈1,4GB с коэффициентом сжатия Vобщ∑/(σ, π)Σ ≈6,87. Тогда для несжатой БД общий объем информации, передаваемой при обработке ПТ в IO-узле от CPU к GPU и обратно, составит [ Vобщ∑+ (σ, π)Σ ] ≈ 11,1GB. Поскольку предполагается сравнение результатов теоретического анализа с полученными ранее для СУБД Clusterix-M, то рассматривается использование сети GigabitEthernet. Возможными перегрузками по интерконнекту (когда время ожидания передачи по сети для некоторых сообщений превышает значение тайм-аута, что приводит к «зависанию» системы) будем пренебрегать. Полагаем дополнительно, что этапы обработки ПТ в целом («select–project»-обработка → передача ее результата с уровня IO к Mgm и далее – от Mgm на уровень JOIN → собственно «join»-обработка) следуют друг за другом.

Рис.7. Анализируемый простейший случай
Теоретическая скорость передачи по шине PCI-e равна 6,4GB/s. Получение на практике 3,2GB/s можно гарантировать. Поэтому для несжатой БД суммарное время передач информации в каждом IO-узле от CPU к GPU объемом Vобщ∑ составит tп1 = 9,7GB/(3,2GB/s) = 3,03сек, а от GPU к CPU – tп2 = 1,4GB/(3,2GB/s) = 0,44сек. Как нами установлено ранее (см. табл.1), хранение исходной БД в сжатом виде с коэффициентом сжатия K=5 уменьшает tп1 примерно на 40%. Соответственно для 14 запросов ПТ получаем tп′ = (3,03+ 0,44) ∙0,6 = 2,08 сек. Дополнительно необходимо учесть время на передачу сжатых данных по сети GigabitEthernet от IO к Mgm tп'′ = (σ, π)Σ /(5∙υсети) =1,4GB/(5∙0,1GB/s) = 2,8сек. В итоге получаем (tΣσ,π)′ = tп′ +tп'′ = 4,88сек.
Полагаем, что выполнение единых по запросам операций «join» начинается по окончании всех сетевых передач для пакета из 14 запросов непрерывного потока. При оценке общего времени на «join»-обработку (tΣjoin)′ будем учитывать суммарное время передачи tп'′' сжатых отношений Ri′ (последовательно формируемых в BUF) от Mgm на уровень JOIN с поправкой на отсутствие передач Ri′ для запросов №1 и №6, не содержащих операций «join».Сканкатенированные в BUF Mgm части Ri′ этих запросов будут ретранслированы Mgm без дополнительной «join»-обработки. Согласно табл.3, сумммарный объем Ri′ по этим запросам равен 135,6 MB. После сжатия имеем 0,028GB. Поэтому tп'′' = tп'′ –0,28сек = 2,52сек.
Пакет из оставшихся 12 запросов будет параллельно обрабатываться на 12 ядрах узла JOIN. Время «join»-обработки этого пакета (tΣjoin)12 определится самой медленной процедурой. Согласно табл.2, последней завершится обработка по запросу №9, т.е. (tΣjoin)12 ≈ 29,04сек. Общее время (tΣjoin)′ = tп'′' + (tΣjoin)12 = 2,52сек + 29,04сек = 31,56сек. Время обработки системой пакета из 14 запросов T = (tΣσ,π)′ + (tΣjoin)′ = 4,88сек + 31,56сек =36,44сек. Поправка на GPU-разжатие данных в JOIN должна быть ничтожно малой.
СУБД Clusterix-M на платформе 1 с 6-ю исполнительными узлами показала для ПТ (см. рис.5) T1 = 268 сек. Учитывая, что при переходе с платформы 1 на платформу 2, благодаря изменению конфигурации узла от «линейки» к «совмещенной симметрии», время обработки ПТ уменьшается примерно на 25% (см. рис.4б), получаем T2 ≈ 0,75T1 = 201 сек. >> T. Даже принимая во внимание, что исходная БД при проведении эксперимента с Clusterix-M находилась на диске, приходим к выводу: при обработке пакета 14 запросов ПТ и сравнительно небольших VБД рассмотренная простейшая система должна быть значительно эффективнее Clusterix-M.
Принятая к разработке натурная модель Clusterix-G организуется на платформе GPU-кластера КНИТУ-КАИ с шестью исполнительными узлами (узлы 1-6) и одним управляющим (Mgm). Параметры узлов: 2 six-core E5-2640 CPU/2,5GHz/DDR3 128GB; 2 448-core GPU Tesla C-2075/1,15GHz/GDDR5 6GB (на Mgm GPU отсутствуют). Дисковая подсистема узла – RAID-массив 4 WD1000 DHTZ/1TB. Операционная система – SUSE Linux Enterprise Server версии 11. Интерконнект между узлами – GigabitEthernet c 24-портовым коммутатором SSE G24-TG4 /10 GigabitEthernet с 8-портовым коммутатором NETGETAR XS708T-100NES.
Сначала рассмотрим случай равномерного распределения исполнительных узлов (рис.8): узлы 1-3 – IO, узлы 4-6 – JOIN. На все узлы установлена СУБД MySQL 5.7. Сравнительно небольшие размеры используемого GPU-кластера ограничивают возможности проведения исследований на его основе случаем VБД ≤ 200GB. Причина в следующем. Согласно табл.3, суммарный объем промежуточных отношений ПТ ≈ 1,4 VБД. При VБД = 200GB это дает 280GB. Данные такого объема (но не более!) еще можно разместить в оперативной памяти трех узлов JOIN (по условию один узел «принимает» не более 100GB). Из той же таблицы следует, что суммарные объемы Ri' для разных запросов ПТ с «join»-обработкой сильно различаются ~ от 0,0065VБД до 0,428VБД. Так что при действии непрерывного потока запросов, случайно формируемых на множестве запросов ПТ, в каждый момент времени в одном JOIN-узле могут обрабатываться от одного до десяти запросов.

Рис.8. Структура натурной модели Clusterix-G. Случай равномерного распределения исполнительных узлов
По аналогии с ранее разработанными СУБД Clusterix и мультикластерной СУБД Clusterix-M, для целей разработки натурной модели Clusterix-G принят следующий ориентировочный план ее функционирования. Модуль УПР в Mgm ведет очередь запросов, раздает задание на обработку, балансирует нагрузку между узлами IO (в отличие от Clusterixи Clusterix-M, ониработают асинхронно), получает промежуточные и конечные результаты исполнения запросов. Модуль SORT выполняет функции агрегации и сортировки результата обработки запроса. Модуль ROUTER – функцию балансировки нагрузки между узлами JOIN. В буфере BUF по каждому запросу осуществляется конкатенация частей сжатых отношений Ri′ , подлежащих дальнейшему соединению. Функции управления реализуются по сети GigabitEthernet.
На уровне IO последовательно выполняются операции «select – project» по каждому запросу. По условию все операции «project» «опущены вниз».CPU в IO проецируют колонки, формируют блоки сжатой БД, управляют очередью своих команд, работой графических ускорителей (2 GPU на узел), пересылкой сжатых данных по шине PCI-e и сети 10 GigabitEthernet. На уровне JOIN реализуются интегрированные процедуры «join» по запросу в целом.Cредствами MySQL 5.7 оптимизируется их выполнение.Все отношения Ri′ по каждому запросу должны поступить в память узла JOIN перед началом процедуры.
Дадим ориентировочные оценки для случая обработки натурной моделью рис.8 пакета запросов ПТ при VБД = 200GB. Согласно табл.3, будем полагать, что один из узлов JOIN выделяется исключительно для обработки запроса №4, а два других – для обработки остальных 11 запросов с «join».Учтем дополнительно следующее. Дуплексный характер сети передачи данных позволит организовать совмещение передач от IO к Mgm и от Mgm к JOIN. Аналогичный дуплекс по шине PCI-e и использование двух ускорителей в каждом IO-узле позволит совместить во времени разжатие, обработку порции данных, сжатие и передачу результата host-процессору в одном GPU с передачей очередной порции другому GPU. Тогда время собственно «select–project»-обработки определится односторонним обменом CPU →GPU по шине PCI-e.
Соответственно, при условии линейных зависимостей от VБД и в прежних обозначениях: tп′ ≈ tп1 = 3,03сек∙0,6∙200/3 = 121,2сек; tп'′ ≈ 1,4GB∙200/(5∙1GB/s) = 56сек и (tΣσ,π)′ = tп′ +tп'′ ≈ 177,2сек ≈ 0,05 час. Учитывая, согласно табл.2, что (tΣjoin)12 определяется временем «join»-обработки запроса №9, имеем: (tΣjoin)′= (tΣjoin)12 = 200∙29,04 = 5808сек ≈ 1,61 час. Поскольку (tΣjoin)′ >> (tΣσ,π)′, то общее время T обработки ПТ в целом T = (tΣσ,π)′ + (tΣjoin)′ ≈ (tΣjoin)′. Поэтому в блоке IO целесообразно оставить лишь один узел, дополнив блок JOIN до пяти узлов. Тогда (tΣσ,π)′ ≈ 0,12час, что незначительно повлияет на величину T.
Реальная динамика процессов в системепри действии непрерывного потока запросов, случайно формируемых на множестве запросов ПТ, будет существенно более сложной по сравнению с рассмотренной. При этом рост числа узлов JOIN поможет разгрузить BUF Mgm от накопления Ri′ по ожидающим исполнения запросам и будет способствовать повышению производительности системы. Обсуждение При использовании обычных вычислительных кластеров, организация обработки запросов к консервативным БД больших объемов по регулярному плану – пока что объективная закономерность. Это обусловлено необходимостью хеширования таких БД на множестве узлов кластера. Столь же обосновано и динамическое сегментирование промежуточных и временных отношений. Следствием указанных обстоятельств оказывается «квазипараболическая» зависимость времени обработки ПТ от числа узлов (для вычислительных кластеров более характерно приближение к гиперболе). При этом максимум производительности на грани масштабируемости оказывается достаточно низким. Такова в данном случае плата за работу с базами данных больших объемов. Переход к мультикластеризации при ограничении числа узлов в монокластерах-компонентах и использовании архитектуры «совмещенная симметрия» значительно улучшает положение, приближая указанную зависимость к гиперболе. Применение перспективной технологии «один узел кластера на множество запросов» ограничено объемом оперативной памяти узла.
В статье показано, что серьезное повышение эффективности (в сравнении с Clusterix-M) при работе с базами данных сравнительно небольших объемов должно иметь место при переходе на платформу GPU-кластера при условии хранения распределенной БД в сжатом виде в оперативной памяти IO-узлов и организации обработки в JOIN-узлах по схеме «запрос на ядро». В IO-узлах GPU-акселерация используется для реализации операции «select». В JOIN-узлах – для выполнения разжатия «на проходе» последовательно поступающих сжатых промежуточных отношений. Реализация по такому принципу GPU-СУБД объемами до нескольких TB требует построения асимметричных кластеров со сравнительно малым числом IO-узлов, достаточно большим числом JOIN-узлов и скоростной сетью передачи данных. Но имеется ограничительное условие: cуммарный объем промежуточных отношений для любого запроса действующего потока не должен превышать объема оперативной памяти узла.
Представляет интерес вопрос: насколько все же оправдано использование в принятой натурной модели (Clusterix-G) GPU-акселерации, и нельзя ли в данном случае применить схему «запрос на ядро» в блоке IO с хранением несжатой БД в оперативной памяти узла (ОП) и передачей по сети несжатых промежуточных отношений? Поскольку по условию размеры ОП не позволяют загрузку данных объемом >100GB, придется БД хешировать по двум узлам, так что в блоке JOJN останется 4 узла. Но это не повлияет на значение (tΣjoin)′ = 1,61час для ПТ. Время параллельного функционирования блока IO определится величиной tΣσ,π для самого «тяжелого» на ПТ запроса. Согласно табл.3, таковым вновь является запрос №9. Для него tΣσ,π = 11,355сек∙100 = 1135,5сек ≈ 0,32час. Суммарное время передачи Ri′ по сети составит теперь tп'′ ≈ 280сек ≈ 0,078 час. Так что (tΣσ,π)′ = tΣσ,π + tп'′ ≈ 0,4час, тогда как для одного IO-узла с GPU было получено (tΣσ,π)′ ≈ 0,12час. Найденная разница может серьезно повлиять на выбор целесообразного числа JOJN-улов и достижимую производительность при действии непрерывного потока запросов.
Получение окончательного ответа на вопрос об эффективности применения GPU в случае баз данных больших объемов связывается с разработкой и исследованием натурной модели СУБД Clusterix-G.
Как бы то ни было, но последний рассмотренный вариант представляет принципиальное изменение методологии Clusterix. Суть этого изменения состоит в отказе от распределенной обработки запроса на уровне JOIN и от динамического сегментирования промежуточных и временных отношений, что существенно облегчает разработку СУБД в целом и повышает ее эффективыность. Но нельзя забывать о ранее сформулированном условии относительно cуммарного объема промежуточных отношений. Гарантировать его выполнение в общем случае невозможно (пример запроса №4). Снятие этого условия означает возврат к методологии Clusterix-M.
Во избежание переполнения памяти Mgm, каждое Ri′ отсылается в подходящий узел JOJN сразу по окончании накопления этого Ri′ в BUF. Возможные затруднения, связанные с ограниченным объемом узловой оперативной памяти, можно облегчить для узлов JOJN, если предусмотреть в них последовательное (не интегрированное) выполнение операций «join» (согласно рис.1). И хотя такое выполнение вдвое увеличит tΣjoin, но «join»-обработка в целом будет частично совмещена с передачей по сети отношений Ri′.
Выполненный для случая GPU-акселерации анализ в целом имел целью обсуждение принципов высокоэффективного построения консервативных СУБД объемом ≥ 100GB довольно скромными средствами, доступными в настоящее время широкому кругу научно-образовательных организаций. Использование перспективных, но довольно дорогих технологий с объемами оперативной памяти до 2TB и значительным числом ядер (не менее 18) в узле делает подход [17] недосягаемым по эффективности другими известными методами построения большеобъемных консервативных СУБД кластерного типа. Во всяком случае, экспериментальных данных, опровергающих это утверждение, пока не имеется.
Библиография
1. Jae-Woo Chang, Young-Chang Kim. Cluster-based DBMS Management Tool with High-Availability //Journal of Systemics, Cybernetics and Informatics. V. 3. 2005. №1. P.46-51.
2. Ferhatosmanoglu H., Tosun A. S., Canahuate G., Ramachandran A. Efficient parallel processing of range queries through replicated declustering //Distrib. Parallel Databases. 2006. Vol.20, No.2. P.117—147.
3. Ahrendt E. Extreme databases: The biggest and fastest. IBM developer Works //IBM Data Management Magazine Issue 1, 2010. — P.18-23.
4. Stonebraker M. 10 rules for scalable performance in 'simple operation' datastores //Communications of the ACM. 2011. Vol.54, No.6. P.72-80.
5. Xu Y., Kostamaa P., Zhou X., Chen L. Handling data skew in parallel joins in shared-nothing systems //ACM SIGMOD international Conference on Management 9of Data Canada, 2008, proceedings. ACM, 2008. — P.1043-1052.
6. Szalay A.S. The Sloan Digital Sky Survey and beyond //SIGMOD Record. 2008. Vol.37, No.2. P. 61—66.
7. Shiers J. The Worldwide LHC Computing Grid (worldwide LCG) //Computer Physics Communications. 2007. Vol. 177 No. 1-2. P. 219—223.
8. Taniar D., Leung C., Rahayu J. W. High-performance parallel database processing and grid databases. — John Wiley & Sons Inc., Hoboken, 2008. 553 pp. DOI: 10.1002/9780470391365
9. Raikhlin, V.A. Simulation of Distributed Database Machines //Programming and Computer Software. Vol. 22, Issue 2, 1996, P. 68-74.
10. Абрамов Е. В. Параллельная СУБД Clusterix. Разработка прототипа и его натурное исследование // Вестник КГТУ им. А. Н. Туполева. 2006. № 2. С. 50–55.
11. Martin, J. Computer database organization. Second Edition — Prentice-Hall, Inc., Englewood Cliffs, New Jersey 07632, 1977. 662 pp.
12. Raikhlin, V.A., Shagejev D.O. Information clusters as dissapative systems //Nonlinear world. Vol.7. 2009. No.5. P.323-334.
13. Райхлин В. А., Шагеев Д. О. Информационные кластеры как диссипативные системы // Нелинейный мир. 2009. Т. 7. № 5. С. 323–334.
14. Райхлин В.А., Абрамов Е.В. К теории моделей синтеза кластеров баз данных //Вестник КГТУ им. А.Н. Туполева. 2004. No1. C.44-49.
15. Райхлин В.А., Абрамов Е.В. Кластеры баз данных. Моделирование эволюции //Вестник КГТУ им. А.Н. Туполева. 2006. No3. С. 22-27.
16. Райхлин В.А., Минязев Р.Ш. Анализ процессов в кластерах консервативных баз данных с позиций самоорганизации //Вестник КГТУ им. А.Н. Туполева. 2015. No.2. С.120-126.
17. Классен Р.К. Повышение эффективности параллельной субд консервативного типа на кластерной платформе с многоядерными узлами //Вестник КГТУ им. А.Н. Туполева. 2015. No.1. С.112-118.
18. CoGaDB — Column-oriented GPU-accelerated DBMS. URL:http://cogadb.cs.tudortmund.de/wordpress.
19. PGStrom 2016. URL: https://wiki.postgresql.org/index.php?title=PGStrom&oldid=25517.
20. Беседин Д. Первый взгляд на DDR3. Изучаем новое поколение памяти DDR SDRAM, теоретически и практически //ixbt.com. 2007. URL: http://www.ixbt.com/mainboard/ddr3-rmma.shtml (дата обращения: 01.10.2016).ixbt.com. 2007.
21. Петров С.В. Шины PCI, PCI Express. Архитектура, дизайн, принципы функционирования. СПб.: БХВ-Петербург, 2006. 321-322 с.
22. Rauhe H. Finding the Right Processor for the Job Co-Processors in a DBMS, Ilmenau University of Technology, Ilmenau, Dissertation. 125 pp. urn:nbn:de:gbv:ilm1-2014000240, 2014.
23. Wenbin F., Bingsheng H., Qiong L. Database Compression on Graphics Processors //Proc. VLDB Endow., Vol. 3, No. 1-2, Sep 2010. P.670-680.
24. Blelloch G. Introduction to Data Compression. Pittsburgh: Carnegie Mellon University, 2013. P.25-26.
25. Bres S. Efficient query processing in co-processor-accelerated database //University of Magdeburg, 2015. 207 pp.
References
1. Jae-Woo Chang, Young-Chang Kim. Cluster-based DBMS Management Tool with High-Availability //Journal of Systemics, Cybernetics and Informatics. V. 3. 2005. №1. P.46-51.
2. Ferhatosmanoglu H., Tosun A. S., Canahuate G., Ramachandran A. Efficient parallel processing of range queries through replicated declustering //Distrib. Parallel Databases. 2006. Vol.20, No.2. P.117—147.
3. Ahrendt E. Extreme databases: The biggest and fastest. IBM developer Works //IBM Data Management Magazine Issue 1, 2010. — P.18-23.
4. Stonebraker M. 10 rules for scalable performance in 'simple operation' datastores //Communications of the ACM. 2011. Vol.54, No.6. P.72-80.
5. Xu Y., Kostamaa P., Zhou X., Chen L. Handling data skew in parallel joins in shared-nothing systems //ACM SIGMOD international Conference on Management 9of Data Canada, 2008, proceedings. ACM, 2008. — P.1043-1052.
6. Szalay A.S. The Sloan Digital Sky Survey and beyond //SIGMOD Record. 2008. Vol.37, No.2. P. 61—66.
7. Shiers J. The Worldwide LHC Computing Grid (worldwide LCG) //Computer Physics Communications. 2007. Vol. 177 No. 1-2. P. 219—223.
8. Taniar D., Leung C., Rahayu J. W. High-performance parallel database processing and grid databases. — John Wiley & Sons Inc., Hoboken, 2008. 553 pp. DOI: 10.1002/9780470391365
9. Raikhlin, V.A. Simulation of Distributed Database Machines //Programming and Computer Software. Vol. 22, Issue 2, 1996, P. 68-74.
10. Abramov E. V. Parallel'naya SUBD Clusterix. Razrabotka prototipa i ego naturnoe issledovanie // Vestnik KGTU im. A. N. Tupoleva. 2006. № 2. S. 50–55.
11. Martin, J. Computer database organization. Second Edition — Prentice-Hall, Inc., Englewood Cliffs, New Jersey 07632, 1977. 662 pp.
12. Raikhlin, V.A., Shagejev D.O. Information clusters as dissapative systems //Nonlinear world. Vol.7. 2009. No.5. P.323-334.
13. Raikhlin V. A., Shageev D. O. Informatsionnye klastery kak dissipativnye sistemy // Nelineinyi mir. 2009. T. 7. № 5. S. 323–334.
14. Raikhlin V.A., Abramov E.V. K teorii modelei sinteza klasterov baz dannykh //Vestnik KGTU im. A.N. Tupoleva. 2004. No1. C.44-49.
15. Raikhlin V.A., Abramov E.V. Klastery baz dannykh. Modelirovanie evolyutsii //Vestnik KGTU im. A.N. Tupoleva. 2006. No3. S. 22-27.
16. Raikhlin V.A., Minyazev R.Sh. Analiz protsessov v klasterakh konservativnykh baz dannykh s pozitsii samoorganizatsii //Vestnik KGTU im. A.N. Tupoleva. 2015. No.2. S.120-126.
17. Klassen R.K. Povyshenie effektivnosti parallel'noi subd konservativnogo tipa na klasternoi platforme s mnogoyadernymi uzlami //Vestnik KGTU im. A.N. Tupoleva. 2015. No.1. S.112-118.
18. CoGaDB — Column-oriented GPU-accelerated DBMS. URL:http://cogadb.cs.tudortmund.de/wordpress.
19. PGStrom 2016. URL: https://wiki.postgresql.org/index.php?title=PGStrom&oldid=25517.
20. Besedin D. Pervyi vzglyad na DDR3. Izuchaem novoe pokolenie pamyati DDR SDRAM, teoreticheski i prakticheski //ixbt.com. 2007. URL: http://www.ixbt.com/mainboard/ddr3-rmma.shtml (data obrashcheniya: 01.10.2016).ixbt.com. 2007.
21. Petrov S.V. Shiny PCI, PCI Express. Arkhitektura, dizain, printsipy funktsionirovaniya. SPb.: BKhV-Peterburg, 2006. 321-322 s.
22. Rauhe H. Finding the Right Processor for the Job Co-Processors in a DBMS, Ilmenau University of Technology, Ilmenau, Dissertation. 125 pp. urn:nbn:de:gbv:ilm1-2014000240, 2014.
23. Wenbin F., Bingsheng H., Qiong L. Database Compression on Graphics Processors //Proc. VLDB Endow., Vol. 3, No. 1-2, Sep 2010. P.670-680.
24. Blelloch G. Introduction to Data Compression. Pittsburgh: Carnegie Mellon University, 2013. P.25-26.
25. Bres S. Efficient query processing in co-processor-accelerated database //University of Magdeburg, 2015. 207 pp.
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|





