|
ГЛАВНАЯ
> Вернуться к содержанию
Историческая информатика
Правильная ссылка на статью:
Кузнецов А.В.
Компьютерный анализ текстов на латинском языке: Латентно-семантический анализ «Истории готов, вандалов и свевов» Исидора Севильского
// Историческая информатика.
2020. № 2.
С. 202-217.
DOI: 10.7256/2585-7797.2020.2.32961 URL: https://nbpublish.com/library_read_article.php?id=32961
Компьютерный анализ текстов на латинском языке: Латентно-семантический анализ «Истории готов, вандалов и свевов» Исидора Севильского
Кузнецов Алексей Валерьевич
кандидат исторических наук
научный сотрудник, Институт всеобщей истории РАН
119334, Россия, г. Москва, Ленинский проспект, 32 а, оф. 1426
Kuznetsov Alexey
PhD in History
Research worker, General History Institute of the Russian Academy of Sciences
119334, Russia, g. Moscow, Leninskii prospekt, 32 a, of. 1426

|
kuznetsovaleks@rambler.ru
|
|
 |
|
DOI: 10.7256/2585-7797.2020.2.32961
Дата направления статьи в редакцию:
22-05-2020
Дата публикации:
30-07-2020
Аннотация:
В статье предпринимается попытка с использованием современных методов интеллектуального анализа текстов исследовать латиноязычный текст хроники «История готов, вандалов и свевов» выдающегося богослова и ученого VII века Исидора Севильского. Ставится цель проверить выдвинутую в историографии гипотезу о наличии у автора представлений об определенной иерархии варварских народов. Основное внимание направлено на раскрытие неявных семантических взаимоотношений между различными частями произведения с целью уточнения отношения автора к трем варварским народам. Анализ текста проводился на языке программирования R. В качестве конкретного метода бы выбран метод латентно-семантического анализа, позволяющий проводить сравнение и кластеризацию текстов на основе семантического пространства, построенного путем сингулярного разложения терм-документной матрицы. Новизна исследования заключается в том, что впервые реализован полный цикл латентно-семантического анализа средневекового латиноязычного текста. Проведена предварительная подготовка, построено семантическое пространство текста памятника, осуществлено сравнение семантической схожести текстов на основе меры косинусного сходства. Результаты анализа позволяют утверждать, что Исидор Севильский действительно выстраивает иерархию из трех варварских народов, придавая большее сходство описанию вестготов и свевов и особняком ставя вандалов.
Ключевые слова:
Исидор Севильский, раннесредневековая историография, компьютерный анализ текстов, латентно-семантический анализ, сингулярное разложение, кластерный анализ, семантическое пространство, интеллектуальный анализ текста, векторная модель текстов, терм-документная матрица
Abstract: The article attempts to study the Latin text of the chronicle “Historia de regibus Gothorum, Wandalorum et Sueborum” written by the famous 17th c. theologist and scholar Isidoro de Sevilla by means of advanced methods of intellectual text analysis. The main goal is to verify the hypothesis that the author had ideas about the hierarchy of barbarians. The main focus is to clarify the implicit semantic relationship between different parts of the chronicle in order to find out the author’s attitude to these three barbaric groups. The analysis of the text was performed with the R programming language. The specific method is that of latent semantic analysis providing for comparing clustering of texts on the basis of semantic space designed through the singular decomposition of term-document matrix. The research novelty of the study is that it is the first time when a full cycle latent semantic analysis of a Medieval Latin text has been performed which covered the text preprocessing, the creation of the semantic space and the calculation of the semantic similarity of texts on the basis of cosine similarity measure. The analysis results suggest that Isidoro de Sevilla really built the hierarchy of three barbarian groups providing greater similarity to the description of the Visigoths and the Suebi and putting the Vandals apart.
Keywords: Isidore of Seville, early Middle Age historiography, computational text analysis, latent semantic analysis, singular value decomposition, cluster analysis, semantic space, text mining, vector space text representations, term-document matrix
Введение
Исидор Севильский (ок. 560–636) известен как выдающийся ученый, богослов, церковный и политический деятель конца VI – начала VII веков, энциклопедист, внесший неоценимый вклад в сохранение и творческую переработку античного наследия. Высокий интерес к творчеству Исидора Севильского сохраняется с 1960-х гг., когда отмечался его 1400 летний юбилей [1, с. 205]. Среди множества проблем в поле зрения исследователей его трудов одной из наиболее часто рассматриваемых в настоящее время является, пожалуй, проблема отражения в них формирования национальной, политической и религиозной идентичности в государстве вестготов [2, 3, 4, 5]. В сравнительно недавно увидевшей свет монографии Дж. Вуд выдвинул гипотезу о наличии в исторических сочинениях Исидора единой программы, направленной на обоснование политического и религиозного господства вестготов в Испании [3, p.77, p. 159-260]. В «Истории готов, вандалов и свевов», по мнению Дж. Вуда, он выстраивает своеобразную иерархию варварских народов, на вершине которой располагаются вестготы [3, p. 153-161]. Другие варварские народы сознательно умаляются и делигитимизируются. Ярче всего это проявляется в используемых Исидором системах датирования исторических событий. В разделе, посвященном истории вестготов, он применяет двойную систему хронологических указателей – отмечает год в соответствии с Испанской эрой (отсчет лет с 1 января 38 года до н. э.) и соответствующий ему год правления римских императоров, а в разделах, посвященных истории вандалов и свевов, только по годам Испанской эры [3, p. 156]. Особенно негативный образ Исидор создает вандалам, неоднократно указывая на их приверженность арианской вере. В противоположность им свевы, создавшие на северо-западе Испании собственное королевство и одновременно с вестготами перешедшие в никейскую веру, наделяются определенной религиозной и политической легитимностью. Исследователь выдвигает тезис, согласно которому Исидор таким образом подчеркивает, что свевы являются наиболее подходящим объектом для вестготского господства [3, p. 161]. Предположения Дж. Вуда были, впрочем, подвергнуты критике за недостаточную обоснованность его выводов текстами источников [6, с. 129]. В данной статье мы предполагаем попробовать значительно глубже понять отношение Исидора к трем варварским народам, раскрыть неявные идеи и смыслы, содержащиеся в «Истории готов, вандалов и свевов», используя метод латентно-семантического анализа – один из методов интеллектуального анализа текстов (англ. text mining). Интеллектуальный анализ текстов – это направление в искусственном интеллекте, цель которого получение информации из неструктурированных текстовых данных путём их преобразования в пригодный для анализа набор структурированных данных при помощи методов обработки естественного языка (англ. Natural Language Processing, NLP) и машинного обучения (англ. Machine Learning) [7, p. 1-15].
Метод латентно-семантического анализа
Применительно к анализу текстов на естественном языке латентно-семантический анализ (англ. Latent Semantic Analysis, LSA) понимается как метод, раскрывающий взаимосвязь между набором документов и термами (словами, n-граммами), представленными в виде векторов в многомерном латентно-семантическом пространстве [8, p. 111-113]. Под вектором документа понимается вектор, координатами которого являются частоты вхождений термов словаря в этот документ. Теоретическим основанием латентно-семантического анализа является так называемая дистрибутивная гипотеза, согласно которой, слова со схожим значением имеют тенденцию встречаться в схожих контекстах [9]. В латентно-семантическом пространстве представленные в виде векторов слова и документы, сходные по значению, будут стремиться находиться в близких областях пространства, что дает возможность сравнивать семантические значения слов и документов. Сравнение в большинстве случаев реализуется путем вычисления косинуса угла между векторами соответствующих слов и документов [10, p. 931],[11, p.84-87].
Часто латентно-семантический анализ рассматривают в контексте развития методов тематического моделирования [12],[13, p. 368-389], то есть способов построения моделей коллекции текстовых документов на основе анализа совместной встречаемости термов, которые определяют, к каким те мам относится каждый из документов, и какие термы образуют эти темы. Тематическое моделирование помогает обнаружить в коллекции документов скрытые темы, аннотировать документы с помощью этих тем и организовывать большой объем неструктурированных данных. Такой подход к латентно-семантическому анализу верен лишь отчасти, поскольку область применения этого метода значительно шире рамок тематического моделирования.
Впервые латентно-семантический анализ был описан и запатентован в конце 1980-х годов под наименованием латентно-семантическое индексирование (англ. Latent Semantic Indexing) [14, 15] как метод автоматического индексирования текстов и информационного поиска [16]. Его использование позволило повысить эффективность работы информационно-поисковых систем, преодолев две основные сложности в информационном поиске: полисемию (многозначность терминов) и синонимию (сходство значения различных слов) [17, с. 411-412]. Этот метод также успешно используется для решения других задач обработки естественного языка, в том числе для автоматического поиска рецензентов [18], реферирования текстов [19], тематического моделирования [12, с. 219-222]. Несколько позднее метод латентно-семантического анализа стал успешно использоваться в психологии для построения когнитивных моделей понимания и формирования знания [20, 22],[21, с. 19-20] моделей долговременной и кратковременной памяти у детей разного школьного возраста на базе детских текстов [23], оценки понимания текстов [24]. Отдельно стоит отметить, что латентно-семантический анализ нашел применение в системах тестирования знаний, в случаях, когда надо проверить правильность ответов в свободной форме [20]. Для нас наиболее значимым является то, что латентно-семантический анализ был и остается одним из наиболее эффективных методов классификации и индексации текстов, оценки их семантической близости [25, 26, 27].
Экспериментальная часть
Латентно-семантический анализ проводился с использованием латинского текста «Истории готов, вандалов и свевов» из первого издания в Patrologia Latina Жак-Поль Миня [28]. Электронный текст памятника доступен в «Patrologia Latina Database» [29], а также на сайте проекта «The Latin Library» [30].
Для проведения латентно-семантического анализа части произведения Исидора Севильского были представлены в виде отдельных документов. Обычно в сочинении выделяются четыре части «Пролог» (Prologus), известный также под названием «Похвала Испании» (Laus Spaniae), и три части посвященные соответственно истории готов, вандалов и свевов. В первой части (главы 1-70) речь идет о происхождении готов, переселении их на земли Римской империи, создании готских королевств, правлению вестготских королей в Испании и объединении всей Испании под их властью. В конце первой части (главы 66-70) расположены «Выводы» (Item recapitulatio ejusdem Isidori in Gothorum laudem) краткое изложение истории готов. «Выводы» мы также выделили в отдельный документ. Как и «Пролог» они стилистически отличающиеся от всего текста и по аналогии с «Похвалой Испании» представляет собой своеобразную «Похвалу готам». Во второй части (главы 71-84) рассказывается о нашествии вандалов, создании их государства в Испании и Африке и о падении их государства. В третьей части – об образовании королевства свевов в Испании и их присоединении к королевству вестготов. Таким образом мы будем анализировать всего пять документов: «Пролог», «Историю готов», «Выводы», «Историю вандалов», «Историю свевов».
Анализ текста проводился при помощи среды программирования R. Текст скрипта на языке R и все ресурсы доступны в репозитории сервиса GitHub [31].
В обобщенном виде латентно-семантический анализ текста применительно к классификации документов и сравнению их семантической близости включает следующие этапы [10, p. 931],[11, p.80-87],[32, p. 456-460]:
1) предварительная обработка текста;
2) создание терм-документной матрицы из набора документов;
3) взвешивание термов в терм-документной матрице;
4) создание семантического пространства набора документов;
5) сравнение векторов термов или документов в латентном семантическом пространстве, путем вычисления косинуса угла между векторами или другим методом.
Предварительная обработка текстов является важнейшим этапом для любых методов и приемов интеллектуального анализа текстов, от неё во многом зависят полученные результаты. Цель предварительной обработки – преобразовать неструктурированные тексты в пригодный для анализа формат данных при помощи методов обработки естественного языка. В зависимости от стоящих задач предварительная обработка текста может включать в различном сочетании следующие операции [7, p. 37-44],[11, p. 45-59],[33]: 1. Токенизация – разбиение текста на фрагменты (абзацы, предложения, слова, N-граммы). 2. Очистка текста – удаление лишних пробелов и пустых строк, типографских знаков, чисел, знаков препинания, перевод всех букв в нижний регистр. 3. Удаление стоп-слов – малозначимых и низкоинформативных (как правило, служебные части речи, местоимения, числительные). 4. Лемматизация – приведение слова к словарной форме (в латинском языке словарная форма глаголов соответствует форме первого лица единственного числа, существительных и прилагательных – именительному падежу единственного числа) или стемминг – выделение основы слова. Отметим, что стемминг для латиноязычных текстов не применим, поскольку приведет к потере или искажению значимой информации. 5. Частеречная разметка – определение части речи и морфологической формы слов в тексте. 6. Синтаксический парсинг – определение синтаксических зависимостей слов в предложении.
Предварительная обработка латиноязычных текстов имеет свою специфику, обусловленную развитой системой словоформ [33], без приведения которых к словарной форме адекватный анализ текста провести невозможно. Обработка текста «Истории готов, вандалов и свевов» Исидора Севильского была проделана с использованием пакетов tm [34] и UDPipe [35]. При помощи пакета tm буквы были переведены в нижний регистр, удалены числа и знаки препинания. Для удаления стоп-слов был составлен собственный их список. За основу взят список латинских стоп-слов проекта Perseus Digital Library [36], в который дополнительно были добавлены римские цифры во множестве присутствующие в тексте, а также некоторые часто встречающиеся, но малоинформативные слова. В их числе такие как «annus», «aera» используемые Исидором для обозначения дат. Далее с помощью пакета UDPipe текст был разбит на предложения, проведена лемматизация. Как результат – сформирована таблица данных (data frame), в которой для каждого слова в тексте приведена информация о начальной форме слова (лемме), морфологической форме слова и синтаксической роли в предложении.
На основе созданной с помощью пакета UDPipe таблицы данных можно сформировать матрицу терм-документ (term-document matrix) – базу латентно-семантического анализа, математическую матрицу, описывающую частоту терминов в коллекции документов [11, p.77],[32, p. 458-459]. В такой матрице каждый столбец соответствуют документу, а строки – термам (словам, фразам, N-граммам или как в нашем случае – леммам). Количество столбцов равно количеству документов, а количество строк – размеру словаря всей коллекции документов, числа в ячейках обозначают количество встречаемости слов в каждом из документов (см. табл. 1).
|
|
1
|
2
|
3
|
4
|
5
|
|
accipio
|
0
|
1
|
0
|
1
|
2
|
|
acies
|
0
|
3
|
0
|
0
|
0
|
|
adeo
|
0
|
11
|
1
|
0
|
0
|
|
africus
|
0
|
3
|
0
|
7
|
1
|
|
agilanis
|
0
|
3
|
0
|
0
|
0
|
|
alanus
|
0
|
0
|
1
|
2
|
0
|
|
alaricus
|
0
|
6
|
0
|
0
|
0
|
|
aliquandiu
|
0
|
3
|
0
|
0
|
0
|
|
anteus
|
0
|
3
|
0
|
0
|
0
|
|
antiquus
|
0
|
2
|
1
|
0
|
0
|
|
apostolus
|
0
|
3
|
0
|
0
|
0
|
Таблица 1. Матрица терм-документ (фрагмент).
Перед формированием латентно-семантического пространства, как правило, рассчитывают значимость или иначе вес терма в документе относительно всего корпуса документов. Делается это для того, чтобы в ходе анализа повысить значимость низкочастотных слов и одновременно понизить значимость высокочастотных слов. Практика показывает, что использование взвешивания в латентно-семантическом анализе дает лучший результат, чем без взвешивания, поскольку именно низкочастотные слова точнее отражают содержание документа [37]. Кроме того применения взвешивания позволяет снизить влияние размера текстов при их анализе [38] Сейчас разработано большое число алгоритмов определяющих значимость слов [8, p. 93-95], но чаще всего применяется статистическая мера частотность терминов-обратная частотность документов или TF-IDF (от англ. term frequency – inverse document frequency).
Частотность терминов (term frequency, TF) – это величина, показывающая насколько часто слово встречается в документе. Она дает возможность оценить важность данного слова в пределах конкретного документа. Рассчитывается как частное от деления количества раз, которое слово встречается в тексте, и общего количества слов в тексте. Обратная частотность документов (inverse document frequency, IDF) – это инверсия частотности, с которой определенное слово встречается в коллекции документов. Она рассчитывается как логарифм от общего количества документов, делённого на количество всех документов, в которых встречается конкретное слово. Статистическая мера TF-IDF рассчитывается как произведение TF и IDF [17, с. 134-137].
При применении статистической меры TF-IDF к терм-документной матрице значения в её ячейках меняются (см. табл. 2). Вес терма увеличивается, если он встречается множество раз в небольшом количестве документов, тем самым усиливая их уникальность. Вес терма уменьшается, если он встречается небольшое количество раз в одном документе или во множестве документов, снижая их уникальность. Вес терма будет минимальным, если он во множестве встречается в большинстве документов [17, с. 136].
|
|
1
|
2
|
3
|
4
|
5
|
|
accipio
|
0.000000
|
1.736966
|
0.000000
|
1.736966
|
3.473931
|
|
acies
|
0.000000
|
9.965784
|
0.000000
|
0.000000
|
0.000000
|
|
adeo
|
0.000000
|
25.541209
|
2.321928
|
0.000000
|
0.000000
|
|
africus
|
0.000000
|
5.210897
|
0.000000
|
12.158759
|
1.736966
|
|
agilanis
|
0.000000
|
9.965784
|
0.000000
|
0.000000
|
0.000000
|
|
alanus
|
0.000000
|
0.000000
|
2.321928
|
4.643856
|
0.000000
|
|
alaricus
|
0.000000
|
19.931569
|
0.000000
|
0.000000
|
0.000000
|
|
aliquandiu
|
0.000000
|
9.965784
|
0.000000
|
0.000000
|
0.000000
|
|
anteus
|
0.000000
|
9.965784
|
0.000000
|
0.000000
|
0.000000
|
|
antiquus
|
0.000000
|
4.643856
|
2.321928
|
0.000000
|
0.000000
|
|
apostolus
|
0.000000
|
9.965784
|
0.000000
|
0.000000
|
0.000000
|
Таблица 2. Матрица терм-документ (фрагмент) после применения статистической меры TF-IDF.
На основе подготовленной таким образом терм-документной матрицы мы построили семантическое пространство при помощи пакета lsa [39]. Пакет lsa наиболее популярный инструмент для латентно-семантического анализа в среде R. Он хорошо документирован, имеются подробные руководства для работы с ним [32, p. 450-496].
Семантическое пространство формируется путем применения к матрице терм-документ сингулярного разложения (англ. Singular Value Decomposition, SVD). Математические основы сингулярного разложения применительно к латентно-семантическому анализу неоднократно подробно описаны [11, p.79-80],[40]. Подготовленная нами матрица первоначально раскладывается на три матрицы, согласно формуле: M = U*Vt*S, где M – исходная матрица, U – ортогональная матрица документов, Vt – ортогональная транспонированная матрица термов, а S – диагональная матрица. Если в диагональной матрице S оставить только k наибольших сингулярных значений, а в матрицах U и Vt только соответствующие этим значениям столбцы и строки, то мы получим три новые уменьшенные матрицы Uk, Vtk и Sk. Произведение трех новых уменьшенных матриц даст нам новую матрицу Mk, которая максимально приближена к исходной матрице M, но имеет меньший ранг, равный k. Иными словами матрица Mk будет наилучшей малоранговой аппроксимацией матрицы M. В этом случае строки матрицы Uk будут образами термов, а столбцы матрицы Vtk – образами документов в k – мерном семантическом пространстве – Mk.
Матрица Mk будет целиком отображать структуру скрытых зависимостей документов и термов матрицы M, но одновременно обладать рядом преимуществ. Она станет меньше по размеру, поэтому её анализ потребует меньше ресурсов, у неё будет ниже разреженность (значительно меньше пустых ячеек), она будет содержать только самые сущностные семантические отношения документов и слов, игнорируя несущественный шум (главным образом синонимию и полисемию слов) и раскрывая скрытые смыслы в документах и термах [41, p. 159-160].
В качестве эксперимента построим семантическое пространство как на основе терм-документной матрицы, к которой была применена статистическая мера TF-IDF, так и на основе первоначальной матрицы без взвешивания.
Для наглядности покажем положение документов в семантическом пространстве сделав их проекцию на плоскости (см. рис. 1) и в трехмерном пространстве (см. рис. 2). В первом случае мы видим, что из пяти, анализируемых нами частей «Истории готов, вандалов и свевов» Исидора Севильского, «Пролог», «Выводы» к истории готов и «История свевов» составляют плотную группу. Однако следует учитывать, что проекция векторов многомерного пространства на плоскость не дает нам возможности на этом основании судить о схожести документов.
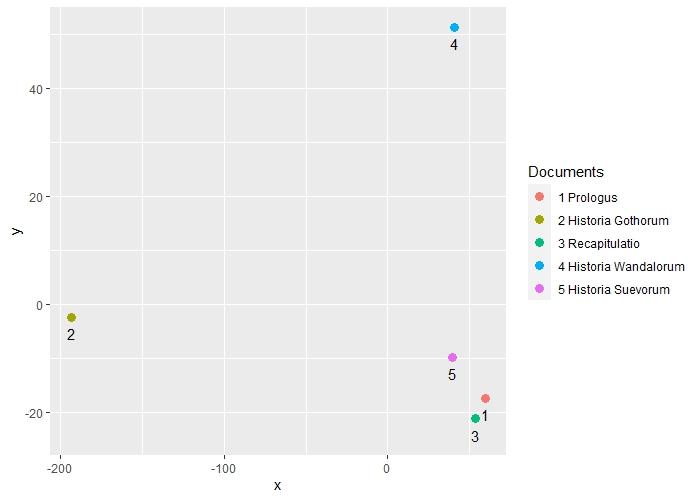
Рисунок 1. Проекция документов в семантическом пространстве «Истории готов, вандалов и свевов» на плоскость.
Проекция документов в семантическом пространстве в трех измерениях также не дает возможности судить о семантической схожести документов, поскольку и здесь есть доля условности из-за сокращения количества измерений. Как мы уже отмечали выше, наиболее часто используемым способом оценить схожесть документов в векторном семантическом пространстве является расчет меры косинусного сходства (англ. cosinus similarity) – косинуса угла между векторами. На примере проекции документов в семантическом пространстве в трех измерениях будет рассчитываться косинус угла между векторами, начинающимися в точке с координатами [0,0,0], помеченной красным треугольником, и заканчивающимися в точках помеченных кружочками (см. рис. 2).
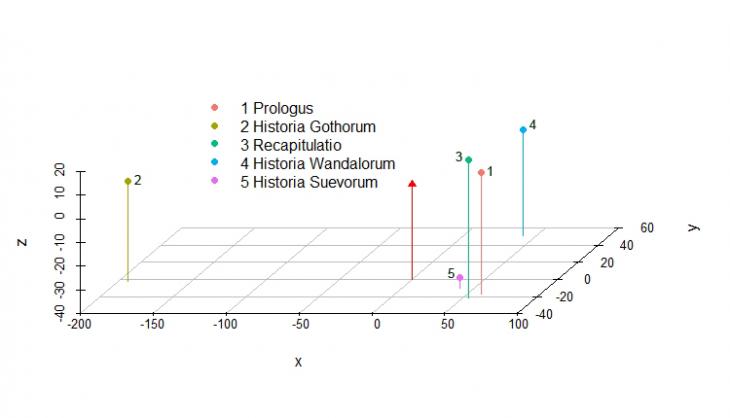
Рисунок 2. Проекция документов в семантическом пространстве «Истории готов, вандалов и свевов» в трех измерениях.
Теоретически, значение косинуса угла между векторами может варьироваться между -1 (полная оппозиция) до 1 (полная идентичность). В случае с векторным представлением текстов в семантическом пространстве косинус угла между векторами может принимать значения от 0 (соответствует углу 90°) до 1, поскольку частота терма или статистическая мера TF-IDF не могут принимать отрицательное значение. Угол между двумя векторами документов или слов в семантическом пространстве не может быть больше, чем 90°. Чем выше будет значение косинуса угла между векторами документов, тем о большем семантическом сходстве документов можно говорить.
На основе сформированного семантического пространства была построена матрица косинусного сходства. Результаты визуализированны в виде тепловой карты (см. рис. 3). Полученные данные свидетельствуют, что среди выделенных нами частей «Истории готов, вандалов и свевов» Исидора Севильского наибольшей семантической схожестью обладают «История готов» и «История свевов», степень сходства между остальными частями значительно меньше.
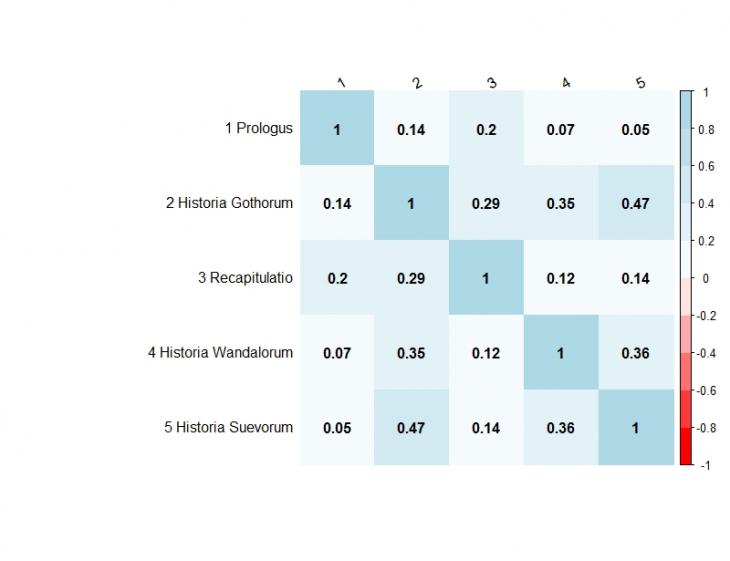
Рисунок 3. Визуализация матрицы косинусного сходства для частей «Истории готов, вандалов и свевов» в виде тепловой карты. С использованием статистической меры TF-IDF.
Матрица косинусного сходства, построенная на основе семантического пространства без использования статистической меры TF-IDF, дает другие значения, но тенденции остаются прежние: наибольшей семантической схожестью обладают «История готов» и «История свевов» (см. рис. 4).
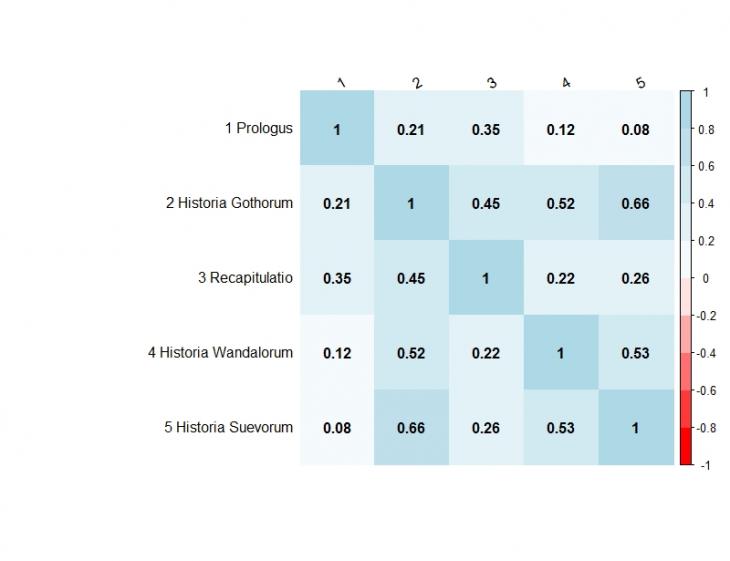
Рисунок 4. Визуализация матрицы косинусного сходства для частей «Истории готов, вандалов и свевов» в виде тепловой карты. Без использования статистической меры TF-IDF.
Для ещё большей наглядности проведем кластерный анализ документов на основании косинусного расстояния между векторами документов в латентно-семантическом пространстве. Кластеризация – это один из методов анализа, группирующий объекты на основании избранной меры сходства/различия в группы (кластеры) таким образом, чтобы объекты (в нашем случае документы – части «Истории готов, вандалов и свевов») внутри каждой группы были похожи друг на друга, а объекты из разных групп явно отличались [42, p. 385]. Для кластеризации предлагаем использовать один из наиболее распространенных методов – иерархическую кластеризацию, а конкретнее одну из её разновидностей – агломеративную кластеризацию. Она более всего подходит для небольшого числа анализируемых объектов и получаемых кластеров. Иерархическая кластеризация строит иерархию кластеров в виде перевернутого дерева – дендрограммы. В случае агломеративной кластеризации построение дендрограммы начинается снизу, с «листьев», соответствующих объектам в анализируемом наборе данных. На следующем шаге наиболее схожие между собой «листья» объединяются в кластеры и формируют «ветви» дендрограммы. Алгоритм повторяется до тех пор, пока все объекты не будут объединены в одном кластере – «стволе» дендрограммы [11, p. 67-68],[42, p. 390-391, 394]. Для кластеризации матрица косинусного сходства была преобразована в матрицу косинусного расстояния между документами, которая и была проанализирована с помощью функции hclust.
В результате была построена дендрограмма (см. рис. 5).
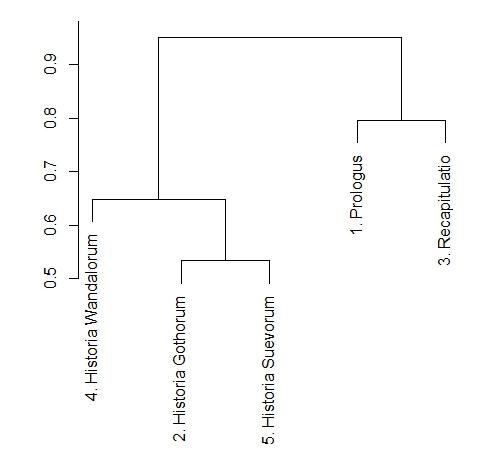
Рисунок 5. Иерархическая кластеризация фрагментов «Истории готов, вандалов и свевов» на основании косинусного расстояния между векторами документов в семантическом пространстве.
«Листья» в нижней части дендрограммы соответствую, анализируемым нами фрагментам «Истории готов, вандалов и свевов» Исидора Севильского. Учитывая особенности алгоритма иерархической кластеризации, можно утверждать, что чем ниже в структуре дендрограммы происходит слияние «листьев» и «ветвей», тем выше степень сходства между анализируемыми объектами. Если же объединение в один кластер происходит сравнительно высоко, вблизи от «ствола» дендрограммы, то в таком кластере могут быть объединены довольно непохожие друг на друга объекты [11, p. 99-102],[42, p. 391-392]. Мы видим, что на самом нижнем уровне в один кластер объединяются разделы, посвященный истории готов и свевов. Это свидетельствует об их максимальной схожести. Чуть выше с ними объединяется раздел, посвященный истории вандалов. Только значительно выше в один кластер объединяются «Пролог» и «Выводы» к истории готов
Выводы
Подводя итог, отметим, что проделанный латентно-семантический анализ латиноязычного текста хроники «История готов, вандалов и свевов» Исидора Севильского подтверждает гипотезу о выстраивании автором иерархии варварских народов. Расчет семантической близости разных разделов хроники демонстрирует наибольшее сходство между описаниями вестготов и свевов. Исидор Севильский излагает их историю, используя в описании похожие семантические структуры. Несколько особняком оказываются вандалы. Отметим, что к аналогичным результатам привело и проделанное нами ранее тематическое моделирование «История готов, вандалов и свевов» [43], показавшее совпадение преобладающих тем в разделах истории готов и свевов.
Библиография
1. Уколова В. И. Античное наследие и культура раннего средневековья (конец V-начало VII века). М., 1989. – 320 с.
2. Velázquez I. Pro patriae gentisqve Gothorvm statv (4th council of Toledo, Canon 75, A. 633) // Regna and Gentes: The Relationship between Late Antique and Early Medieval Peoples and Kingdoms in the Transformation of the Roman World / ed. by Goetz H.-W., Jarnut J., Pohl W. Leiden, Boston: Brill, 2003. P. 161-217.
3. Wood J. The Politics of Identity in Visigothic Spain. Religion and Power in the Histories of Isidore of Seville. Leiden, Boston: Brill, 2012. – 287 pp.
4. Марей Е. С. Феномен «вестготской симфонии» в 75-ом каноне IV-го Толедского собора 633 г. (к проблеме перехода к средневековой государственности) // Электронный научно-образовательный журнал «История». 2012. T. 3. Выпуск 3 (11) [Электронный ресурс]. Доступ для зарегистрированных пользователей. URL: https://history.jes.su/s207987840000372-8-1/ (дата обращения: 22.05.2020).
5. Сямтомов И. В. Понятие «Gens» и королевская власть в системе вестготского права (IV–VIII вв.) // Vox medii aevi. 2015. №2-3. С. 90-110.
6. Воронцов С. А. Wood J. The politics of identity in Visigothic Spain. Religion and power in the histories of Isidore of Seville. Brill, 2012 // Вестник ПСТГУ. Серия 1: Богословие. Философия. 2012. №42 (4). С. 125-131.
7. Kwartler T. Text mining in practice with R. New Jersey: John Wiley & Sons, 2017. – 320 pp.
8. Lane H., Howard C., Hapke H. Natural Language Processing in Action: Understanding, analyzing, and generating text with Python. Manning Publications Co., 2019. – 544 pp.
9. Sahlgren M. The Distributional Hypothesis. From context to meaning // Rivista di Linguistica. Vol. 20(1). 2008. Pp. 33–53.
10. Günther F., Dudschig C., Kaup B. LSAfun-An R package for computations based on Latent Semantic Analysis // Behavior Research Methods. Vol. 47. 2015. Pp. 930-944.
11. Anandarajan M., Hill C., Nolan T. Practical Text Analytics. Maximizing the Value of Text Data. (Advances in Analytics and Data Science. Vol. 2.) Springer, 2019. – 426 pp.
12. Коршунов А., Гомзин А. Тематическое моделирование текстов на естественном языке // Труды Института системного программирования РАН. Том 23, 2012. С. 215-244.
13. Sarkar D. Text Analytics with Python: A Practitioner's Guide to Natural Language Processing. Bangalore, 2019.
14. Deerwester S., Dumais S. T., Landauer T. K., Furnas G., Beck L. Improving Information Retrieval with Latent Semantic Indexing // Proceedings of the 51st Annual Meeting of the American Society for Information Science, 25, 1988. Pp. 36-40.
15. Deerwester S., Dumais S. T., Furnas, G. W., Landauer, T. K., Harshman, R. Indexing by Latent Semantic Analysis // Journal of the American Society for Information Science, 41, 1990. Pp. 391-407.
16. Dumais S.T. LSA and Information Retrieval: Getting Back to Basics // Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. Pp. 293-322.
17. Маннинг, К. Д., Рагхаван П., Шютце Х. Введение в информационный поиск. Москва: И. Д. Вильямс, 2011. – 528 с.
18. Dumais S., Nielsen J. Automating the assignment of submitted manuscripts to reviewers // SIGIR '92: Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval. Copenhagen, Denmark, June 21-24, 1992. Pp. 233–244.
19. Ozsoy M., Cicekli I., Alpaslan F. Text Summarization of Turkish Texts using Latent Semantic Analysis // COLING 2010, 23rd International Conference on Computational Linguistics, Proceedings of the Conference, 23-27 August 2010, Beijing, China. Vol. 2. Pp. 869-876.
20. Landauer T. K., Dumais S. T. A solution to Plato’s problem: The Latent Semantic Analysis theory of the acquisition, induction, and representation of knowledge // Psychological Review, 104(2), 1997. Pp. 211–240.
21. Величковский Б. М. Когнитивная наука. Основы психологии познания. Том II. Москва, 2006. – 448 с.
22. Landauer T. K. LSA as a Theory of Meaning // Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. Pp. 3-32.
23. Denhière G., Lemaire B., Bellissens C., Jhean-Larose S. A semantic space modeling children’s semantic memory // Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. P. 143-167.
24. Воронин В. М., Курицын С.В. Латентный семантический анализ и понимание текста // Психологический вестник Уральского государственного университета. Вып. 9. Екатеринбург, 2010. С. 15-27.
25. Кураленок И. Е., Некрестьянов И. С. Автоматическая классификация документов на основе латентно-семантического анализа // Труды первой всероссийской научно-методической конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». СПб, 1999. C. 89–96.
26. Kou G., Peng Y. An Application of Latent Semantic Analysis for Text Categorization // International Journal of Computers Communications & Control. 10(3). June, 2015. Pp. 357-369.
27. Краснов С. А., Илатовский А. С., Хомоненко А. Д., Арсеньев В. Н. Оценка семантической близости документов на основе латентно-семантического анализа с автоматическим выбором ранговых значений // Труды СПИИРАН. 2017. № 54 (5). C. 185-204.
28. Isidorus Hispalensis. Historia de regibus Gothorum, Wandalorum et Suevorum // Patrologiae Cursus Completus. Series Latina. Vol. 83. Paris: 1850. Col. 1057-1082.
29. Patrologia Latina Database [Электронный ресурс]. URL: http://pld.chadwyck.co.uk/ (дата обращения 22.05.2020).
30. Sancti Isidori Hispalensis Episcopi Historia de regibus Gothorum, Wandalorum et Suevorum [Электронный ресурс]. URL: https://www.thelatinlibrary.com/isidore/historia.shtml (дата обращения 22.05.2020).
31. Kuznetsov A. V. The computer analysis of Latin texts: Latent Semantic Analysis of «Historia de regibus Gothorum, Wandalorum et Suevorum» by Isidore of Seville [Электронный ресурс]. URL: https://github.com/alexeyvkuznetsov/Latin_Text_LSA/ (дата обращения 22.05.2020).
32. Gefen D., Endicott J. E., Fresneda J. E., Miller J., Larsen K. R. A Guide to Text Analysis with Latent Semantic Analysis in R with Annotated Code: Studying Online Reviews and the Stack Exchange Community // Communications of the Association for Information Systems. Vol. 41, Article 21. November 2017. Pp. 450-496.
33. Кузнецов А. В. Применения инструментов text mining для анализа средневековых латиноязычных текстов: предварительная обработка текстов // Научные исследования и разработки. Сборник научных работ 57й Международной научной конференции Евразийского Научного Объединения (г. Москва, ноябрь 2019). Москва: ЕНО, 2019. C. 68-70.
34. tm: Text Mining Package [Электронный ресурс]. URL: https://CRAN.R-project.org/package=tm (дата обращения 22.05.2020).
35. Natural Language Processing with R and UDPipe. Tokenization, Parts of Speech Tagging, Lemmatization, Dependency Parsing and NLP flows [Электронный ресурс]. URL: https://bnosac.github.io/udpipe/en/ (дата обращения 22.05.2020).
36. Perseus Stop Words. [Электронный ресурс]. URL: http://www.perseus.tufts.edu/hopper/stopwords/ (дата обращения 22.05.2020).
37. Dumais S. T. Improving the retrieval of information from external sources. // Behavior Research Methods, Instrumentation, and Computers, 23(2), 1991. Pp. 229-236.
38. Salton G., Buckley C. Term-weighting approaches in automatic text retrieval // Information Processing and Management, 24(5), 1988. Pp. 513-523.
39. Wild F. lsa: Latent Semantic Analysis. (R package version 0.73.2). [Электронный ресурс]. URL: https://CRAN.R-project.org/package=lsa (дата обращения 22.05.2020).
40. Martin D. I., Berry M. W. Mathematical foundations behind Latent Semantic Analysis Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. Pp. 35-56.
41. Turney P. D., Pantel P. From frequency to meaning: Vector space models of semantics // Journal of Artificial Intelligence Research, 37. March 2010. Pp. 141-188. 42. James G., Witten D., Hastie T., Tibshirani R. An Introduction to Statistical Learning with Applications in R. Springer, 2015.
42. James G., Witten D., Hastie T., Tibshirani R. An Introduction to Statistical Learning with Applications in R. Springer, 2015. – 440 pp.
43. Кузнецов А. В. Компьютерный анализ текстов на латинском языке: тематическое моделирование «Истории готов, вандалов и свевов» Исидора Севильского // Электронный научно-образовательный журнал «История». 2020. T. 11. Выпуск 3 (89) [Электронный ресурс]. Доступ для зарегистрированных пользователей. URL: https://history.jes.su/s207987840009681-8-1/ (дата обращения: 22.05.2020).
References
1. Ukolova V. I. Antichnoe nasledie i kul'tura rannego srednevekov'ya (konets V-nachalo VII veka). M., 1989. – 320 s.
2. Velázquez I. Pro patriae gentisqve Gothorvm statv (4th council of Toledo, Canon 75, A. 633) // Regna and Gentes: The Relationship between Late Antique and Early Medieval Peoples and Kingdoms in the Transformation of the Roman World / ed. by Goetz H.-W., Jarnut J., Pohl W. Leiden, Boston: Brill, 2003. P. 161-217.
3. Wood J. The Politics of Identity in Visigothic Spain. Religion and Power in the Histories of Isidore of Seville. Leiden, Boston: Brill, 2012. – 287 pp.
4. Marei E. S. Fenomen «vestgotskoi simfonii» v 75-om kanone IV-go Toledskogo sobora 633 g. (k probleme perekhoda k srednevekovoi gosudarstvennosti) // Elektronnyi nauchno-obrazovatel'nyi zhurnal «Istoriya». 2012. T. 3. Vypusk 3 (11) [Elektronnyi resurs]. Dostup dlya zaregistrirovannykh pol'zovatelei. URL: https://history.jes.su/s207987840000372-8-1/ (data obrashcheniya: 22.05.2020).
5. Syamtomov I. V. Ponyatie «Gens» i korolevskaya vlast' v sisteme vestgotskogo prava (IV–VIII vv.) // Vox medii aevi. 2015. №2-3. S. 90-110.
6. Vorontsov S. A. Wood J. The politics of identity in Visigothic Spain. Religion and power in the histories of Isidore of Seville. Brill, 2012 // Vestnik PSTGU. Seriya 1: Bogoslovie. Filosofiya. 2012. №42 (4). S. 125-131.
7. Kwartler T. Text mining in practice with R. New Jersey: John Wiley & Sons, 2017. – 320 pp.
8. Lane H., Howard C., Hapke H. Natural Language Processing in Action: Understanding, analyzing, and generating text with Python. Manning Publications Co., 2019. – 544 pp.
9. Sahlgren M. The Distributional Hypothesis. From context to meaning // Rivista di Linguistica. Vol. 20(1). 2008. Pp. 33–53.
10. Günther F., Dudschig C., Kaup B. LSAfun-An R package for computations based on Latent Semantic Analysis // Behavior Research Methods. Vol. 47. 2015. Pp. 930-944.
11. Anandarajan M., Hill C., Nolan T. Practical Text Analytics. Maximizing the Value of Text Data. (Advances in Analytics and Data Science. Vol. 2.) Springer, 2019. – 426 pp.
12. Korshunov A., Gomzin A. Tematicheskoe modelirovanie tekstov na estestvennom yazyke // Trudy Instituta sistemnogo programmirovaniya RAN. Tom 23, 2012. S. 215-244.
13. Sarkar D. Text Analytics with Python: A Practitioner's Guide to Natural Language Processing. Bangalore, 2019.
14. Deerwester S., Dumais S. T., Landauer T. K., Furnas G., Beck L. Improving Information Retrieval with Latent Semantic Indexing // Proceedings of the 51st Annual Meeting of the American Society for Information Science, 25, 1988. Pp. 36-40.
15. Deerwester S., Dumais S. T., Furnas, G. W., Landauer, T. K., Harshman, R. Indexing by Latent Semantic Analysis // Journal of the American Society for Information Science, 41, 1990. Pp. 391-407.
16. Dumais S.T. LSA and Information Retrieval: Getting Back to Basics // Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. Pp. 293-322.
17. Manning, K. D., Ragkhavan P., Shyuttse Kh. Vvedenie v informatsionnyi poisk. Moskva: I. D. Vil'yams, 2011. – 528 s.
18. Dumais S., Nielsen J. Automating the assignment of submitted manuscripts to reviewers // SIGIR '92: Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval. Copenhagen, Denmark, June 21-24, 1992. Pp. 233–244.
19. Ozsoy M., Cicekli I., Alpaslan F. Text Summarization of Turkish Texts using Latent Semantic Analysis // COLING 2010, 23rd International Conference on Computational Linguistics, Proceedings of the Conference, 23-27 August 2010, Beijing, China. Vol. 2. Pp. 869-876.
20. Landauer T. K., Dumais S. T. A solution to Plato’s problem: The Latent Semantic Analysis theory of the acquisition, induction, and representation of knowledge // Psychological Review, 104(2), 1997. Pp. 211–240.
21. Velichkovskii B. M. Kognitivnaya nauka. Osnovy psikhologii poznaniya. Tom II. Moskva, 2006. – 448 s.
22. Landauer T. K. LSA as a Theory of Meaning // Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. Pp. 3-32.
23. Denhière G., Lemaire B., Bellissens C., Jhean-Larose S. A semantic space modeling children’s semantic memory // Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. P. 143-167.
24. Voronin V. M., Kuritsyn S.V. Latentnyi semanticheskii analiz i ponimanie teksta // Psikhologicheskii vestnik Ural'skogo gosudarstvennogo universiteta. Vyp. 9. Ekaterinburg, 2010. S. 15-27.
25. Kuralenok I. E., Nekrest'yanov I. S. Avtomaticheskaya klassifikatsiya dokumentov na osnove latentno-semanticheskogo analiza // Trudy pervoi vserossiiskoi nauchno-metodicheskoi konferentsii «Elektronnye biblioteki: perspektivnye metody i tekhnologii, elektronnye kollektsii». SPb, 1999. C. 89–96.
26. Kou G., Peng Y. An Application of Latent Semantic Analysis for Text Categorization // International Journal of Computers Communications & Control. 10(3). June, 2015. Pp. 357-369.
27. Krasnov S. A., Ilatovskii A. S., Khomonenko A. D., Arsen'ev V. N. Otsenka semanticheskoi blizosti dokumentov na osnove latentno-semanticheskogo analiza s avtomaticheskim vyborom rangovykh znachenii // Trudy SPIIRAN. 2017. № 54 (5). C. 185-204.
28. Isidorus Hispalensis. Historia de regibus Gothorum, Wandalorum et Suevorum // Patrologiae Cursus Completus. Series Latina. Vol. 83. Paris: 1850. Col. 1057-1082.
29. Patrologia Latina Database [Elektronnyi resurs]. URL: http://pld.chadwyck.co.uk/ (data obrashcheniya 22.05.2020).
30. Sancti Isidori Hispalensis Episcopi Historia de regibus Gothorum, Wandalorum et Suevorum [Elektronnyi resurs]. URL: https://www.thelatinlibrary.com/isidore/historia.shtml (data obrashcheniya 22.05.2020).
31. Kuznetsov A. V. The computer analysis of Latin texts: Latent Semantic Analysis of «Historia de regibus Gothorum, Wandalorum et Suevorum» by Isidore of Seville [Elektronnyi resurs]. URL: https://github.com/alexeyvkuznetsov/Latin_Text_LSA/ (data obrashcheniya 22.05.2020).
32. Gefen D., Endicott J. E., Fresneda J. E., Miller J., Larsen K. R. A Guide to Text Analysis with Latent Semantic Analysis in R with Annotated Code: Studying Online Reviews and the Stack Exchange Community // Communications of the Association for Information Systems. Vol. 41, Article 21. November 2017. Pp. 450-496.
33. Kuznetsov A. V. Primeneniya instrumentov text mining dlya analiza srednevekovykh latinoyazychnykh tekstov: predvaritel'naya obrabotka tekstov // Nauchnye issledovaniya i razrabotki. Sbornik nauchnykh rabot 57i Mezhdunarodnoi nauchnoi konferentsii Evraziiskogo Nauchnogo Ob''edineniya (g. Moskva, noyabr' 2019). Moskva: ENO, 2019. C. 68-70.
34. tm: Text Mining Package [Elektronnyi resurs]. URL: https://CRAN.R-project.org/package=tm (data obrashcheniya 22.05.2020).
35. Natural Language Processing with R and UDPipe. Tokenization, Parts of Speech Tagging, Lemmatization, Dependency Parsing and NLP flows [Elektronnyi resurs]. URL: https://bnosac.github.io/udpipe/en/ (data obrashcheniya 22.05.2020).
36. Perseus Stop Words. [Elektronnyi resurs]. URL: http://www.perseus.tufts.edu/hopper/stopwords/ (data obrashcheniya 22.05.2020).
37. Dumais S. T. Improving the retrieval of information from external sources. // Behavior Research Methods, Instrumentation, and Computers, 23(2), 1991. Pp. 229-236.
38. Salton G., Buckley C. Term-weighting approaches in automatic text retrieval // Information Processing and Management, 24(5), 1988. Pp. 513-523.
39. Wild F. lsa: Latent Semantic Analysis. (R package version 0.73.2). [Elektronnyi resurs]. URL: https://CRAN.R-project.org/package=lsa (data obrashcheniya 22.05.2020).
40. Martin D. I., Berry M. W. Mathematical foundations behind Latent Semantic Analysis Handbook of Latent Semantic Analysis. / ed. by: Landauer T. K., McNamara D. S., Dennis S., Kintsch, W. Mahwah, New Jersey: Erlbaum. 2007. Pp. 35-56.
41. Turney P. D., Pantel P. From frequency to meaning: Vector space models of semantics // Journal of Artificial Intelligence Research, 37. March 2010. Pp. 141-188. 42. James G., Witten D., Hastie T., Tibshirani R. An Introduction to Statistical Learning with Applications in R. Springer, 2015.
42. James G., Witten D., Hastie T., Tibshirani R. An Introduction to Statistical Learning with Applications in R. Springer, 2015. – 440 pp.
43. Kuznetsov A. V. Komp'yuternyi analiz tekstov na latinskom yazyke: tematicheskoe modelirovanie «Istorii gotov, vandalov i svevov» Isidora Sevil'skogo // Elektronnyi nauchno-obrazovatel'nyi zhurnal «Istoriya». 2020. T. 11. Vypusk 3 (89) [Elektronnyi resurs]. Dostup dlya zaregistrirovannykh pol'zovatelei. URL: https://history.jes.su/s207987840009681-8-1/ (data obrashcheniya: 22.05.2020).
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Выдающийся русский литературный критик В.Г. Белинский справедливо отмечал, что «русская история есть неисчислимый источник для каждого драматика и трагика». Сказанное с той же равной долей вероятности относится и к истории зарубежной. Заметим, что в конце 1980-х годов в нашей стране на волне демократизации и гласности, с одной стороны, наметился интерес к родной и всемирной истории, с другой стороны, этот процесс на фоне растущей вседозволенности не мог не привести к целому валу псевдоисторических работ, главной целью которых выступала коммерческая привлекательность. В этой связи крайне важным является обращение к первоисточникам, то есть к трудам таких историков, как Тит Ливий, Иосиф Флавий, Григорий Турский и др., а также их грамотный профессиональный анализ, что сегодня возможно, в том числе, с использованием современных компьютерных технологий.
Указанные обстоятельства определяют актуальность представленной на рецензирование статьи, предметом которой является интеллектуальный анализ текстов Исидора Севильского. Автор ставит своими задачами раскрыть роль и значение Исидора Севильского в средневековой историографии, а, главное, осуществить латентно-семантический анализ «Истории готов, вандалов и свевов» Исидора Севильского.
Работа основана на принципах системности, объективности, достоверности, методологической базой исследования выступает латентно-систематический анализ, который, как отмечает автор рецензируемой статьи, «был и остается одним из наиболее эффективных методов классификации и индексации текстов, оценки их семантической близости».
Научная новизна статьи заключается в самой постановке темы: автор на основе компьютерного анализа хроники Исидора Севильского хроники «История готов, вандалов и свевов» стремится доказать гипотезу о выстраивании средневековым историком иерархии варварских народов.
Анализируя библиографический список статьи, как позитивный момент следует отметить его масштабность и разносторонность: всего список литературы включает в себя 43 различных источников и исследований, что уже говорит о той масштабной работе, которая проделана ее автором. Несомненным достоинством рецензируемой статьи является также значительный массив привлекаемой зарубежной литературы, в том числе на английском и латинском языках. Помимо собственно анализируемого труда Исидора Севильского автор привлекает также работы, в которых рассматриваются различные аспекты истории раннего средневековья (В.И. Уколова, Е.С. Марей, С.А. Воронцов, И.В. Сямтомов), а также работы, служащие фундаментом в выработке методологии исследования (Б.М. Величковский, В.М. Воронин, С.В. Курицын, И.Е. Кураленок, И.С. Некрестьянов). Заметим, что библиография статьи обладает важностью как с научной, так и с просветительской точки зрения: после прочтения текста читатели могут обратиться к другим материалам по ее теме. Таким образом, на наш взгляд, комплексное использование различных источников и исследований позволило автору должным образом раскрыть поставленную тему.
Стиль написания статьи можно отнести к научному, вместе с тем доступному для понимания не только специалистам, но и широкому кругу читателей: всех, кто интересуется как изучением текстов средневековых хронистов, так и современными компьютерными методами при их анализе. Аппеляция к оппонентам представлена на уровне собранной информации, полученной автором в ходе работы над темой статьи.
Структура работы отличается определённой логичностью и последовательностью: в ней можно выделить введение, основную часть, которая разделена на методологию, где раскрывается смысл латентно-семантического анализа, и экспериментальный раздел, заключение. В начале автор определяет актуальность темы, показывает, что он стремится «глубже понять отношение Исидора к трем варварским народам, раскрыть неявные идеи и смыслы, содержащиеся в «Истории готов, вандалов и свевов», используя метод латентно-семантического анализа – один из методов интеллектуального анализа текстов». Автор выделяет пять этапов при латентно-семантическом анализе труда Исидора Севильского и даёт характеристику каждой: это «1) предварительная обработка текста; 2) создание терм-документной матрицы из набора документов; 3) взвешивание термов в терм-документной матрице; 4) создание семантического пространства набора документов; 5) сравнение векторов термов или документов в латентном семантическом пространстве, путем вычисления косинуса угла между векторами или другим методом». При этом сам труд Исидора Севильского в рамках анализа был разделён на 5 частей: «Пролог», «Историю готов», «Выводы», «Историю вандалов», «Историю свевов». Примечательно, что как отмечается в работе, проведённый автором «расчёт семантической близости разных разделов хроники демонстрирует наибольшее сходство между описаниями вестготов и свевов», в то время как несколько иначе описаны вандалы.
Главным выводом статьи является то, что «анализ латиноязычного текста хроники «История готов, вандалов и свевов» Исидора Севильского подтверждает гипотезу о выстраивании автором иерархии варварских народов».
Представленная на рецензирование статья посвящена актуальной теме, снабжена 2 таблицами и 5 рисунками, а ее материалы могут быть использованы как в курсах лекций по истории средних веков, так и в различных спецкурсах, в том числе в рамках исторической информатики.
Проделанное автором масштабное исследование отвечает всем требованиям, предъявляемым к подобного рода работам, и, на наш взгляд, может быть рекомендовано для публикации в журнале «Историческая информатика».
Ссылка на эту статью
Просто выделите и скопируйте ссылку на эту статью в буфер обмена. Вы можете также
попробовать найти похожие
статьи
|
|




